【转】Leveldb源码分析——1
先来看看Leveldb的基本框架,几大关键组件,如图1-1所示。
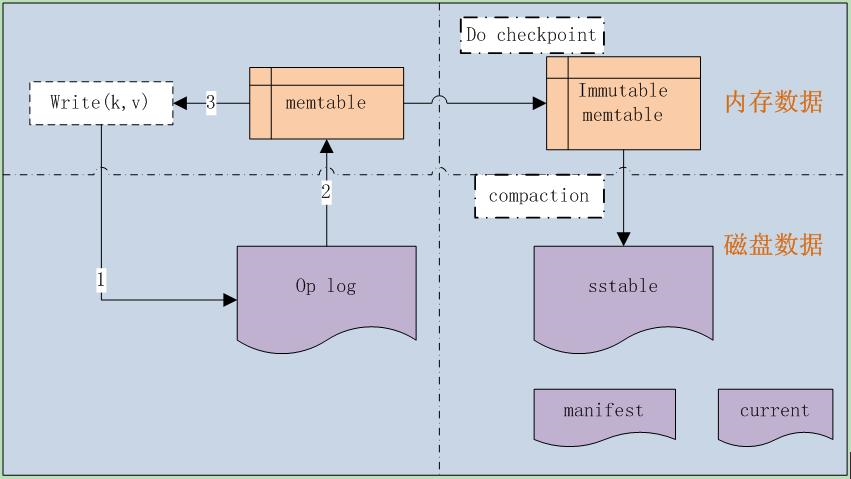
Leveldb是一种基于operation log的文件系统,是Log-Structured-Merge Tree的典型实现。LSM源自Ousterhout和Rosenblum在1991年发表的经典论文《The Design and Implementation of a Log-Structured File System》。
由于采用了op log,它就可以把随机的磁盘写操作,变成了对op log的append操作,因此提高了IO效率,最新的数据则存储在内存memtable中。
当op log文件大小超过限定值时,就定时做check point。Leveldb会生成新的Log文件和Memtable,后台调度会将Immutable Memtable的数据导出到磁盘,形成一个新的SSTable文件。SSTable就是由内存中的数据不断导出并进行Compaction操作后形成的,而且SSTable的所有文件是一种层级结构,第一层为Level 0,第二层为Level 1,依次类推,层级逐渐增高,这也是为何称之为Leveldb的原因。
1、一些约定
先说下代码中的一些约定:
1.1 字节序
Leveldb对于数字的存储是Little-endian的,在把int32或者int64转换为char*的函数中,是按照先地位再高位的顺序存放,也就是little-endian模式。
1.2 VarInt
把一个int32或者int64格式化到字符串中,除了上面说的little-endian字节序外,大部分还是变长存储的,也就是VarInt。对于VarInt,每byte的有效存储是7bit的,用最高的8bit位来表示是否结束,如果是1,就表示后面还有一个byte的数字,否则表示结束。在操作log中,使用的是Fixed存储格式。
1.3 字符比较
是基于unsigned char的,而非char。
2、基本数据结构
别看是基本数据结构,有些也不是那么简单的,像LRU Cache管理和Skip list那都算是leveldb的革新数据结构。
2.1 Slice
Leveldb中的基本数据结构,它包括length和一个指向外部字节数组的指针。和string一样,允许字符串中包含'\0'。
提供一些基本接口,可以把const char*和string转换为Slice;把Slice转换为string,取得数据指针const char*。
2.2 Status
Leveldb中的返回状态,将错误号和错误信息封装成Status类,统一进行处理。并定义了几种具体的返回状态,如成功或者文件不存在等。
为了节省空间,Status并没有用std::string来存储错误信息,而是将返回码(code),错误信息message及长度打包存储于一个字符串数组中。
成功状态OK对应是NULL的state_,否则state_是一个包含如下信息的数组:
state_[0..3] == 消息message长度
state_[4] == 消息code
state_[5..] ==消息message
2.3 Arena
Leveldb的简单的内存池,它所作的工作十分简单,申请内存时,将申请到的内存块放入std::vector blocks_中,在Arena的生命周期结束后,统一释放掉所有申请到的内存,内部结构如图所示。

Arena主要提供了两个申请函数:其中一个直接分配内存,另一个可以申请对齐的内存空间。Arena没有直接调用delete/free函数,而是由Arena的析构函数同意释放所有的内存。
应该说这是和leveldb特定的应用场景相关的,比如一个memtable使用一个Arena,当memtable被释放时,由Arena统一释放其内存。
2.4 Skip list
Skip list(跳跃表)是一种可以代替平衡树的数据结构。Skip lists应用概率保证平衡,平衡树采用严格的旋转(比如平衡二叉树有左旋右旋)来保证平衡,因此Skip list比较容易实现,而且相比平衡树有着较高的运行效率。
