一个初学者的辛酸路程-了解Python-2
前言
blog花了一上午写的,结果笔记本关机了,没有保存,找不到了,找不到了啊,所以说,你看的每一篇blog可能都是我写了2次以上的…….哎!!
代码改变世界,继续.........
Python基础
一、Python的数据类型
1、int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647,而.在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
2、long(长整型)
为什么会有这个概念呢?
因为在Python2.2起,如果放置在内存里的数特别大发生溢出,Python就会自动将整型数据转换为长整型,但是现在,在Python3里就不存在长整型这么一说了,同意都是整型。
3、float(浮点型)
简单理解就是带有小数的数字
4、complex(复数)
复数是由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y呢是复数的虚数部分,这里的x和y都是实数。
5、布尔值(0或1)
就是真和假。
6、查看数据类型(type)
>>> type()
<class 'int'>
>>> type(1.2)
<class 'float'>
>>> type(jixuege)
Traceback (most recent call last):
File "<stdin>", line , in <module>
NameError: name 'jixuege' is not defined 上面报错原因就是没有用双引号引起来,他就不是字符串,而是认为是一个变量。
>>> type("jixuege")
<class 'str'>
二、for和while循环
这里呢就需要涉及到break和continue的区别了。
如何理解呢?
break: 只能跳出当前循环,当前这一套循环就结束了。
continue: 跳出当次循环,然后呢还会去继续下一次别的循环。
举个栗子:
#!/usr/bin/env python
# -*- coding: utf- -*-
#Author: Leon xie for n in range():
print(n)
for j in range():
if j <:
#如果j小于2就跳出当次循环,继续一下次循环
continue
print(n,j)
打印结果如下:
说明:
在第二次的if判断中,我执行条件,如果j小于2就跳出当次循环,继续一下次循环
下面我们就看看break的使用
同样的代码,咋们接着看
#!/usr/bin/env python
# -*- coding: utf- -*-
#Author: Leon xie for n in range():
print(n)
break
for j in range():
if j <:
#如果j小于2就跳出当次循环,继续一下次循环
continue
print(n,j)
打印结果如下:
0
小结:
个人来说明一下,二者的区别,continue呢用于我有很多次循环,然后呢,我不希望哪次循环执行下面的动作,就可以了使用continue ,而break呢就是我这次循环了以后我想跳出去不在循环,或者呢就是我写了一段代码,我想跳出去看看代码是否能执行,就可以用break呢。
