python-PyQuery详解


PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQuery 是 Python 仿照 jQuery 的严格实现。语法与 jQuery 几乎完全相同,所以不用再去费心去记一些奇怪的方法了。
官网地址:http://pyquery.readthedocs.io/en/latest/
jQuery参考文档: http://jquery.cuishifeng.cn/
初始化
初始化的时候一般有三种传入方式:传入字符串,传入url,传入文件
字符串初始化
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
''' from pyquery import PyQuery as pq
doc = pq(html)
print(doc)
print('--------------------')
print(type(doc))
print('--------------------')
print(doc('li'))
结果如下:
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
--------------------
<class 'pyquery.pyquery.PyQuery'>
--------------------
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
由于PyQuery写起来比较麻烦,所以我们导入的时候都会添加别名:
from pyquery import PyQuery as pq
这里我们可以知道上述代码中的doc其实就是一个pyquery对象,我们可以通过doc可以进行元素的选择,其实这里就是一个css选择器,所以CSS选择器的规则都可以用,直接doc(标签名)就可以获取所有的该标签的内容,如果想要获取class 则doc('.class_name'),如果是id则doc('#id_name')....
URL初始化
from pyquery import PyQuery as pq doc = pq(url="http://www.baidu.com",encoding='utf-8')
print(doc('head'))
文件初始化
from pyquery import PyQuery as pq doc = pq(filename='demo.html')
print(doc('li'))
我们在pq()这里可以传入url参数也可以传入文件参数,当然这里的文件通常是一个html文件,例如:pq(filename='index.html')
基本的CSS选择器
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('#container .list li'))
结果:
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
li 不一定是 .list 的子节点,但一定是子孙节点
这里我们需要注意的一个地方是doc('#container .list li'),这里的三者之间的并不是必须要挨着,只要是层级关系就可以,下面是常用的CSS选择器方法:
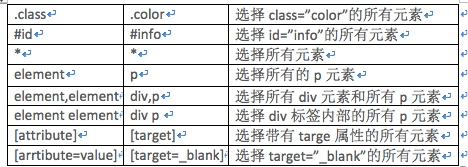
查找元素
子元素
children,find
代码例子:
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
print(type(items))
print('------------------------')
print(items)
print('------------------------')
lis = items.find('li')
print(type(lis))
print('------------------------')
print(lis)
print('------------------------')
运行结果如下:
<class 'pyquery.pyquery.PyQuery'>
------------------------
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul> ------------------------
<class 'pyquery.pyquery.PyQuery'>
------------------------
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li> ------------------------
从结果里我们也可以看出通过pyquery找到结果其实还是一个pyquery对象,可以继续查找,上述中的代码中的items.find('li') 则表示查找ul里的所有的li标签
当然这里通过children可以实现同样的效果,并且通过.children方法得到的结果也是一个pyquery对象
li = items.children()
print(type(li))
print(li)
同时在children里也可以用CSS选择器
li2 = items.children('.active')
print(li2)
父元素
parent,parents方法
通过.parent就可以找到父元素的内容,例子如下:
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()
print(type(container))
print(container)
通过.parents就可以找到祖先节点的内容,例子如下:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
parents = items.parents()
print(type(parents))
print(parents)
结果如下:从结果我们可以看出返回了两部分内容,一个是的父节点的信息,一个是父节点的父节点的信息即祖先节点的信息
<class 'pyquery.pyquery.PyQuery'>
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div><div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
同样我们通过.parents查找的时候也可以添加css选择器来进行内容的筛选
parent = items.parents('.wrap')
print(parent)
结果:
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
兄弟元素
siblings
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings())
结果:
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0">first item</li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
代码中doc('.list .item-0.active') 中的.tem-0和.active是紧挨着的,所以表示是并列的关系,这样满足条件的就剩下一个了:thired item的那个标签了
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings('.active'))
结果:
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
这样在通过.siblings就可以获取所有的兄弟标签,当然这里是不包括自己的
同样的在.siblings()里也是可以通过CSS选择器进行筛选
遍历
单个元素
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li) lis = doc('li').items()
print(type(lis))
for li in lis:
print(type(li))
print(li)
运行结果如下:从结果中我们可以看出通过items()可以得到一个生成器,并且我们通过for循环得到的每个元素依然是一个pyquery对象。
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> --------------------------
<class 'generator'>
<class 'pyquery.pyquery.PyQuery'>
<li class="item-0">first item</li> <class 'pyquery.pyquery.PyQuery'>
