Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient报错,问题排查
背景
最近在整合pyspark与hive,新安装spark-2.3.3以客户端的方式访问hive数据,运行方式使用spark on yarn,但是在配置spark读取hive数据的时候,这里直接把hive下的hive-site.xml复制到spark目录下,启动了一次spark,上面的问题就出现了。
网上的说法:
hive元数据问题,需要重新初始化hive的元数据
但是这个方法肯定不适合我,因为仓库里的表不能受影响,上千张表呢,如果初始化了,所有表都要重新创建。
排查过程
* 首先查看服务器上/tmp/${user}/hive.log文件,这个是公司服务器当时配置的详细的hive执行日志。
在日志中,有一段报错:
2019-07-06T10:01:53,737 ERROR [370c0a81-c922-4c61-8315-264c39b372c3 main] metastore.RetryingHMSHandler: MetaException(message:Hive Schema version 3.1.0 does not match metastore's schema version 1.2.0 Metastore is not upgraded or corrupt)
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:9063)
at org.apache.hadoop.hive.metastore.ObjectStore.verifySchema(ObjectStore.java:9027)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
这里的意思是,hive的版本是3.1.0,但是元数据中的版本信息是1.2.0,因此报错。
* 到hive的元数据库里查了下version表里的数据,确实版本是1.2.0
问题原因
这里猜测,spark在读取hive元数据的时候,因为spark是直接从官网上下载的,可能官网上的spark是用hive1.2.0版本编译的,所以,它默认使用的1.2.0,导致在启动的时候,修改了hive的元数据
但是具体的原因还不知道
下面会拿官网上的spark源码手动编译测试一下
解决办法
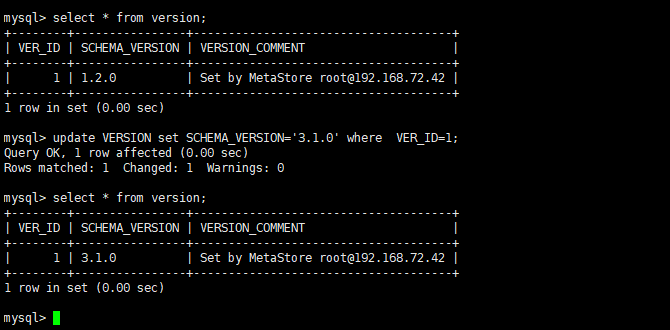
- 直接修改version表的数据
select * from version;
update VERSION set SCHEMA_VERSION='2.1.1' where VER_ID=1;
2、在hvie-site.xml中关闭版本验证
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
深入研究
在spark官网上查看了相关的资料,发现,在官网上下载的spark安装包,默认编译的hive版本是1.2.1的,所以每次启动spark的时候,会检查hive的版本。如果采用hive的默认配置,如果不一样,
就会修改version

一开始尝试着下载spark源码重新编译spark安装包,编译执行hive的版本为3.1.1,但是,发现每次指定hive的版本,maven下载依赖的时候,都会报错。
报错信息如下:
后来想了个折中的办法,spark还是使用原始版本,但是修改一下hive-site.xml文件。
注意:这里修改的是spark的conf下的hive-site.xml,原始的hive里的不需要修改
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
<property>
<name>hive.metastore.schema.verification.record.version</name>
<value>false</value>
<description>
When true the current MS version is recorded in the VERSION table. If this is disabled and verification is
enabled the MS will be unusable.
