Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient报错,问题排查
背景
最近在整合pyspark与hive,新安装spark-2.3.3以客户端的方式访问hive数据,运行方式使用spark on yarn,但是在配置spark读取hive数据的时候,这里直接把hive下的hive-site.xml复制到spark目录下,启动了一次spark,上面的问题就出现了。
网上的说法:
hive元数据问题,需要重新初始化hive的元数据
但是这个方法肯定不适合我,因为仓库里的表不能受影响,上千张表呢,如果初始化了,所有表都要重新创建。
排查过程
* 首先查看服务器上/tmp/${user}/hive.log文件,这个是公司服务器当时配置的详细的hive执行日志。
在日志中,有一段报错:
2019-07-06T10:01:53,737 ERROR [370c0a81-c922-4c61-8315-264c39b372c3 main] metastore.RetryingHMSHandler: MetaException(message:Hive Schema version 3.1.0 does not match metastore's schema version 1.2.0 Metastore is not upgraded or corrupt)
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:9063)
at org.apache.hadoop.hive.metastore.ObjectStore.verifySchema(ObjectStore.java:9027)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
这里的意思是,hive的版本是3.1.0,但是元数据中的版本信息是1.2.0,因此报错。
* 到hive的元数据库里查了下version表里的数据,确实版本是1.2.0
问题原因
这里猜测,spark在读取hive元数据的时候,因为spark是直接从官网上下载的,可能官网上的spark是用hive1.2.0版本编译的,所以,它默认使用的1.2.0,导致在启动的时候,修改了hive的元数据
但是具体的原因还不知道
下面会拿官网上的spark源码手动编译测试一下
解决办法
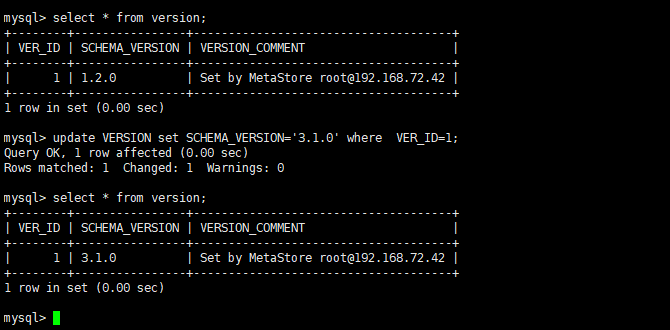
- 直接修改version表的数据
select * from version;
update VERSION set SCHEMA_VERSION='2.1.1' where VER_ID=1;
2、在hvie-site.xml中关闭版本验证
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
深入研究
在spark官网上查看了相关的资料,发现,在官网上下载的spark安装包,默认编译的hive版本是1.2.1的,所以每次启动spark的时候,会检查hive的版本。如果采用hive的默认配置,如果不一样,
就会修改version

一开始尝试着下载spark源码重新编译spark安装包,编译执行hive的版本为3.1.1,但是,发现每次指定hive的版本,maven下载依赖的时候,都会报错。
报错信息如下:
后来想了个折中的办法,spark还是使用原始版本,但是修改一下hive-site.xml文件。
注意:这里修改的是spark的conf下的hive-site.xml,原始的hive里的不需要修改
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
<property>
<name>hive.metastore.schema.verification.record.version</name>
<value>false</value>
<description>
When true the current MS version is recorded in the VERSION table. If this is disabled and verification is
enabled the MS will be unusable.