三、Python的数据类型
1、整型int
可以直接理解为整数
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647,在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
2、浮点型float
可以直接理解为带小数的数字。
3、复数complex
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
4、布尔值(0或1)
表示真或者假
5、查看数据类型
使用type即可。
>>> type("xiedi")
<class 'str'>
>>> type("")
<class 'str'>
>>> type(2.2)
<class 'float'>
>>> type()
<class 'int'>
>>>
这里有个地方需要注意,就是数字不需要加引号,如果加了就是字符串。
四、Python字符串基本操作
1、判断是不是合法的标识符isidentifier
name="ABC"
print(name.isidentifier())
打印结果
True
2、首字母大写capitalize
name= 'abc'
print(name.capitalize())
打印结果
Abc
3、计数count
name= 'abc'
print(name.count("a"))
打印结果
4、位于中心,用-来补充center
name= 'abc'
print(name.center(,"-"))
打印结果
-----------------------abc------------------------
5、判断是否以c结尾endswith
name= 'abc'
print(name.endswith("c"))
打印结果
True
6、把回车换成空格expandtabs
name = "a\tbc"
print(name.expandtabs(tabsize=))
打印结果
a bc
7、查看某字符下标find
name= 'abc'
print(name.find('c'))
打印结果
8、将字符小写lower
print("XIEDI".lower())
打印结果
xiedi
9、将字符大写upper
print("xiedi".upper())
XIEDI
五、Python列表基本操作
记住一句话,叫做顾首不顾尾
首先我们来定义一个列表
name = ["jixuege","dajiba","boduoye","cangjinkong","youtianai"]
接下来,我们就对这个列表来进行一系列的操作
1、切片
取值,取第一个和第二个
print(name[],name[])
打印结果
jixuege dajiba
说明:
上面的0和1指的是小标,从左到右顺序就是从0开始一直到4
打印一个区间
name = ["jixuege","dajiba","boduoye","cangjinkong","youtianai"] print(name[:])
打印结果
['jixuege', 'dajiba']
打印最后一个