</description>
</property>
这两个配置,hive.metastore.schema.verification如果设置为true,那么每次启动hive或者spark的时候,都会检查hive的版本。为false,则会告警
hive.metastore.schema.verification.record.version如果设置为true,每次启动spark的时候,如果检查了hive的版本和spark编译的版本不一致,那么就会修改hive的元数据
这里的修改需要设置hive.metastore.schema.verification=false 且hive.metastore.schema.verification.record.version=false
如过这两个都为true,那么spark会修改hive元数据
如果hive.metastore.schema.verification=true,并且hive.metastore.schema.verification.record.version=false,这时候启动spark就会报错:
Caused by: MetaException(message:Hive Schema version 1.2.0 does not match metastore's schema version 3.1.0 Metastore is not upgraded or corrupt)
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:6679)
at org.apache.hadoop.hive.metastore.ObjectStore.verifySchema(ObjectStore.java:6645)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
如果设置hive.metastore.schema.verification=false 且hive.metastore.schema.verification.record.version=true,spark还是会修改hive的元数据


所以,只要设置hive.metastore.schema.verification.record.version=false就可以了,但是为了保险起见,我两个都设置成false了
Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient报错,问题排查的更多相关文章
- Hive之FAILED: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient异常
一.场景 Hive启动不报错,当使用show functions;或create table...时报:FAILED: SemanticException org.apache.hadoop.hive ...
- hive Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
Exception in thread "main" java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata. ...
- Hive2:Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
[root@node1 ~]# hive which: no hbase in (/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bi ...
- hive 2以上版本启动异常 Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
hive2.0以上的版本启动时 抛出 “Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreCli ...
- Have启动报错:java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
错误日志如下: [hadoop@master hive1.0.0]$ bin/hive Logging initialized using configuration in file:/opt/mod ...
- Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
1.今天在进行hive测试的时候,发现hive一直进不去,并且报了这个错误. Unable to instantiate org.apache.hadoop.hive.ql.metadata.Sess ...
- Hive启动后show tables报错:Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
错误详情: FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive ...
- Hive 报错:java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
在配置好hive后启动报错信息如下: [walloce@bigdata-study- hive--cdh5.3.6]$ bin/hive Logging initialized using confi ...
- java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
1.启动hive的时候出现这个问题,报错如下所示: [hadoop@slaver1 conf]$ hive Logging initialized -cdh5.-cdh5.3.6.jar!/hive- ...
随机推荐
- 移动端 - adb shell常见问题汇总
一.如何执行adb命令? 答:如果没有配置SDK的环境变量的话,那就先用cd命令进入adb所在文件目录(即F:\android-sdk-windows\platform-tools)后,再执行adb命 ...
- arcpy实例教程-上游流域下游流域查找
arcpy实例教程-上游流域下游流域查找 商务合作,科技咨询,版权转让:向日葵,135-4855_4328,xiexiaokui#qq.com 功能:对于选定某一流域,查找其直接(一次)的上游流域和下 ...
- Android: 判断当前手机品牌(转)
参考资料 Android判断手机ROM 正文 有时候需要判断手机系统的ROM,检测ROM是MIUI.EMUI还是Flyme,可以使用getprop命令,去系统build.prop文件查找是否有对应属性 ...
- js实现字符串切割并转换成对象格式保存到本地
// split() 将字符串按照指定的规则分割成字符串数组,并返回此数组(字符串转数组的方法) //分割字符串 var bStr = "www.baidu.con"; var a ...
- Wise Force Deleter 强制删除文件工具
https://www.xitmi.com/3321.html Wise Force Deleter v1.49 中文绿色版 强制删除文件工具
- Java 使用ZkClient操作Zookeeper
目录 ZkClient介绍 导入jar包依赖 简单使用样例 ZkClient介绍 因为Zookeeper API比较复杂,使用并不方便,所以出现了ZkClient,ZkClient对Zookeeper ...
- 筛选出dataframe中全为数字的列的值
In [1]: import pandas as pd In [2]: import numpy as np In [3]: students = [ ('jack', 'Apples' , 34) ...
- [Kaggle] Online Notebooks
前言 Let's go to https://www.kaggle.com/ Kaggle Notebook 有实践记录的案例. 一.线性拟合噪声数据 [Sklearn] Linear regress ...
- Android 调试桥介绍 (adb)
Android 调试桥 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信.它可为各种设备操作提供便利,如安装和调试 ...
- 使用 Fiddler 代理调试本地手机页面
文件下载:http://files.cnblogs.com/files/dtdxrk/fiddler4_4.6.2.0_setup.rar 从事前端开发的同学一定对 Fiddler 不陌生,它是一个非 ...