</description>
</property>
这两个配置,hive.metastore.schema.verification如果设置为true,那么每次启动hive或者spark的时候,都会检查hive的版本。为false,则会告警
hive.metastore.schema.verification.record.version如果设置为true,每次启动spark的时候,如果检查了hive的版本和spark编译的版本不一致,那么就会修改hive的元数据
这里的修改需要设置hive.metastore.schema.verification=false 且hive.metastore.schema.verification.record.version=false
如过这两个都为true,那么spark会修改hive元数据
如果hive.metastore.schema.verification=true,并且hive.metastore.schema.verification.record.version=false,这时候启动spark就会报错:
Caused by: MetaException(message:Hive Schema version 1.2.0 does not match metastore's schema version 3.1.0 Metastore is not upgraded or corrupt)
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:6679)
at org.apache.hadoop.hive.metastore.ObjectStore.verifySchema(ObjectStore.java:6645)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
如果设置hive.metastore.schema.verification=false 且hive.metastore.schema.verification.record.version=true,spark还是会修改hive的元数据


所以,只要设置hive.metastore.schema.verification.record.version=false就可以了,但是为了保险起见,我两个都设置成false了
Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient报错,问题排查的更多相关文章
- Hive之FAILED: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient异常
一.场景 Hive启动不报错,当使用show functions;或create table...时报:FAILED: SemanticException org.apache.hadoop.hive ...
- hive Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
Exception in thread "main" java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata. ...
- Hive2:Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
[root@node1 ~]# hive which: no hbase in (/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bi ...
- hive 2以上版本启动异常 Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
hive2.0以上的版本启动时 抛出 “Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreCli ...
- Have启动报错:java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
错误日志如下: [hadoop@master hive1.0.0]$ bin/hive Logging initialized using configuration in file:/opt/mod ...
- Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
1.今天在进行hive测试的时候,发现hive一直进不去,并且报了这个错误. Unable to instantiate org.apache.hadoop.hive.ql.metadata.Sess ...
- Hive启动后show tables报错:Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
错误详情: FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive ...
- Hive 报错:java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
在配置好hive后启动报错信息如下: [walloce@bigdata-study- hive--cdh5.3.6]$ bin/hive Logging initialized using confi ...
- java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
1.启动hive的时候出现这个问题,报错如下所示: [hadoop@slaver1 conf]$ hive Logging initialized -cdh5.-cdh5.3.6.jar!/hive- ...
随机推荐
- (一)Cisco DHCP Snooping原理(转载)
采用DHCP服务的常见问题架设DHCP服务器可以为客户端自动分配IP地址.掩码.默认网关.DNS服务器等网络参数,简化了网络配置,提高了管理效率.但在DHCP服务的管理上存在一些问题,常见的有: ●D ...
- Linux 磁盘的分区
如果我们想在系统中新增一块硬盘,需要做什么呢? 1. 对磁盘进行分区,新建可用分区 2. 对该分区进行格式化,以创建系统可用的文件系统 3. 若想要仔细一点,可以对刚才新建好的文件系统进行检验 4. ...
- 单细胞数据整合方法 | Comprehensive Integration of Single-Cell Data
操作代码:https://satijalab.org/seurat/ 依赖的算法 CCA CANONICAL CORRELATION ANALYSIS | R DATA ANALYSIS EXAMPL ...
- 【mybatis源码学习】mybatis的插件功能
一.mybatis的插件功能可拦截的目标 org.apache.ibatis.executor.parameter.ParameterHandler org.apache.ibatis.executo ...
- k8s 新加节点
拷贝原来的内容过去,删除 cd /opt/kubernetes/ssl/ 1. 删除 kubelet-crt key kube-proxy-key.pem 相关的这些key是,根据too ...
- Jenkins参数化构建--Git Parameter
由于我们在测试过程中,可能需要在多个测试环境跑用例,这个时候就需要jenkins参数化了. Jenkins参数化一般常用的有两种方式:Choice和String Parameter两种 (1)Choi ...
- RFC2119 规范内容
RFC2119 https://www.ietf.org/rfc/rfc2119.txt Network Working Group S. Bradner Request for Comments: ...
- 简单的 js 模版引擎
简单的 js 模版引擎 var tplEngine = function(tpl, data) { var reg = /<%([^%>]+)?%>/g, regOut = /(^( ...
- 接口测试01- Jmeter-线程进程-环境变量
1.1 概念 JMeter 是 Apache 组织使用 Java 开发的一款测试工具 ,它最初被设计用于Web应用测试,但后来扩展到其他测试领域. 它可以用于测试静态和动态资源,例如静态文件.Java ...
- Android 调试桥介绍 (adb)
Android 调试桥 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信.它可为各种设备操作提供便利,如安装和调试 ...