python爬虫之Splash使用初体验
Splash是什么:
Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python实现的,同时使用Twisted和QT。Twisted(QT)用来让服务具有异步处理能力,以发挥webkit的并发能力。
为什么要有Splash:
为了更加有效的制作网页爬虫,由于目前很多的网页通过javascript模式进行交互,简单的爬取网页模式无法胜任javascript页面的生成和ajax网页的爬取,同时通过分析连接请求的方式来落实局部连接数据请求,相对比较复杂,尤其是对带有特定时间戳算法的页面,分析难度较大,效率不高。而通过调用浏览器模拟页面动作模式,需要使用浏览器,无法实现异步和大规模爬取需求。鉴于上述理由Splash也就有了用武之地。一个页面渲染服务器,返回渲染后的页面,便于爬取,便于规模应用。
安装条件:
操作系统要求:
Docker for Windows requires Windows 10 Pro or Enterprise version 10586, or Windows server 2016 RTM to run
安装:
首先点击下面链接,从docker官网上下载windows下的docker进行安装,不过请注意系统要求是**windows1064位 pro及以上版本或者教育版
官网下载:https://store.docker.com/editions/community/docker-ce-desktop-windows
安装包下载完成后以管理员身份运行。
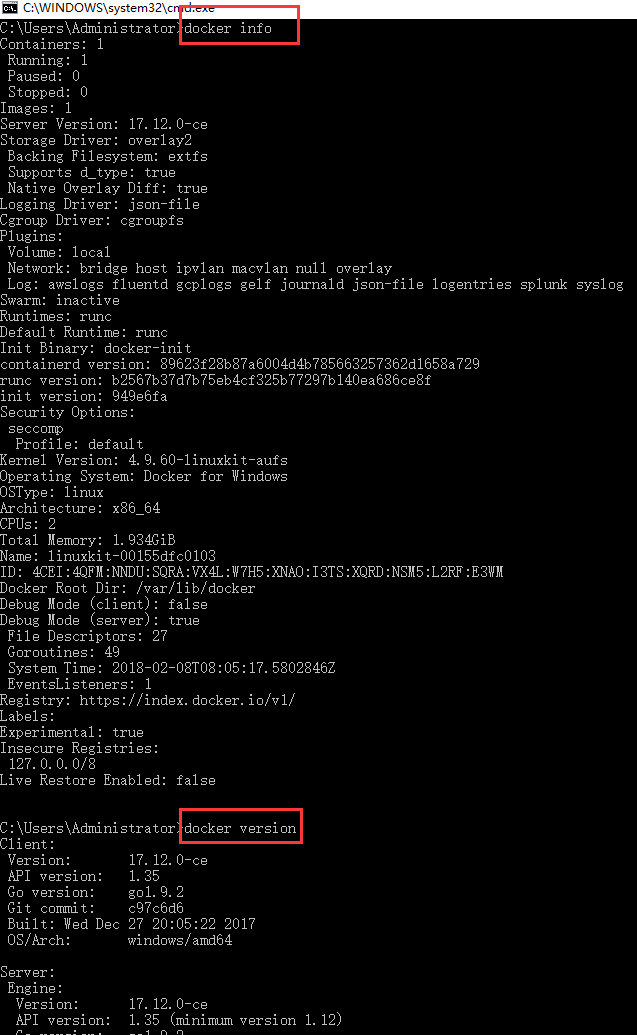
查看信息:
#docker info
#docker version
查看启动的容器

在docker中下载安装Splash镜像,并安装
#docker pull scrapinghub/splash
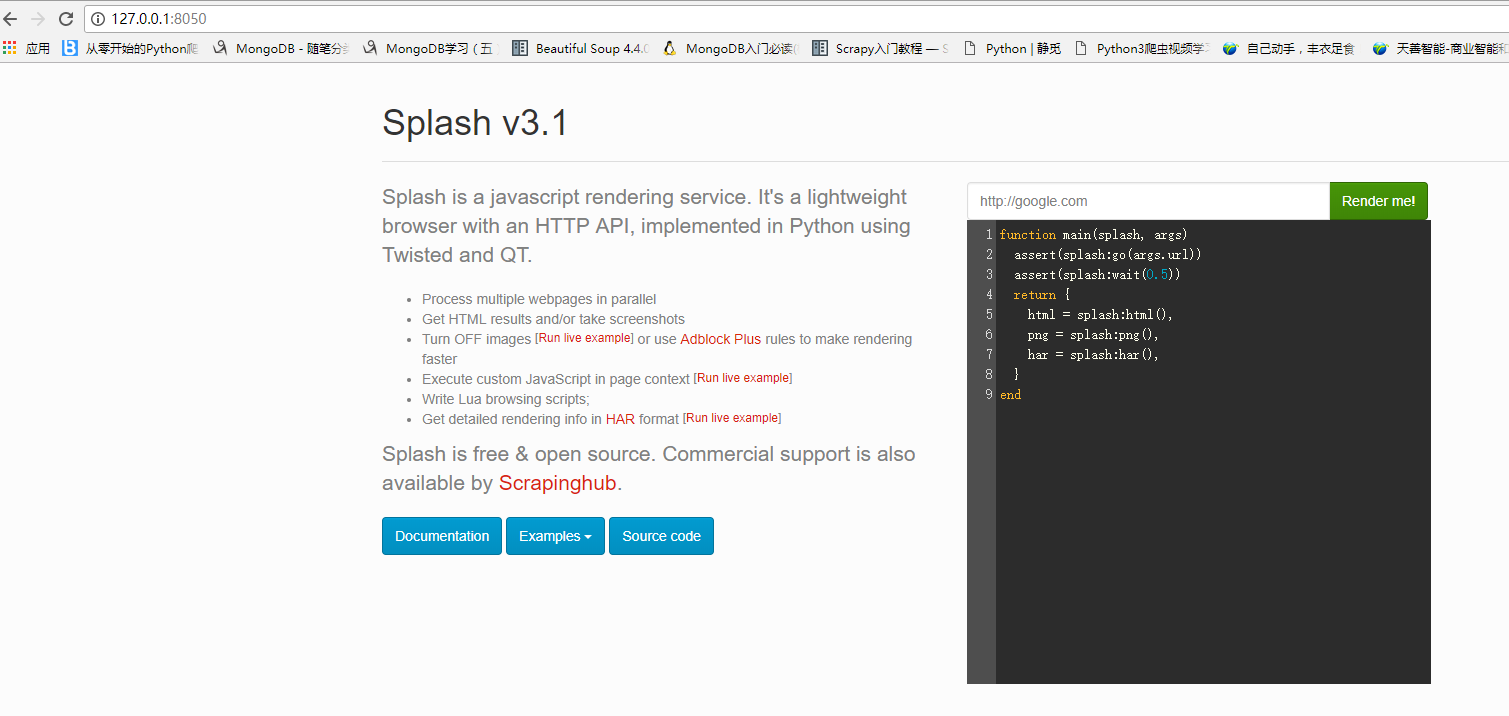
启动splash服务
#启动splash服务,并通过http,https,telnet提供服务
#通常一般使用http模式 ,可以只启动一个8050就好
#Splash 将运行在 0.0.0.0 at ports 8050 (http), 8051 (https) and 5023 (telnet).
docker run -p 5023:5023 -p 8050:8050 -p 8051:8051 scrapinghub/splash
参考链接:https://www.jianshu.com/p/4052926bc12c
Centos7安装:
准备工作
删除原来的docker包,一般情况下不用,保险起见,最好按流程走一下
$ sudo yum -y remove docker docker-common container-selinux删除docker的selinux 同上
$ sudo yum -y remove docker-selinux开始安装了
使用yum 安装yum-utils
$ sudo yum install -y yum-utils增加docker源
$ sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo查看docker源是否可用