从概率上保持数据结构的平衡比显式地保持数据结构平衡要简单的多。对于大多数应用,用skip list要比用树更自然,算法也会相对简单。如下图所示。

在Leveldb中,skip list是实现memtable的核心数据结构,memtable的KV数据都存储在skip list中。
2.5 Cache
Leveldb内部通过双向链表实现了一个标准版的LRU Cache,先上个示意图,看看几个数据之间的关系,如下图所示。
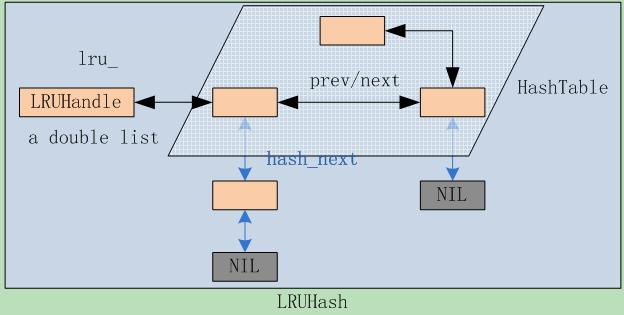
接下来说说Leveldb实现LRU Cache的几个步骤,很直观明了。
S1:定义一个LRUHandle结构体,代表cache中的元素。它包含了几个主要的成员:
void value;//这个存储的是cache的数据;
void (*deleter)(const Slice&, void* value);//这个是数据从Cache中清除时执行的清理函数
后面的三个成员是关于LRU Cache的数据的组织结构:
> LRUHandle* next_hash;
指向节点在hash table链表中的下一个hash(key)相同的元素,在有碰撞时Leveldb采用的是链表法。最后一个节点的next_hash为NULL。
>LRUHandle *next, *prev;
节点在双向链表中的前驱后继节点指针,所有的cache数据都是存储在一个双向list中,最前面的是最新加入的,每次新加入的位置都是head->next。所以每次剔除的规则就是剔除list tail。
S2:Leveldb自己实现了一个hash table:HandleTable,而不是使用系统提供hash table。这个类就是基本的hash操作:Lookup、Insert和Delete。hash table的作用是根据key快速查找元素是否在cache中,并返回LRUHandle节点指针,由此就能快速定位节点在hash表和双向链表中的位置。
它是通过LRUHandle的成员next_hash组织起来的。
HandleTable使用LRUHandle **list_存储所有的hash节点,其实就是一个二维数组,一维是不同的hash(key),另一维则是相同hash(key)的碰撞list。
每次当hash节点数超过当前一维数组的长度后,都会做Resize操作:
LRUHandle **new_list = new LRUHandle *[new_length];
然后复制list_到new_list中,并删除旧的list_。
S3:基于HandleTable和LRUHandle,实现了一个标准的LRUCache,并内置了mutex保护锁,是线程安全的。
其中存储所有数据的双向链表是LRUHandle lru_,这是一个list head;
Hash表则是HandleTable table_;
S4:ShardedLRUCache类,实际上到S3,一个标准的LRU Cache已经实现,为何还要更进一步呢?答案就是速度!
为了多线程访问,尽可能快速,减少锁开销,ShardedLRUCache内部有16个LRUCache,查找key时首先计算key属于哪一个分片,分片的计算方法是取32位hash值的高4位,然后在相应的LRUCache中进行查找,这样就大大减少了多线程的访问锁的开销。
LRUCache shard_[kNumShards]
它就是一个包装类,实现都在LRUCache类中。
2.6 其它
此外还有其它几个Random、Hash、CRC32、Histogram等,都在util文件夹下,不仔细分析了。
转自:http://blog.csdn.net/sparkliang/article/details/8567602
【转】Leveldb源码分析——1的更多相关文章
- leveldb源码分析--SSTable之block
在SSTable中主要存储数据的地方是data block,block_builder就是这个专门进行block的组织的地方,我们来详细看看其中的内容,其主要有Add,Finish和CurrentSi ...