name = ["jixuege","dajiba","boduoye","cangjinkong","youtianai"]
print(name[-])
打印结果
youtianai
2、追加
比如说我想追加一个人进去
name = ["jixuege","dajiba","boduoye","cangjinkong","youtianai"]
name.append("xiha")
print(name)
打印结果 ['jixuege', 'xitong', 'dajiba', 'youhua', 'boduoye', 'cangjinkong', 'youtianai', 'xiha']
这个会追加到末尾
还有一种就是插入insert
name = ["jixuege","dajiba","boduoye","cangjinkong","youtianai"] name.insert(,"youhua")
print(name)
打印结果
['jixuege', 'dajiba', 'youhua', 'boduoye', 'cangjinkong', 'youtianai']
3、修改
直接修改即可
name = ["jixuege","dajiba","boduoye","cangjinkong","youtianai"]
name[]="wuming"
print(name)
打印结果
['jixuege', 'dajiba', 'wuming', 'cangjinkong', 'youtianai']
4、删除
直接清空
name = ["jixuege","dajiba","boduoye","cangjinkong","youtianai"]
name.clear()
print(name)
打印结果
[]
删除指定元素
name = ["jixuege","dajiba","boduoye","cangjinkong","youtianai"]
name.remove("jixuege")
print(name)
打印结果 ['dajiba', 'boduoye', 'cangjinkong', 'youtianai']
删除指定下标
name = ["jixuege","dajiba","boduoye","cangjinkong","youtianai"]
del name[]
print(name)
打印结果
['jixuege', 'dajiba', 'cangjinkong', 'youtianai']
不指定下标删除最后一个
name = ["jixuege","dajiba","boduoye","cangjinkong","youtianai"]
name.pop()
print(name)
打印结果
['jixuege', 'dajiba', 'boduoye', 'cangjinkong']
指定下标
name = ["jixuege","dajiba","boduoye","cangjinkong","youtianai"]
name.pop()
print(name)
打印结果
['jixuege', 'boduoye', 'cangjinkong', 'youtianai']
六、蛋疼的购物车程序练习
要求:
1、用户输入工资,打印出商品的列表
2、用户根据编号来进行购买商品