$ sudo yum-config-manager --enable docker-ce-edge
enable 为True就行创建缓存
$ sudo yum makecache fast使用yum安装
docker现在分为两个版本 EE(企业版) CE(社区版),这里我们选择CE版.
$ sudo yum install docker-ce启动docker
$ sudo systemctl start docker启动一个helloword
$ sudo docker run hello-world这条命令会下载一个测试镜像,并启动一个容器,输出hello world 并退出,如果正常说明docker安装成功.
参考地址:https://www.cnblogs.com/colder219/p/6679255.html
使用
1、配置splash服务(以下操作全部在settings.py):
1)添加splash服务器地址:
SPLASH_URL = 'http://localhost:8050'
2)将splash middleware添加到DOWNLOADER_MIDDLEWARE中:
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
3)Enable SplashDeduplicateArgsMiddleware:
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
4)Set a custom DUPEFILTER_CLASS:
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
5)a custom cache storage backend:
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
案例:
import scrapy
from scrapy_splash import SplashRequest class TbtaobaoSpider(scrapy.Spider):
name = "tbtaobao"
allowed_domains = ["www.taobao.com"]
start_urls = ['https://s.taobao.com/search?q=坚果&s=880&sort=sale-desc'] def start_requests(self):
for url in self.start_urls:
# yield Request(url,dont_filter=True)
yield SplashRequest(url, self.parse, args={'wait': 0.5}) def parse(self, response):
print(response.text)
python爬虫之Splash使用初体验的更多相关文章
- python第十七天-----Django初体验
Django是一个MTV框架 M:models(数据库) T:templates(放置html模版) V:views(处理用户请求) 那么传说中的MVC框架又是什么呢? M:models(数据库) V ...