<li class="item-1"><a href="link2.html">second item</a></li> <class 'pyquery.pyquery.PyQuery'>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <class 'pyquery.pyquery.PyQuery'>
<li class="item-1 active"><a href="link4.html">fourth item</a></li> <class 'pyquery.pyquery.PyQuery'>
<li class="item-0"><a href="link5.html">fifth item</a></li>
获取信息
获取属性
pyquery对象.attr(属性名)
pyquery对象.attr.属性名
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.attr('href'))
print(a.attr.href)
结果:
<a href="link3.html"><span class="bold">third item</span></a>
link3.html
link3.html
所以这里我们也可以知道获得属性值的时候可以直接a.attr(属性名)或者a.attr.属性名
获取文本
在很多时候我们是需要获取被html标签包含的文本信息,通过.text()就可以获取文本信息
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.text())
结果:
<a href="link3.html"><span class="bold">third item</span></a>
third item
获取html
我们通过.html()的方式可以获取当前标签所包含的html信息,例子如下:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
print(‘------------------’)
print(li.html())
结果如下:
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> -------------------
<a href="link3.html"><span class="bold">third item</span></a>
DOM操作
addClass、removeClass
熟悉前端操作的话,通过这两个操作可以添加和删除属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
print('---------------')
li.removeClass('active')
print(li)
print('---------------')
li.addClass('active')
print(li)
结果:
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> ---------------
<li class="item-0"><a href="link3.html"><span class="bold">third item</span></a></li> ---------------
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
attr,css
同样的我们可以通过attr给标签添加和修改属性,
如果之前没有该属性则是添加,如果有则是修改
我们也可以通过css添加一些css属性,这个时候,标签的属性里会多一个style属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
print('---------------')
li.attr('name', 'link')
print(li)
print('---------------')
li.css('font-size', '14px')
print(li)
结果如下:
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> ---------------
<li class="item-0 active" name="link"><a href="link3.html"><span class="bold">third item</span></a></li> ---------------
<li class="item-0 active" name="link" style="font-size: 14px"><a href="link3.html"><span class="bold">third item</span></a></li>
remove
有时候我们获取文本信息的时候可能并列的会有一些其他标签干扰,这个时候通过remove就可以将无用的或者干扰的标签直接删除,从而方便操作
html = '''
<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
print('----------------')
wrap.find('p').remove()
print(wrap.text())
结果如下:
Hello, World
This is a paragraph.
-----------------
Hello, World
pyquery中DOM的其他api操作参考:
http://pyquery.readthedocs.io/en/latest/api.html
伪类选择器
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('li:first-child') #获取第一个li标签
print(li)
print('-----------------------')
li = doc('li:last-child') #获取最后一个li标签
print(li)
print('-----------------------')
li = doc('li:nth-child(2)') #获取第二个li标签 计数从0开始
print(li)
print('-----------------------')
li = doc('li:gt(2)') #获取比二大的li标签
print(li)
print('-----------------------')
li = doc('li:nth-child(2n)') #获取偶数的li标签
print(li)
print('-----------------------')
li = doc('li:contains(second)') #获取包含second文本的li标签
print(li)
结果:
<li class="item-0">first item</li> -----------------------
<li class="item-0"><a href="link5.html">fifth item</a></li> -----------------------
<li class="item-1"><a href="link2.html">second item</a></li> -----------------------
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li> -----------------------
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li> -----------------------
<li class="item-1"><a href="link2.html">second item</a></li>
更多CSS选择器可以查看 http://www.w3school.com.cn/css/index.asp
原文:https://www.cnblogs.com/zhaof/p/6935473.html
python-PyQuery详解的更多相关文章
- Python闭包详解
Python闭包详解 1 快速预览 以下是一段简单的闭包代码示例: def foo(): m=3 n=5 def bar(): a=4 return m+n+a return bar >> ...
- [转] Python Traceback详解
追莫名其妙的bugs利器-mark- 转自:https://www.jianshu.com/p/a8cb5375171a Python Traceback详解 刚接触Python的时候,简单的 ...
- python 数据类型详解
python数据类型详解 参考网址:http://www.cnblogs.com/linjiqin/p/3608541.html 目录1.字符串2.布尔类型3.整数4.浮点数5.数字6.列表7.元组8 ...
