爬虫_拉勾网(selenium)
使用selenium进行翻页获取职位链接,再对链接进行解析
会爬取到部分空列表,感觉是网速太慢了,加了time.sleep()还是会有空列表
from selenium import webdriver
import requests
import re
from lxml import etree
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By class LagouSpider(object):
def __init__(self):
opt = webdriver.ChromeOptions()
# 把chrome设置成无界面模式
opt.set_headless()
self.driver = webdriver.Chrome(options=opt)
self.url = 'https://www.lagou.com/jobs/list_爬虫?px=default&city=北京'
self.headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
} def run(self):
self.driver.get(self.url)
while True:
html = ''
links = []
html = self.driver.page_source
links = self.get_one_page_links(html)
for link in links:
print('\n' + link+'\n')
self.parse_detail_page(link) WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'pager_next')))
next_page_btn = self.driver.find_element_by_class_name('pager_next') if 'pager_next_disabled' in next_page_btn.get_attribute('class'):
break
else:
next_page_btn.click()
time.sleep(1) def get_one_page_links(self, html):
links = []
hrefs = self.driver.find_elements_by_xpath('//a[@class="position_link"]')
for href in hrefs:
links.append(href.get_attribute('href'))
return links def parse_detail_page(self, url):
job_information = {}
response = requests.get(url, headers=self.headers) time.sleep(2)
html = response.text
html_element = etree.HTML(html)
job_name = html_element.xpath('//div[@class="job-name"]/@title')
job_description = html_element.xpath('//dd[@class="job_bt"]//p//text()')
for index, i in enumerate(job_description):
job_description[index] = re.sub('\xa0', '', i)
job_address = html_element.xpath('//div[@class="work_addr"]/a/text()')
job_salary = html_element.xpath('//span[@class="salary"]/text()') # 字符串处理去掉不必要的信息
for index, i in enumerate(job_address):
job_address[index] = re.sub('查看地图', '', i)
while '' in job_address:
job_address.remove('') job_information['job_name'] = job_name
job_information['job_description'] = job_description
job_information['job_address'] = job_address
job_information['job_salary'] = job_salary
print(job_information) def main():
spider = LagouSpider()
spider.run() if __name__ == '__main__':
main()
运行结果
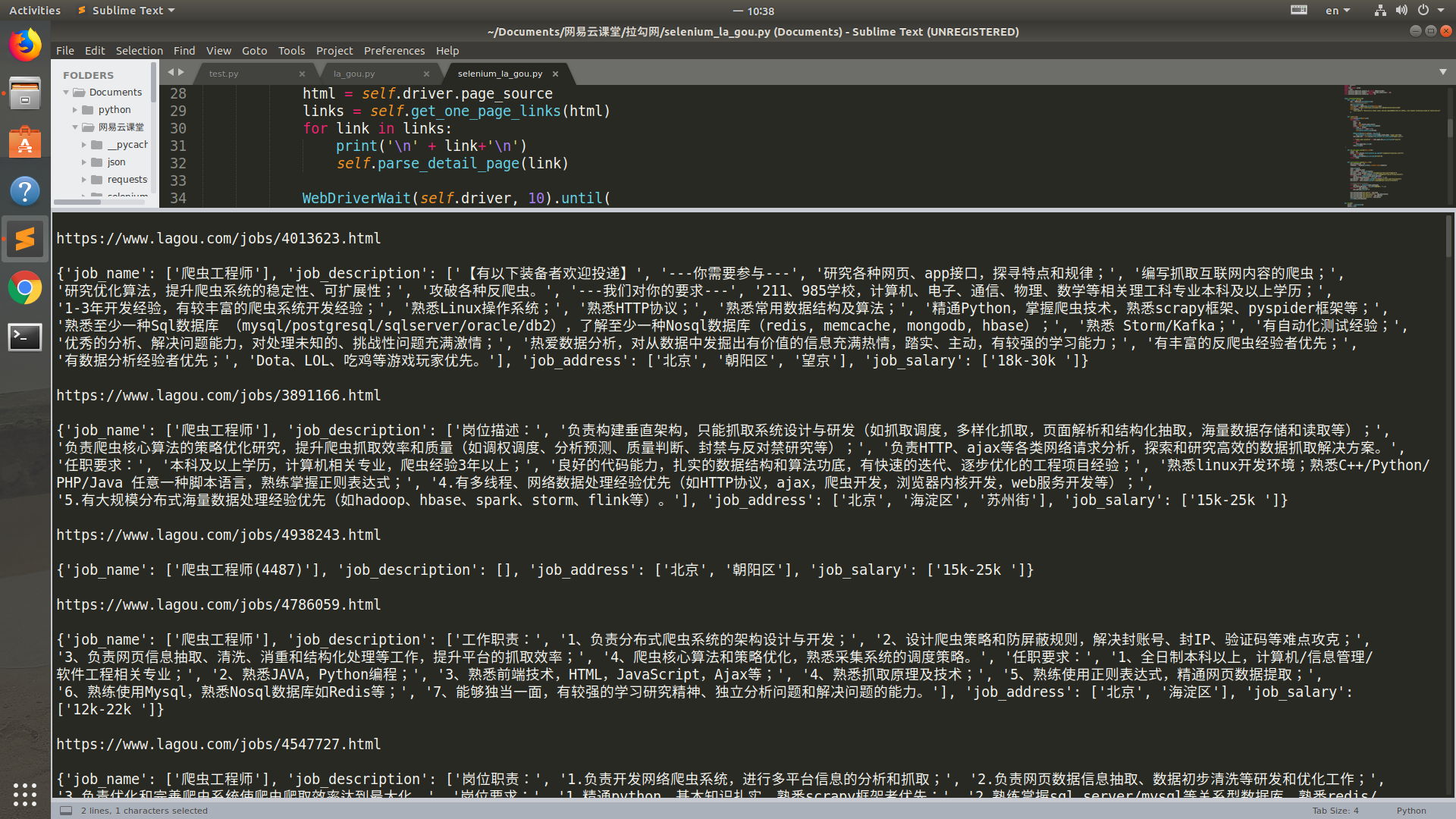
爬虫_拉勾网(selenium)的更多相关文章
- 爬虫_拉勾网(解析ajax)
拉勾网反爬虫做的比较严,请求头多添加几个参数才能不被网站识别 找到真正的请求网址,返回的是一个json串,解析这个json串即可,而且注意是post传值 通过改变data中pn的值来控制翻页 job_ ...