- [转]Python爬虫框架--pyspider初体验
标签: python爬虫pyspider 2015-09-05 10:57 9752人阅读 评论(0) 收藏 举报 分类: Python(8) 版权声明:本文为博主原创文章,未经博主允许不得转载. ...
- 【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 【Go 入门学习】第一篇关于 Go 的博客--Go 爬虫初体验
一.写在前面 其实早就该写这一篇博客了,为什么一直没有写呢?还不是因为忙不过来(实际上只是因为太懒了).不过好了,现在终于要开始写这一篇博客了.在看这篇博客之前,可能需要你对 Go 这门语言有些基本的 ...
- Python导出Excel为Lua/Json/Xml实例教程(二):xlrd初体验
Python导出Excel为Lua/Json/Xml实例教程(二):xlrd初体验 相关链接: Python导出Excel为Lua/Json/Xml实例教程(一):初识Python Python导出E ...
- python窗体——pyqt初体验
连续两周留作业要写ftp的作业,从第一周就想实现一个窗体版本的,但是时间实在太短,qt零基础选手表示压力很大,幸好又延长了一周时间,所以也就有了今天这篇文章...只是为了介绍一些速成的方法,还有初学者 ...
- ipython及Python初体验
阅读目录: Python环境体验 Python编辑器 ipython安装 Python提示符 Python初体验 print和变量 变量操作 内建函数:方法 数学运算:简单算术.随机数 关于模块 一. ...
- Python基础学习参考(一):python初体验
一.前期准备 对于python的学习,首先的有一个硬件电脑,软件python的运行环境.说了一句废话,对于很多初学者而言,安装运行环境配置环境变量的什么的各种头疼,常常在第一步就被卡死了,对于pyth ...
随机推荐
- css3 object-fit详解
上传头像的时候遇到了头像变形的问题,最后通过object-fit: cover完美解决了.这个CSS属性可以达到最佳最完美的居中自动剪裁图片的功能. object-fit理解 CSS3 backgro ...
- ubantu下装Docker
Docker 要求 Ubuntu 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的 Ubuntu 版本是否支持 Docker. 通过 uname -r 命令查看你当前的内核版本 unam ...
- AJAX方式发送远程请求报错:No 'Access-Control-Allow-Origin' header
AJAX GET方式发送远程请求,chrome开发者工具console中报错:XMLHttpRequest cannot load http://www.shikezhi.com/ajax/getDa ...
- Y7000 (1)安装ubuntu1604遇到的问题
1安装系统 分区的时候 /boot 不再是引导分区 换成 “为系统bois保留的分区” 这个分区取代 /boot 2第一次进系统没有图形界面 在刚开机 ubuntu系统时 按e 在splash后面空 ...
- 微信硬件平台(七) 设备控制控制面板-网页sokect-mqtt长连接
给微信硬件设备添加我们自己的控制面板. 主要问题: 1 要保证长连接,这样面板可以实时交互阴间设备,http一次性的连接模式通信不行. 面板必须是网页化的,网页就可以操作交互.不用APP和小程序. 2 ...
- GitHub 优秀的 Android 开源项目 (精品)
1原文地址为 http://www.trinea.cn/android/android-open-source-projects-view/,作者Trinea Android开源项目系列汇总已完成,包 ...
- Linux如何查看端口状态
netstat命令各个参数说明如下: -t : 指明显示TCP端口 -u : 指明显示UDP端口 -l : 仅显示监听套接字(所谓套接字就是使应用程序能够读写与收发通讯协议(protocol)与资料的 ...
- 4939-Agent2-洛谷
传送门 emm... 这次没有原题了 (因为我懒) 就是一道很简单的树状数组 真的很简单很简单 只用到了一点点的差分 注意注意: 只用树状数组,不用差分会t掉的 所以.. 我不仅t了 还wa了 emm ...
- item 23: 理解std::move和std::forward
本文翻译自<effective modern C++>,由于水平有限,故无法保证翻译完全正确,欢迎指出错误.谢谢! 博客已经迁移到这里啦 根据std::move和std::forward不 ...
- odoo11 安装python ldap
最近在研究odoo11使用ldap登录的问题,本来自己想着怎么开发,无意间在odoo11代码中看到auth_ldap的模块,原来框架已经考虑到了这个,简单研究了代码之后,理解了其大概的登录处理过程,此 ...