- Python 递归函数 详解
Python 递归函数 详解 在函数内调用当前函数本身的函数就是递归函数 下面是一个递归函数的实例: 第一次接触递归函数的人,都会被它调用本身而搞得晕头转向,而且看上面的函数调用,得到的结果会 ...
- python线程详解
#线程状态 #线程同步(锁)#多线程的优势在于可以同时运行多个任务,至少感觉起来是这样,但是当线程需要共享数据时,可能存在数据不同步的问题. #threading模块#常用方法:'''threadin ...
- python数据类型详解(全面)
python数据类型详解 目录1.字符串2.布尔类型3.整数4.浮点数5.数字6.列表7.元组8.字典9.日期 1.字符串1.1.如何在Python中使用字符串a.使用单引号(')用单引号括起来表示字 ...
- Python Collections详解
Python Collections详解 collections模块在内置数据结构(list.tuple.dict.set)的基础上,提供了几个额外的数据结构:ChainMap.Counter.deq ...
- python生成器详解
1. 生成器 利用迭代器(迭代器详解python迭代器详解),我们可以在每次迭代获取数据(通过next()方法)时按照特定的规律进行生成.但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记 ...
- 转 python数据类型详解
python数据类型详解 目录 1.字符串 2.布尔类型 3.整数 4.浮点数 5.数字 6.列表 7.元组 8.字典 9.日期 1.字符串 1.1.如何在Python中使用字符串 a.使用单引号(' ...
- python多线程详解
目录 python多线程详解 一.线程介绍 什么是线程 为什么要使用多线程 二.线程实现 threading模块 自定义线程 守护线程 主线程等待子线程结束 多线程共享全局变量 互斥锁 递归锁 信号量 ...
随机推荐
- The Microsoft Distributed Transaction Coordinator (MS DTC) has cancelled the distributed transaction.
同事反馈一个系统在运行一个存储过程时遇到了下面错误: Msg 1206, Level 18, State 169, Procedure xxxxxx, Line 118The Microsoft Di ...
- JMeter—常见问题(十四)
参考<全栈性能测试修炼宝典JMeter实战>第十五章 JMeter常见问题 1.无法产生负载 注意检查各元件是否时禁用状态.JMeter在运行时是以数形式加载各种元件的,如果父节点被禁用, ...
- SQL语句(floor、ceiling和round以及left和right)
前言:个人认为命令没有必要记,学过的知识总结一下,用到了可以快速找到派上用场.用的多了,自然会记住,但是一定要理解每一个字符代表的是什么,多一个少一个会怎么样 要点概述 floor 和ceiling和 ...
- python轻量级数据存储
python为开发者提供了一个轻量级的数据存储方式shelve,对于一些轻量数据,使用shelve是个比较不错的方式.对于shelve,可以看成是一个字典,它将数据以文件的形式存在本地.下面介绍具体用 ...
- jQuery中 对标签元素操作(1)
一:创建元素节点(添加) 创建元素节点并且把节点作为元素的子节点添加到DOM树上 append(): 在元素下添加元素 用法:$("id").append(" ...
- 实现Github和Coding仓库等Git服务托管更新
如何使Github.Coding.Gitee 码云 同时发布更新,多个不同Git服务器之间同时管理部署发布提交 缘由 因为在Github上托管的静态页面访问加载速度较为缓慢,故想在Coding上再建一 ...
- IIS下MySQL停止和启动的方法
mysql服务的启动与停止:点击开始--运行,输入services.msc , 在弹出的服务窗口中,找到mysql服务,直接点击左侧对应 的就可以了 如下图所示:
- February 12th, 2018 Week 7th Monday
One man's fault is another man's lesson. 前车之覆,后车之鉴. We make mistakes every day, large or small, fail ...
- Cesium实现键盘控制镜头效果
w-前进 a-左转 d-右转 s-后退 q-上仰 鼠标左键按住左右移动更换角度 html代码如下: <div id="cesiumContainer" style= ...
- Spring的jdbc模板1
Spring是EE开发的一站式框架,有EE开发的每一层解决方案.Spring对持久层也提供了解决方案:ORM模块和jdbc模块,ORM模块在整合其他框架的时候使用 Spring提供了很多的模板用于简化 ...