- leveldb源码分析--WriteBatch
从[leveldb源码分析--插入删除流程]和WriteBatch其名我们就很轻易的知道,这个是leveldb内部的一个批量写的结构,在leveldb为了提高插入和删除的效率,在其插入过程中都采用了批 ...
- leveldb源码分析--Key结构
[注]本文参考了sparkliang的专栏的Leveldb源码分析--3并进行了一定的重组和排版 经过上一篇文章的分析我们队leveldb的插入流程有了一定的认识,而该文设计最多的又是Batch的概念 ...
- Leveldb源码分析--1
coming from http://blog.csdn.net/sparkliang/article/details/8567602 [前言:看了一点oceanbase,没有意志力继续坚持下去了,暂 ...
- leveldb源码分析--日志
我们知道在一个数据库系统中为了保证数据的可靠性,我们都会记录对系统的操作日志.日志的功能就是用来在系统down掉的时候对数据进行恢复,所以日志系统对一个要求可靠性的存储系统是极其重要的.接下来我们分析 ...
- leveldb源码分析之Slice
转自:http://luodw.cc/2015/10/15/leveldb-02/ leveldb和redis这样的优秀开源框架都没有使用C++自带的字符串string,redis自己写了个sds,l ...
- LevelDB源码分析--Cache及Get查找流程
本打算接下来分析version相关的概念,但是在准备的过程中看到了VersionSet的table_cache_这个变量才想起还有这样一个模块尚未分析,经过权衡觉得leveldb的version相对C ...
- leveldb源码分析--SSTable之TableBuilder
上一篇文章讲述了SSTable的格式以后,本文结合源码解析SSTable是如何生成的. void TableBuilder::Add(const Slice& key, const Slice ...
- leveldb源码分析之内存池Arena
转自:http://luodw.cc/2015/10/15/leveldb-04/ 这篇博客主要讲解下leveldb内存池,内存池很多地方都有用到,像linux内核也有个内存池.内存池的存在主要就是减 ...
随机推荐
- JAVA核心技术I---JAVA基础知识(知识回顾)
一:多态问题 class Father { public void hello() { System.out.println("Father says hello."); } } ...
- HTML5-语义化标签
article -- 解释 article标签装载显示一个独立的文章内容.例如一篇完整的论坛帖子,一则网站新闻,一篇博客文章等等,一个用户评论等等 artilce可以嵌套,则内层的artilce对外层 ...
- Bitcoin Core钱包客户端的区块数据搬家指南
最近在饭团(微信中的一个服务号)里教一些朋友学习比特币和区块链技术,为了让大家深刻地理解去中心化网络和钱包等概念,我推荐大家一定要安装经典的Bitcoin Core钱包软件,有些朋友在安装的时候没有留 ...
- 一个Silverlight工程的各文件解析
创建一个解决方案,这个解决方案包括一个ASP.NET网站项目和一个Silverlight应用程序项目. 1)ASP.net项目: -------------Default.aspx:ASP.net默认 ...
- 保存页面数据的场所----Hidden、ViewState、ControlState
1.使用隐藏域Session.Application和Cache都是保存在服务器内存中的.一般来说我们是无权访问客户端的机器,把数据直接保存在客户端的(Cookie是一个例外,不过Cookie只能保存 ...
- GreenDao设置数据版本
GreenDao设置数据库版本增加后,会自动删除并创建新数据库,将SCHEMA_VERSION增加即可. 在3.0里可以在config配置里进行设置 apply plugin: 'com.androi ...
- Reshaper安装后vs快捷键不起作用
做如上设置
- C# CancellationTokenSource 终止线程 CancellationTokenSource实现对超时任务的取消
C# 使用 CancellationTokenSource 终止线程 使用CancellationTokenSource对象需要与Task对象进行配合使用,Task会对当前运行的状态进行控制(这个不用 ...
- Windows代替touch命令
Windows 代替Linux中的touch命令: echo >
- 检索 COM 类工厂中 CLSID 为 {00024500-0000-0000-C000-000000000046} 的组件时失败,原因是出现以下错误: 80070005。
错误描述:当在ASP.NET应用程序中引用Microsoft Excel组件,并在程序中调用时,部署到服务器上经常会遇到以下的错误:检索 COM 类工厂中 CLSID 为{00024500-0000- ...