python 排序 归并排序
算法思想
迭代法:
def merge_sort5(collection):
length=len(collection)
#定义合并数组函数,参数是两个数组,返回一个包含两个数组的结果集
def merge(collection1,collection2):#数组长度可能不相等
result=[]
while collection1 and collection2:
# while len(collection1)>=1 and len(collection2)>=1:#不要这样写
result.pop(collection1.pop(0) if collection1[0]<=collection2[0] else collection2.pop(0))
# result.append(collection1.pop(0)) if collection1[0]<=collection2[0] else result.append(collection2.pop(0))
return result+collection1+collection2#比下面的好
# result.extend(collection1+collection2)
# return result
temps=[pow(2,i) for i in range(15)]
#定义存放根据步长切分后多余的,当有多余的让他和前面多余的进行合并
superfluous=[]
for temp in temps:
flage=True
left_index=-1
while left_index+2*temp<length:#减一是因为截取的时候不到右边
#这里可能会出错哦
flage=False
collection[left_index+1:left_index+2*temp+1]=merge(collection[left_index+1:left_index+temp+1],collection[left_index+temp+1:left_index+2*temp+1])
left_index+=2*temp
superfluous=merge(superfluous,collection[left_index+1:])#将多余的放到这里,当有新的多余的和老的合并
del(collection[left_index+1:])
if flage:
break
return superfluous
算法分析:稳定排序,需要O(n)额外空间、时间复杂度(一共有log(2,N)次外循环,内层循环分别为(n/1,n/2,n/4....n/temp)而(每次内循环中的归并操作的时间复杂度都是temp,)所有内层循环的时间复杂度是N(即n/temp*temp)所以T(n)=nlog(2,n),根据换地公式,log(2,n)=log(1,n)/log(1,2),考虑到取同数量级时不考虑系数,所以T(n)=O(nlogn)
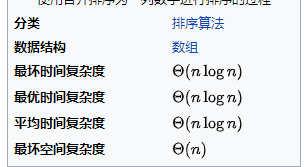
比较
仍然没有快排快:随机数据 时间是快排的两倍
(sort) λ python some_sort.py
详细数据:[0.00100016594, 0.00299906731, 0.00100016594, 0.00299859047, 0.00100040436, 0.00299811363, 0.00199818611, 0.00199770927, 0.00200009346, 0.00199866295, 0.00199770927, 0.00099945068, 0.00200
009346, 0.00099825859, 0.0019993782, 0.0030002594, 0.00099873543, 0.00199723244, 0.00100016594, 0.00199866295, 0.00199818611, 0.00099897385, 0.00299787521, 0.00100016594, 0.00199890137, 0.0009996891, 0.00199961662, 0.00099992752, 0.00199794769, 0.00099301338, 0.00299859047, 0.00099921227, 0.0019993782, 0.00099992752, 0.00199961662, 0.00199913979, 0.00100040436, 0.0019993782, 0.0009996891, 0.00199961662, 0.00199842453, 0.00099873543, 0.0029976368, 0.00100016594, 0.00299835205, 0.00099921227, 0.00299882889, 0.0009996891, 0.00299835205, 0.00200009346, 0.00199985504, 0.00299835205, 0.0009996891, 0.00199866295, 0.00199961662, 0.00299930573, 0.00099873543, 0.00199985504, 0.00301456451, 0.00099849701, 0.00299859047, 0.00099825859, 0.00200128555, 0.00199866295, 0.0009996891, 0.00199723244, 0.00199913979, 0.00199866295, 0.00100016594, 0.00199961662, 0.00099992752, 0.00199842453, 0.00099921227, 0.00199842453, 0.00099897385, 0.00199890137, 0.00199866295, 0.00199866295, 0.00099921227, 0.00199985504, 0.00099873543, 0.00199913979, 0.00099945068, 0.00199890137, 0.00299787521, 0.00199866295, 0.00199818611, 0.00099992752, 0.00199818611, 0.00099921227, 0.00199866295, 0.00099992752, 0.00199794769, 0.00100040436, 0.00299906731, 0.00099992752, 0.00199818611, 0.00099945068, 0.00199866295, 0.00099992752]
运行了100次,平均运行时间差(me-other)/(bubble-quick)(正数代表你是个弟弟)是:0.00176918983
