爬虫之scrapy入门
1.介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
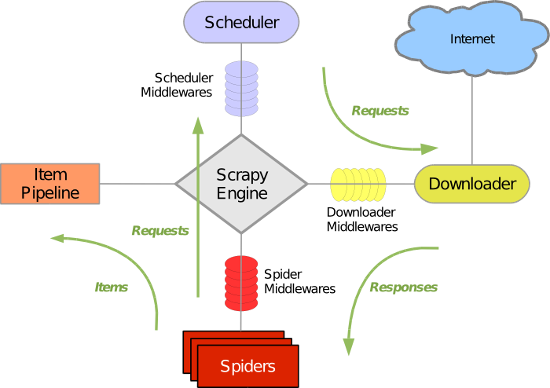
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
2.下载
Linux
pip3 install scrapy Windows
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d.pyOpenSSL https://pypi.python.org/pypi/pyOpenSSL#downloads
d. 下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/
e. pip3 install scrapy
3.基础使用
1. scrapy startproject 项目名称
- 在当前目录中创建中创建一个项目文件(类似于Django) 2. scrapy genspider [-t template] <name> <domain>
- 创建爬虫应用
如:
scrapy gensipider -t basic oldboy oldboy.com
scrapy gensipider -t xmlfeed autohome autohome.com.cn
PS:
查看所有命令:scrapy gensipider -l
查看模板命令:scrapy gensipider -d 模板名称 3. scrapy list
- 展示爬虫应用列表 4. scrapy crawl 爬虫应用名称
- 运行单独爬虫应用
项目结构
project_name/
scrapy.cfg
project_name/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
spider1.py
spider2.py
spider3.py
♢ scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
♢ items.py 设置数据存储模板,用于结构化数据,如:Django的Model
♢ pipelines 数据处理行为,如:一般结构化的数据持久化
♢ settings.py 配置文件,如:递归的层数、并发数,延迟下载等
♢ spiders 爬虫目录,如:创建文件,编写爬虫规则
4.小试牛刀例子
import scrapy
from scrapy.selector import Selector
from test1.items import Test1Item class XiaohuaSpider(scrapy.Spider):
name = 'xiaohua'
allowed_domains = ['xiaohuar.com']
start_urls = ['http://www.xiaohuar.com/hua/'] def parse(self, response):
xph = Selector(response=response).xpath('//div[@id="list_img"]//div[@class="item_t"]')
for i in xph:
item = Test1Item()
item['img_url'] = i.xpath('./div[@class="img"]/a/img/@src').extract_first()
item['name'] = i.xpath('./div[@class="img"]/a/img/@alt').extract_first()
yield item
next = Selector(response=response).xpath('//div[@id="page"]//a[17]/@href').extract_first()
if next:
yield scrapy.Request(url=next, callback=self.parse)
spider.py/xiaohua.py
import os,requests
class Test1Pipeline(object):
def process_item(self, item, spider):
if item['img_url'][0] == '/':
item['img_url'] = 'http://www.xiaohuar.com/' + item['img_url']
filename = os.path.join('xiaohua', item['name']) + '.png'
img = requests.get(item['img_url'])
if img.status_code == 200:
if os.path.exists('xiaohua'):
pass
else:
os.mkdir('xiaohua')
with open(filename, 'wb')as f:
f.write(img.content)
else:
print('保存失败')
pipelines.py
import scrapy
class Test1Item(scrapy.Item):
img_url = scrapy.Field()
name = scrapy.Field()
item.py
爬虫之scrapy入门的更多相关文章
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- SoapUI接口测试-验签值处理-调用java的加密jar包
转载自:https://www.jianshu.com/p/7c672426a165 一. 背景: 调用接口时有个请求参数是对请求入参按一定规则进行加密生成的验签值,每次不同参数的请求生成唯一的验签值 ...
- Windos下pip配置豆瓣源
C:\Users\liche\pip 下创建pip.ini文件 pip.ini [global] index-url = http://pypi.douban.com/simple [install] ...
- 浏览器端使用javascript调用腾讯翻译api
最近在学习的小玩意,发现腾讯的文档十分坑爹,里面有很多错误的指示. 不过腾讯的机器翻译还是很牛的,我觉得翻译水准比谷歌好很多. 腾讯的机器翻译貌似在试用阶段,不收费,用QQ或微信登录即可申请使用. 首 ...
- webRTC中音频相关的netEQ(五):DSP处理
上篇(webRTC中音频相关的netEQ(四):控制命令决策)讲了MCU模块是怎么根据网络延时.抖动缓冲延时和反馈报告等来决定给DSP模块发什么控制命令的.DSP模块根据收到的命令进行相关处理,处理简 ...
- Intel_AV-ICE06加速卡+QAT_Engine测试
Intel AV-ICE06加速卡测试报告 Intel RSA加速卡结合Intel其QAT_Engine测试性能的提升,其支持的异步模式对性能的提升很大. 注意QAT_Engine只支持openssl ...
- 负载均衡中的session保持
什么叫负载均衡中的session保持 当我们需要做负载均衡时,服务端肯定有多台服务器,用户每次请求进来,会根据负载均衡算法被分配到某一台机器上,假设用户需要进行一段连续操作时,在第一台机器登陆后,下一 ...
- C# 6.0:在catch和finally中使用await
Asyn方法是一个现在很常用的方法,当使用async和await时,你或许曾有这样的经历,就是你想要在catch块或finally块中使用它们,比如当出现一个exception而你希望将日志记在文件或 ...
- 使用命令行执行jmeter的方法
1. 简介 使用非 GUI 模式,即命令行模式运行 JMeter 测试脚本能够大大缩减所需要的系统资 本文介绍windows下以命令行模式运行的方法. 1.1. 命令介绍 jmeter -n -t & ...
- vs2017使用问题
最近安装了新版本的Visual studio 2017,但是在使用的过程中遇到了这样一个问题.刚启动电脑后,打开vs2017是可以打开的,但是当关掉之后再打开就打不开了,但是任务管理器看可以看到有一 ...
- centos7 安装远程桌面
https://www.linuxidc.com/Linux/2017-09/147050.htm https://blog.csdn.net/dazhi_1314/article/details/7 ...