3、用户选择商品之后,先检测额度是否够用,直接扣款和温馨提示余额不足
4、可以随时退出,退出并打印出已购商品列表和余额。
#!/usr/bin/env python
# -*- coding: utf- -*-
#Author: Leon xie product_list = [
["Iphone",],
["MAC PRO",],
["Bike",],
["Coffee",],
] shopping_list = [] salary = input("请输入你的工资:")
#判断是否为数字
if salary.isdigit():
salary = int(salary)
while True:
for index,item in enumerate(product_list):
#打出菜单
print(index,item[],item[]) choice = input("请选择要购买的商品编号[quit]>>:")
if choice.isdigit():
choice = int(choice)
if choice >= and choice < len(product_list):
#判断钱是否够用
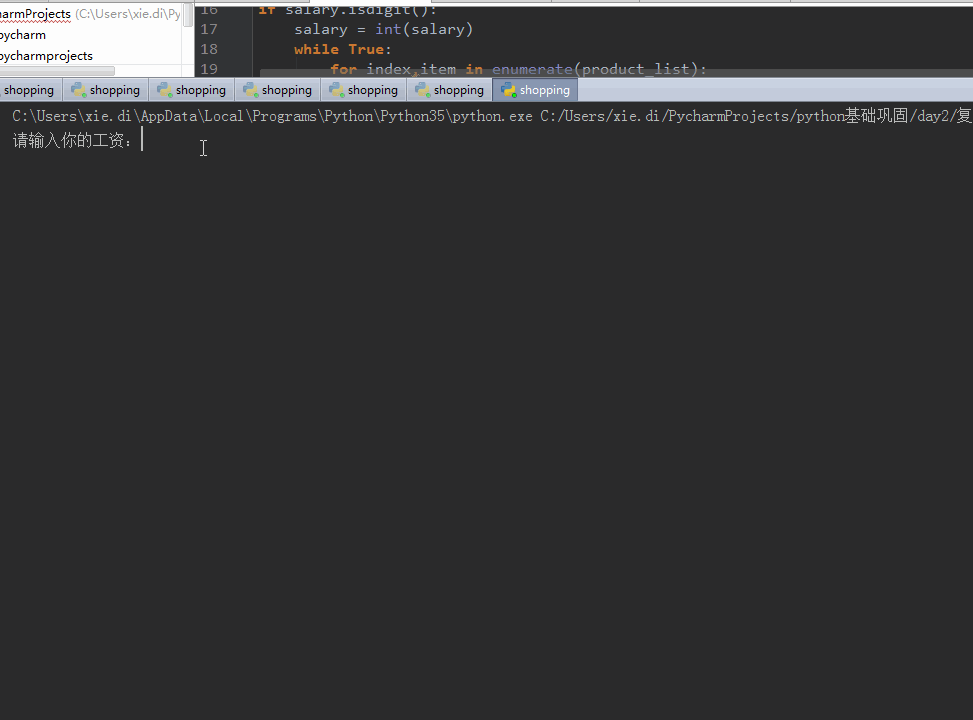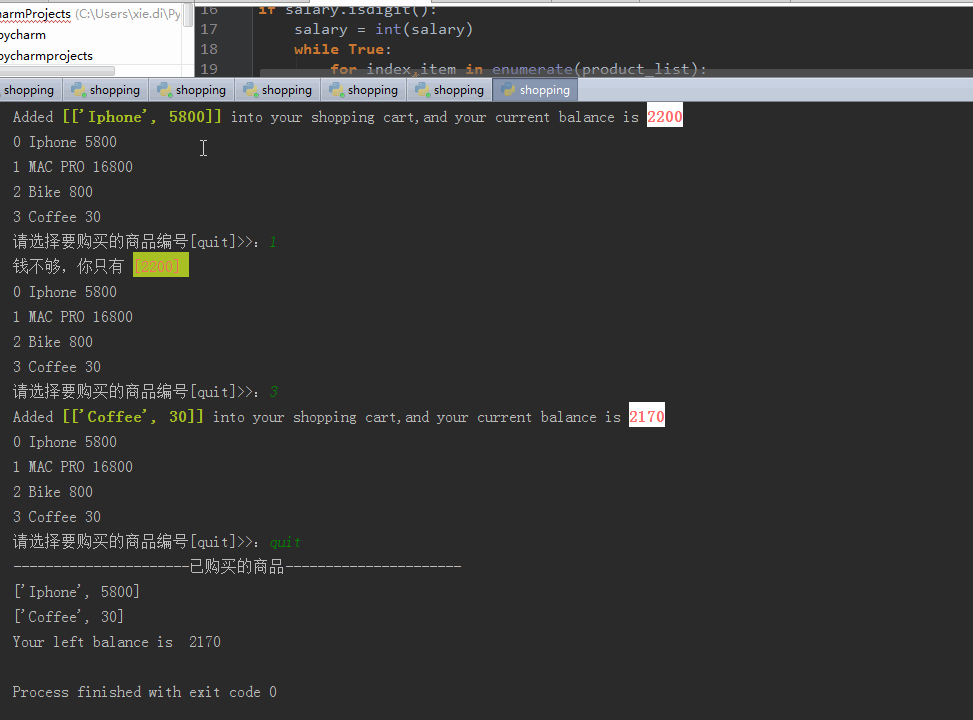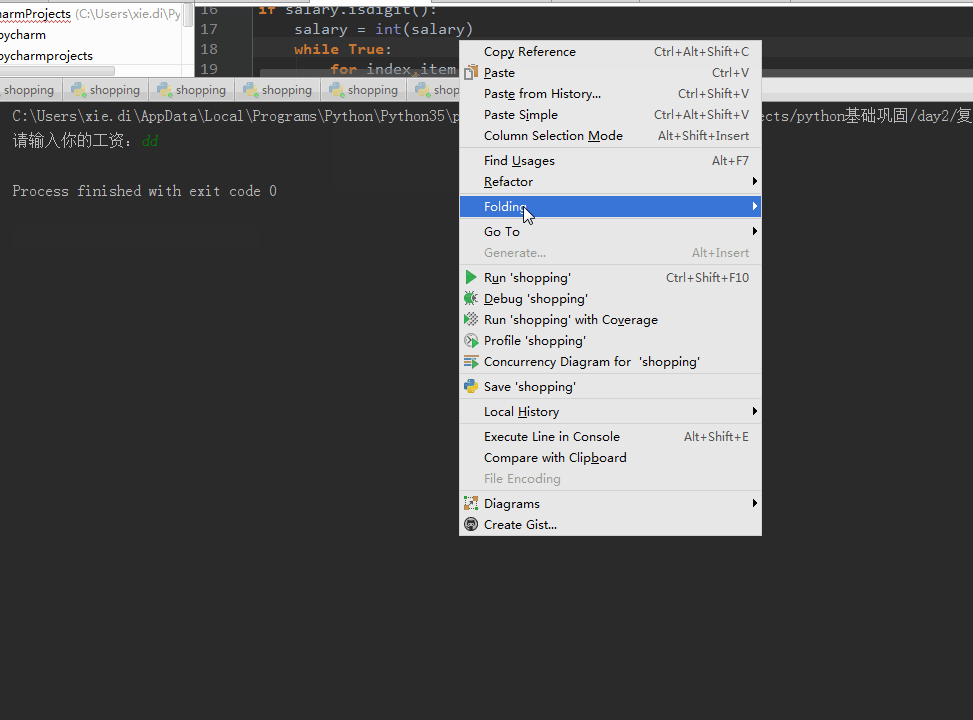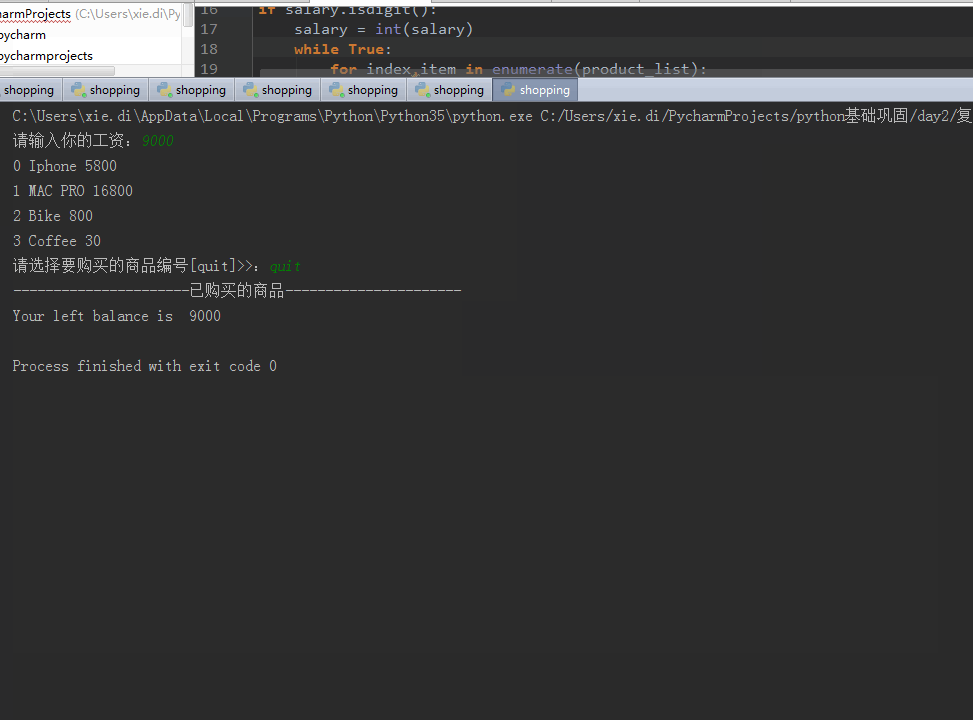
p = product_list[choice] if p[] <= salary:
shopping_list.append(p)
salary -= p[]
print("Added \033[32;1m[%s]\033[0m into your shopping cart,and your current balance is \033[1;31;40m%s\033[0m"%(p,salary))
else:
print("钱不够,你只有 \033[5;31;42m[%s] \033[0m "% salary)
else:
print("没有此商品...") elif choice == "quit":
print("已购买的商品".center(,"-"))
for i in shopping_list:
print(i)
print("Your left balance is ",salary)
exit()
else:
print("未识别,请输入正确的指令!!")
购物车效果如下所示:
一个初学者的辛酸路程-了解Python-2的更多相关文章
- 一个初学者的辛酸路程-python操作SQLAlchemy-13
前言 其实一开始写blog,我是拒绝的,但是,没办法,没有任何理由抗拒.今天呢,要说的就是如何使用Python来操作数据库. SQLAlchemy SQLAlchemy是Python编程语言下的一款O ...
- 一个初学者的辛酸路程-Python基础-3
前言 不要整天沉迷于学习-. 字典 一.我想跟你聊聊字典 1.为何要有字典? 大家有没有想过为什么要有字典?有列表不就可以了吗? 也许大家会这么认为,我给大家举个例子,大家就明白了. 比如说,我通讯录 ...