前者(插入排序)平均运行时间0.00361800909,后者(快排)平均运行时间0.00184881926,前者约是后者的1.9569倍
比插入快一个数量级:
详细数据:[-0.02898788452, -0.02898383141, -0.02898526192, -0.02896666527, -0.02997136116, -0.02898812294, -0.02801847458, -0.02900123596, -0.02998185158, -0.02995634079, -0.02994823456, -0.02992892
265, -0.02899622917, -0.10892653465, -0.03997755051, -0.02798676491, -0.02946019173, -0.02899646759, -0.02998185158, -0.02795672417, -0.02894616127, -0.03098273277, -0.02894926071, -0.02896404266, -0.02900695801, -0.02801513672, -0.02901649475, -0.02798366547, -0.09094834328, -0.04997181892, -0.02819728851, -0.02898263931, -0.02879166603, -0.02898216248, -0.02898240089, -0.02900052071, -0.02798342705, -0.02898788452, -0.03598976135, -0.02799391747, -0.0279853344, -0.02898383141, -0.02896499634, -0.02799677849, -0.03098726273, -0.02698349953, -0.02898192406, -0.02800416946, -0.02898788452, -0.02897882462, -0.02699589729, -0.02898049355, -0.02898478508, -0.02797055244, -0.03001332283, -0.02898716927, -0.02798342705, -0.02899360657, -0.02898335457, -0.02797985077, -0.02797579765, -0.02797961235, -0.02798891068, -0.02898812294, -0.02796649933, -0.02997922897, -0.02796721458, -0.02697610855, -0.02898406982, -0.02798390388, -0.02801299095, -0.02999520302, -0.03098082542, -0.0290017128, -0.02898097038, -0.02995085716, -0.02899312973, -0.02798342705, -0.02799725533, -0.02898263931, -0.02898335457, -0.02794861794, -0.03400492668, -0.03496909142, -0.03293538094, -0.03296351433, -0.03296232224, -0.02998614311, -0.02898216248, -0.02798914909, -0.02898836136, -0.02896380424, -0.02897286415, -0.03096866608, -0.02999520302, -0.02998280525, -0.02898335457, -0.03000807762, -0.02799677849, -0.03100776672]
运行了100次,平均运行时间差(me-other)/(bubble-quick)(正数代表你是个弟弟)是:-0.03094664574
前者(归并迭代法排序)平均运行时间0.00373820066,后者(快排)平均运行时间0.03468484640,前者约是后者的0.1078倍
递归法
def merge_sort6(collection):
'''自己写的(递归法)'''
#巧妙之处在于要想到能把merge和merge_sort6结合起来递归,思考的线索是根据参数的格式
def merge(left,right):
result=[]
while left and right:
result.append(left.pop(0) if left[0]<=right[0] else right.pop(0))
return result+left+right
#递归
length=len(collection)
if length==1:
return collection
while True:
mid=length//2
return(merge(merge_sort6(collection[:mid]),merge_sort6(collection[mid:])))
对比
与采用迭代法的相比,速度慢了一半,但胜在代码简单
详细数据:[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0009996891, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0009996891, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, -0.00099945068, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
运行了100次,平均运行时间差(me-other)/(bubble-quick)(正数代表你是个弟弟)是:0.00000999928
前者(归并迭代法排序)平均运行时间0.00001999378,后者(递归法)平均运行时间0.00000999451,前者约是后者的2.0005倍
python 排序 归并排序的更多相关文章
- Python排序搜索基本算法之归并排序实例分析
Python排序搜索基本算法之归并排序实例分析 本文实例讲述了Python排序搜索基本算法之归并排序.分享给大家供大家参考,具体如下: 归并排序最令人兴奋的特点是:不论输入是什么样的,它对N个元素的序 ...
- python实现归并排序,归并排序的详细分析
python实现归并排序,归并排序的详细分析. 学习归并排序的过程是十分痛苦的.它并不常用,看起来时间复杂度好像是几种排序中最低的,比快排的时间复杂度还要低,但是它的执行速度不是最快的.很多朋友不 ...