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- scrapy爬虫框架和selenium的配合使用
scrapy框架的请求流程 scrapy框架? Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架.因此Scrapy使用了一种非阻塞(又名异步)的 ...
- Python爬虫之设置selenium webdriver等待
Python爬虫之设置selenium webdriver等待 ajax技术出现使异步加载方式呈现数据的网站越来越多,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成,这给定位元素的定位增加 ...
- # Python3微博爬虫[requests+pyquery+selenium+mongodb]
目录 Python3微博爬虫[requests+pyquery+selenium+mongodb] 主要技术 站点分析 程序流程图 编程实现 数据库选择 代理IP测试 模拟登录 获取用户详细信息 获取 ...
- 爬虫_淘宝(selenium)
总体来说代码还不是太完美 实现了js渲染网页的解析的一种思路 主要是这个下拉操作,不能一下拉到底,数据是在中间加载进来的, 具体过程都有写注释 from selenium import webdriv ...
- 爬虫基础(三)-----selenium模块应用程序
摆脱穷人思维 <三> : 培养"目标导向"的思维: 好项目永远比钱少,只要目标正确,钱总有办法解决. 一 selenium模块 什么是selenium?seleni ...
- PYTHON 爬虫笔记七:Selenium库基础用法
知识点一:Selenium库详解及其基本使用 什么是Selenium selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium ...
- python3[爬虫实战] 使用selenium,xpath爬取京东手机
使用selenium ,可能感觉用的并不是很深刻吧,可能是用scrapy用多了的缘故吧.不过selenium确实强大,很多反爬虫的都可以用selenium来解决掉吧. 思路: 入口: 关键字搜索入口 ...
随机推荐
- H5 67-清除浮动方式三
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Vector源码分析
Vector与ArrayList底层实现基本类似,底层都是用数组实现的,最大的不同是Vector是线程安全的.ArrayList源码分析请参考ArrayList源码分析 一.源码分析 基于jdk1.7 ...
- php获取URL扩展名
一切拿代码来说话: 举例:'http://www.sina.com.cn/abc/de/fg.php?id=1': $url = 'http://www.sina.com.cn/abc/de/fg.p ...
- IdentityServer4【QuickStart】之使用asp.net core Identity
使用asp.net core Identity IdentityServer灵活的设计中有一部分是可以将你的用户和他们的数据保存到数据库中的.如果你以一个新的用户数据库开始,那么,asp.net co ...
- hangfire使用笔记
1.导入nuget包 2.配置 简单配置后就可以写自己的Job了 注意:Hangfire.RecurringJobExtensions这个扩展支持两种job添加方法:json配置文件和特性.但由于时区 ...
- HDU 5898 odd-even number
题目:odd-even number 链接:http://acm.split.hdu.edu.cn/showproblem.php?pid=5898 题意:给一个条件,问l 到r 之间有多少满足条件的 ...
- day 7-7 线程池与进程池
一. 进程池与线程池 在刚开始学多进程或多线程时,我们迫不及待地基于多进程或多线程实现并发的套接字通信,然而这种实现方式的致命缺陷是:服务的开启的进程数或线程数都会随着并发的客户端数目地增多而增多,这 ...
- InputFormat的数据划分、Split调度、数据读取
在执行一个Job的时候,Hadoop会将输入数据划分成N个Split,然后启动相应的N个Map程序来分别处理它们.数据如何划分?Split如何调度(如何决定处理Split的Map程序应该运行在哪台Ta ...
- centos安装Tesseract
yum安装(推荐) yum search tesseract yum install tesseract.x86_64 -y pip3 install pytesseract pip3 install ...
- Vue.js文档
参考网址:https://vuefe.cn/ 第一 安装 1.下载到本地后使用<script>标签直接引入 2.使用CDN引入 例如:使用CDN引入 <script src=&qu ...