- 一个初学者的辛酸路程-FTP-9
前言 今天,我要描述一个FTP的故事 主要内容 嗯,今天主要以阶梯性的形式来做一个FTP项目. 第一步: 我要实现这么一个功能,一个FTP客户端,1个FTP服务端,2端建立连接以后可以进行通讯. 服务 ...
- 一个初学者的辛酸路程-socket编程-8
前言: 你会发现会网络是多么幸福的事情 主要内容: socket 概念: socket本质上就是2台网络互通的电脑之间,架设一个通道,两台电脑通过这个通道来实现数据的互相传递.我们知道网络通信都是基于 ...
- 一个初学者的辛酸路程-初识Python-1
前言 很喜欢的一句话,与诸位共勉. 人的一切痛苦,本质上都是对自己无能的愤怒----王小波. 初识Python 一.它的爸爸是谁 首先,我们需要认识下面这位人物. 他是Python的创始人,吉多范罗苏 ...
- 一个初学者的辛酸路程-依旧Django
回顾: 1.Django的请求声明周期? 请求过来,先到URL,URL这里写了一大堆路由关系映射,如果匹配成功,执行对应的函数,或者执行类里面对应的方法,FBV和CBV,本质上返回的内容都是字符串 ...
- 一个初学者的辛酸路程-继续Django
问题1:HTTP请求过来会先到Django的那个地方? 先到urls.py ,里面写的是对应关系,1个URL对应1个函数名. 如果发URL请求过来,到达这里,然后帮你去执行指定的函数,函数要做哪些事 ...
- 一个初学者的辛酸路程-初识Django
前言: 主要是关于JavaScript的高级部分以及Django 主要内容: 一.jQuery 事件绑定: DOM事件绑定: -直接在标签上绑定 第一种: $('.title').click(func ...
- 一个初学者的辛酸路程-jQuery
前言: 主要概要: 1.HTML+CSS补充 2.DOM事件 3.jQuery示例 内容概要: 1.布局 代码如下 <!DOCTYPE html> <html lang=" ...
随机推荐
- Memcached帮助类
一.如果用官方提供的方法,在web.config里面配置好了各个参数和服务器IP <?xml version="1.0"?> <configuration> ...
- 简单的jquery ajax文件上传功能
/* * 图片上传 * 注意如果不加processData:false和contentType:false会报错 */ function uploadImage(image) { var imageF ...
- mysql近几天的查询
今天:select*from table1 where to_days(时间字段名)=to_days(now()); 昨天:select*from table1 where to_days(now() ...
- VS编译wxWidgets
准备工作 下载wxWidgets源码包(官网),我用的是3.02版: 安装Visual Studio.我用的是VS 2015 RC: 编译源码 解压wxWidgets的源码包,会得到一大堆文件.进入b ...
- mysql语句中----删除表数据drop、truncate和delete的用法
程度从强到弱 1.drop table tb drop将表格直接删除,没有办法找回 2.truncate (table) tb 删除表中的所有数据,不能与where一起使用 ...
- 折腾一天,终于配置好了,ssl证书,启用了https,用的阿里云ECS服务器
阿里云ECS服务器配置了ssl证书, httpd-ssl.conf 的配置很重要,网站目录一定要设置正确. 阿里云的虚拟空间,弹性Web,目前好像还不支持ssl证书. 最后要网站强制https,下面 ...
- android 5.0 -- Activity 过渡动画
android 5.0 提供3种过渡动画: 进入 退出 进入退出包括如下效果: explode 分解:屏幕中间进出 slide 滑动:屏幕边缘进出 fade 淡出:改变透明度来添加或者移除视图 共享 ...
- Solr搜索技术
Solr搜索技术 今日大纲 回顾上一天的内容: 倒排索引 lucene和solr的关系 lucene api的使用 CRUD 文档.字段.目录对象(类).索引写入器类.索引写入器配置类.IK分词器 查 ...
- HDU 1054 Strategic Game(无向二分图的最大匹配)
( ̄▽ ̄)" //凡无向图,求匹配时都要除以2 #include<iostream> #include<cstdio> #include<algorithm&g ...
- uhttpd配置文件分析
文件位于 /etc/config/uhttpd. root@hbg:/etc/config# cat uhttpd config uhttpd 'main' list listen_ht ...