- python 排序算法总结及实例详解
python 排序算法总结及实例详解 这篇文章主要介绍了python排序算法总结及实例详解的相关资料,需要的朋友可以参考下 总结了一下常见集中排序的算法 排序算法总结及实例详解"> 归 ...
- 带你掌握4种Python 排序算法
摘要:在编程里,排序是一个重要算法,它可以帮助我们更快.更容易地定位数据.在这篇文章中,我们将使用排序算法分类器对我们的数组进行排序,了解它们是如何工作的. 本文分享自华为云社区<Python ...
- python排序之二冒泡排序法
python排序之二冒泡排序法 如果你理解之前的插入排序法那冒泡排序法就很容易理解,冒泡排序是两个两个以向后位移的方式比较大小在互换的过程好了不多了先上代码吧如下: 首先还是一个无序列表lis,老规矩 ...
- python排序之一插入排序
python排序之一插入排序 首先什么是插入排序,个人理解就是拿队列中的一个元素与其之前的元素一一做比较交根据大小换位置的过程好了我们先来看看代码 首先就是一个无序的列表先打印它好让排序后有对比效果, ...
- 用 Python 排序数据的多种方法
用 Python 排序数据的多种方法 目录 [Python HOWTOs系列]排序 Python 列表有内置就地排序的方法 list.sort(),此外还有一个内置的 sorted() 函数将一个可迭 ...
- python排序算法实现(冒泡、选择、插入)
python排序算法实现(冒泡.选择.插入) python 从小到大排序 1.冒泡排序: O(n2) s=[3,4,2,5,1,9] #count = 0 for i in range(len(s)) ...
- Python排序算法之选择排序定义与用法示例
Python排序算法之选择排序定义与用法示例 这篇文章主要介绍了Python排序算法之选择排序定义与用法,简单描述了选择排序的功能.原理,并结合实例形式分析了Python定义与使用选择排序的相关操作技 ...
随机推荐
- 五、select的5种子句
1.Where 条件查询 比较运算符: 运算符 说明 > < = >= <= !=或<> In 在某集合内 between 在某范围内 In ...
- Java后端面经总结:拿下蚂蚁金服美团头条 offer 秘诀
笔者在面过 猿辅导,去哪儿,旷视, 陌陌,头条, 阿里, 快手, 美团, 腾讯之后,除了收获一大堆面试问题,还思考到如何成为面试官眼中的”爱技术,爱思考,靠谱,有潜力候选人的”一些”套路”. 面试问题 ...
- Rust自定义智能指针
深了,真深了. use std::ops::Deref; struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) - ...
- CentOS7创建启动脚本
文件内容解释 [Unit]:服务的说明 Description:描述服务 After:描述服务类别 [Service]服务运行参数的设置 Type=forking是后台运行的形式 ExecStart为 ...
- 代码审计-strpos数组绕过
<?php $flag = "flag"; if (isset ($_GET['ctf'])) { if (@ereg ("^[1-9]+$", $_GE ...
- Android TextField : set focus + soft input programmatically
Good sir, try this: edittext.setFocusableInTouchMode(true); edittext.requestFocus(); Im not sure, bu ...
- redis 在 windows 中的安装
redis 在 windows 中的安装 redis 官方并没有提供 redis 的 windows 版本.但是微软提供了 redis 的 windows 版本.有2.8和3.0版本.3.0版本支持集 ...
- [LeetCode] 222. Count Complete Tree Nodes 求完全二叉树的节点个数
Given a complete binary tree, count the number of nodes. Note: Definition of a complete binary tree ...
- oracle--10.2.0.3升级到11.2.0.4
一,环境 01,待升级的系统 升级仅支持10.2.0.2版本之后的系统,如果不是,请把10G升级至高版本! 本次实验环境10.2.0.3 02,挂载11G系统 03,升级须知 1) 做好备份 二,DB ...
- Docker下构建centos7容器无法使用systemctl命令的解决办法
最近在使用docker 构建centos7 容器时,发现无法使用systemctl 命令.后来万能的百度解决了问题,随记之以备后用. 解决办法: docker run --privileged -it ...