第11章 AOF持久化
AOF持久化在硬盘上保存的是对Redis进行的逻辑操作,类似InnoDB中的bin log。说白了就是你对一个Redis输入了哪些语句,AOF文件都会原封不动的保存起来,等到需要回复Redis的时候再把这些语句执行一遍。
11.1 AOF持久化的实现
AOF简单的理解是把执行的语句记录在硬盘的文件上。
操作系统对文件的写入进行了一些优化,即把一条记录写在硬盘上需要分为两步:1、文件写入缓冲区 2、缓冲区内容同步。为了提高文件的读写速度,当用户调用write函数后,操作系统会把写入的数据暂存在内存缓冲区里。当 内存缓冲区满或者超过缓冲时限后,才会把缓冲区内容同步到硬盘上。这样做的优点是提高了读写效率,每次写入只需写到缓存里而不需要写到硬盘,缺点是具有一定的不安全性,如果缓冲区的内容没有及时同步到硬盘上此时计算机宕机那么就会失去这部分数据。为此操作系统提供了fsnsc fdatasync两个同步函数,强制同步缓冲区的数据到硬盘上。
AOF同步也是一种把记录写到硬盘上的行为,在上述两个步骤之外,Redis额外加一步命令,Redis先把记录追加到自己维护的一个aof_buf中。所以AOF持久化分为三步:1、命令追加 2、文件写入 3.文件同步
11.1.1 命令追加
服务器再执行完一条指令后会以规定的格式追加到aof_buf的末尾。如执行完SET KEY V1后,aof_buf末尾会多以下内容。
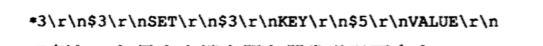
11.1.2 AOF文件的写入与同步
完成aof_buf写入后Redis会执行flushAppendOnlyFile,该方法根据配置文件的不同而采用不同的策略把aof_buf里的内容刷到内存缓冲区里,具体的根据appendfsync的取值来决定不同的策略。
- always,每次执行flushAppenfOnlyFIle的时候都会把aof——buf的内容刷到文件缓冲区,并且会同步缓冲区到硬盘
- everysec,把aof_buf刷到文件缓冲区,之后两次文件缓冲区同步间隔超过1秒才会同步缓冲区
- no,只刷到文件缓冲区,不管同步的事情
三种模式下安全性和效率性的比较
- always每次都要同步缓冲区,速度较慢,但不会出现内容缺失
- everysec,速度比always要快,但是有可能会损失一定的数据,不过损失最多是1秒钟
- no,执行速度最快,把文件缓冲区同步的调度交给了操作系统,安全性较差。并且当缓冲区积累到一定程度而不得不把内容写会文件系统后,会消耗大量的时间来完成同步的过程。所以均摊来看no 和 everysec效率类似。
11.2 AOF文件的载入与数据还原
如何从AOF文件中恢复之前保存的数据?AOF是一个逻辑的日志,只需要把AOF从头到尾执行一遍即可。Redis服务器端设计的是执行客户端发出的指令,所以在回复AOF文件的时候创建了一个伪客户端从AOF文件中读取内容发送Redis服务器端实行,当AOF文件全部执行完毕后数据库也就恢复了。
11.3 AOF重写
比如在操作Redis过程中把一个key的值从A改成了B然后又改回了A,此时AOF文件中有两条记录:A->B->A。所以在回复的时候回执行两次回复语句,但事实上是中间的两次变化是冗余的。随着Redis的执行,AOF不仅会变得冗余体积也会膨胀的更大。
为了解决冗余带来的体积膨胀,Redis提供了AOF文件重写功能,通过AOF文件重写得到的新AOF文件,其恢复的结果和旧的AOF文件相同,但是体积更小因为他不会包含冗余指令。
11.3.1 AOF文件重写的实现
AOF文件重写的逻辑非常简单,并不是分析旧的文件去除冗余指令,而是直接获取当前Redis的快照,然后用一条指令实现当前快照的结果并保存到AOF文件中。
Redis作为一个成熟的产品,在这种我想不到的细节处也做了优化。在AOF持久化时写入磁盘的时候会先写到缓冲区,然后再同步到硬盘里。如果把10条很短的写硬盘的命令浓缩成一个很长的写语句,那么此时有可能发生缓冲区溢出,所以当压缩后的一条语句很长的时候Redis会把他拆分成相对短的指令。
11.3.2 AOF后台重写
仔细回顾一下AOF重写其实很简单:得到当前Redis的一个快照,然后把逻辑指令写到硬盘上。现在有两个问题:
1、Redis使用单个线程来处理指令,如果指令去执行文件写操作--一个势必会带来大量阻塞时间的操作,此时会无法响应客户端的请求。所以必须要使用子进程来实现AOF重写,为什么是子进程而非子线程呢?是为了在不加锁的情况下仍然能够保证安全,因为子进程做的事情很单纯读取快照、生成AOF文件。不会和工作的进程产生任何冲突
2、数据不一致。子进程读取的是快照,而且当重写期间父进程仍然在工作所以快照和Redis数据库会存在数据不一致的情况。为了解决这个问题Redis设置了重写缓冲区。
第11章 AOF持久化的更多相关文章
- 【笔记】《Redis设计与实现》chapter11 AOF持久化
11.1 AOF持久化的实现 命令追加 当AOF持久化处于开启状态时,服务器执行完一个写命令之后,会以协议格式将被执行的写明了追加到服务器状态的aof_buf缓冲区 struct redisServe ...
- 第二部分之AOF持久化(第十一章)
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态的.被写入AOF文件的所有命令都是以Redis的命令请求协议格式(纯文本)保存的. 一,AOF持久化的实现 1.命令追加 当AOF持 ...
- redis基础:redis下载安装与配置,redis数据类型使用,redis常用指令,jedis使用,RDB和AOF持久化
知识点梳理 课堂讲义 课程计划 1. REDIS 入 门 (了解) (操作) 2. 数据类型 (重点) (操作) (理解) 3. 常用指令 (操作) 4. Jedis (重点) (操作) ...
- Redis详解(七)------ AOF 持久化
上一篇文章我们介绍了Redis的RDB持久化,RDB 持久化存在一个缺点是一定时间内做一次备份,如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失).对于数据完整性要求很严 ...
- 使用AOF持久化文件实现还原Redis数据库并得到RDB持久化文件
目录 1 编写本文的初衷 2 具体实施 2.1 Redis持久化概念简介 2.2 获取指定Redis的AOF持久化文件 2.3 把Redis的持久化AOF文件转换为RDB文件 1 编写本文的初衷 因为 ...
- MySQL性能调优与架构设计——第11章 常用存储引擎优化
第11章 常用存储引擎优化 前言: MySQL 提供的非常丰富的存储引擎种类供大家选择,有多种选择固然是好事,但是需要我们理解掌握的知识也会增加很多.每一种存储引擎都有各自的特长,也都存在一定的短处. ...
- redis 笔记03 RDB 持久化、AOF持久化、事件、客户端
RDB 持久化 1. RDB文件用于保存和还原Redis服务器所有数据库中的所有键值对数据. 2. SAVE命令由服务器进程直接执行保存操作,所以该命令会阻塞服务器. 3. BGSAVE由子进程执行保 ...
- Redis实现之AOF持久化
AOF持久化 除了RDB持久化功能之外,Redis还提供了AOF(Append Only File)持久化功能,与RDB持久化通过保存数据库中的键值对来记录数据库状态不同,AOF持久化是通过保存Red ...
- redis源码分析(四)--aof持久化
Redis aof持久化 Redis支持两种持久化方式:rdb与aof,上一篇文章中已经大致介绍了rdb的持久化实现,这篇文章主要介绍aof实现. 与rdb方式相比,aof会使用更多的存储空间,因为它 ...
随机推荐
- MySQL指令笔记
-- 双中划线+空格: 单行注释, 与#相同 -- 链接数据库 mysql.exe -h localhost -P3306 -uroot -p -- 查看服务器的对外处理字符集 show variab ...
- Aurelia binding
今天介绍一下使用Aurelia binding 模块绑定HTML属性/事件的方式.我们依然使用之前创建的代码例子. Aurelia binding 绑定属性或者方法的通用模式就是 XXX.comman ...
- angularJs学习笔记-入门
1.angularJs简介 angularJs是一个MV*的javascript框架(Model-View-Whatever,不管是MVVM还是MVC,统归MDV(model drive view)) ...
- 关于购物车添加按钮的动画(vue.js)
来自:https://segmentfault.com/a/1190000009294321 (侵删) git 源码地址 https://github.com/ustbhuangyi/vue-sel ...
- 小tips:JS之浅拷贝与深拷贝
浅拷贝: function extendCopy(p) { var c = {}; for (var i in p) { c[i] = p[i]; } return c; } 深拷贝: functio ...
- MongoDB日志文件过大的解决方法
MongoDB的日志文件在设置 logappend=true 的情况下,会不断向同一日志文件追加的,时间长了,自然变得非常大. 解决如下:(特别注意:启动的时候必须是--logpath指定了log路径 ...
- iOS------教你如何APP怎么加急审核
苹果的加急审核如何使用呢? 在iTunesconnect页面,点击右上角的“?”图标,在弹出菜单中选择“联系我们”, 联系我们 然后在Contact Us页面,选择“App Review” —> ...
- Python对象相关内置函数
针对一个对象,通过以下几个函数,可以获取到该对象的一些信息. 1.type() ,返回某个值的类型 >>> type() <class 'int'> >>&g ...
- eclipse安装其他颜色主题包
eclipse安装其他颜色主题包: 用Help-Install new software安装的时候,work with的URL是 http://eclipse-color-theme.github.c ...
- 「Android」 基于Binder通信的C/S架构体系认知
C/S架构(Client/Server,即客户机/服务器模式)分为客户机和服务器两层:第一层是在客户机系统上结合了表示与业务逻辑,第二层是通过网络结合了数据库服务器.简单的说就是第一层是用户表示层,第 ...