今天开始学习模式识别与机器学习Pattern Recognition and Machine Learning (PRML),章节5.1,Neural Networks神经网络-前向网络。
话说上一次写这个笔记是13年的事情了···那时候忙着实习,找工作,毕业什么的就没写下去了,现在工作了有半年时间也算稳定了,我会继续把这个笔记写完。其实很多章节都看了,不过还没写出来,先从第5章开始吧,第2-4章比较基础,以后再补!
第5章 Neural Networks
在第3章和第4章,我们已经学过线性的回归和分类模型,这些模型由固定的基函数(basis functions)的线性组合组成。这样的模型具有有用的解析和计算特性,但是因为维度灾难(the curse of dimensionality)(即高维数据)的问题限制了它们的实际的适用性。为了把这些模型应用在大数据的问题中,我们必须根据数据来调整这些基函数。
在第七章中会讨论SVM,是一个非常著名和有效的分类方法。SVM有其独特的方法理论,并且其一个重要的优点是:虽然涉及非线性优化,但是SVM本身的目标函数依然是convex的。在本章中不具体展开,第七章中有详述。
另外一个办法是虽然提前固定基函数的数量,但是允许它们在在训练的过程中调整其参数,也就是说基函数是可以调整的。在模式识别领域,该方法最为典型的算法是本章节将会讨论 的前向神经网络(feed-forward neural network,后面简称NN),或者称为多层感知器(multilayer perceptron)。(注:这里多层模型是连续的,如sigmoid函数,而perceptron方法原本是不连续的;perceptron方法在PRML书中没有介绍,后面根据其他的资料单独写一篇)。很多情况下,NN训练的模型相比具有相同泛化能力的SVM模型更紧凑(注:我理解是参数更少),因此跟容易评估,但是代价是NN的基函数不再是训练参数的convex函数。在实际中,在训练中花费大量计算资源以得到紧凑的模型,来快速处理新数据的情况是可以接受的。
接下来我们会看到,为了得到神经网络的参数,我们本质上是做了一个最大似然估计,其中涉及非线性优化问题。这需要对log似然函数针对参数求导数,我们后面会讲一下误差反向传播算法(error backpropagation,BP),以及BP算法的一些扩展方法。
5.1 Feed-forward Network Functions
在第3章和第4章中通论的线性模型,是基于固定的基函数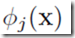 的线性组合,形式为:
的线性组合,形式为:
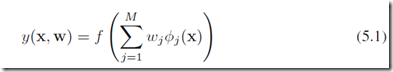
其中,f()在分类问题中是一个非线性的激励函数,而在回归模型中是单位矩阵identity。我们的目标是把上面的模型中的基函数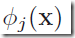 变得依赖于参数,并且在训练的时候这些参数以及上面的wj都是可调整的。基函数的形式自然有很多种,神经网络的基函数采用和(5.1)相同形式,因此每个基函数本事就是一个关于input线性组合的非线性函数,线性组合中的参数是可以调整的参数。这就是基本的神经网络的思想,由一系列函数转换组成:首先我们构造针对输入变量
变得依赖于参数,并且在训练的时候这些参数以及上面的wj都是可调整的。基函数的形式自然有很多种,神经网络的基函数采用和(5.1)相同形式,因此每个基函数本事就是一个关于input线性组合的非线性函数,线性组合中的参数是可以调整的参数。这就是基本的神经网络的思想,由一系列函数转换组成:首先我们构造针对输入变量 的M个线性函数
的M个线性函数
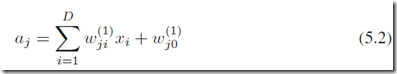
其中j=1,…,M,上标(1)表示参数是神经网络第一层的参数(input不算层)。我们称参数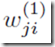 为权重weights,而参数
为权重weights,而参数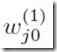 是截距biases。
是截距biases。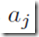 称为激励(activation),会通过一个可导的非线性激励函数h()转换成:
称为激励(activation),会通过一个可导的非线性激励函数h()转换成:

这些M个函数值就是(5.1)中的基函数的输出,在神经网络模型中,称之为隐含层单元(hidden units)。非线性激励函数h()通常的选择是sigmoid函数或者是tanh函数。根据(5.1),这些值会再一次线性组合成output单元的激励值,

其中k=1,…,K,K是output单元数量。这个转换是神经网络的第二层,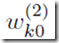 是bias参数。最终,这些output单元的激励值会再由合适的激励函数转换成合适的最终输出
是bias参数。最终,这些output单元的激励值会再由合适的激励函数转换成合适的最终输出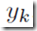 。和上面的提到的类似,如果是要做回归问题,激励函数我们选择identity,即
。和上面的提到的类似,如果是要做回归问题,激励函数我们选择identity,即 ;如果是做多个2分类问题,我们采用logistic sigmoid function:
;如果是做多个2分类问题,我们采用logistic sigmoid function:
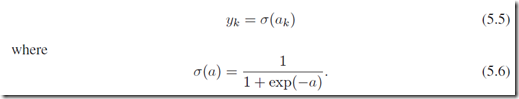
如果是多个类别的分类问题,我们采用softmax函数,见PRML书公式(4.62)。
于是,我们把所有阶段都组合起来,可以得到总体的神经网络函数(采用sigmoid output单元,两层网络,如下面图5.1):
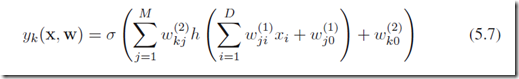
因此,神经网络模型就是一个非线性函数,从输入的变量集合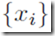 到输出的变量集合
到输出的变量集合 ,并且由可调整的参数向量w来控制。网络的结构可以见图5.1,整个网络是向前传播的。
,并且由可调整的参数向量w来控制。网络的结构可以见图5.1,整个网络是向前传播的。
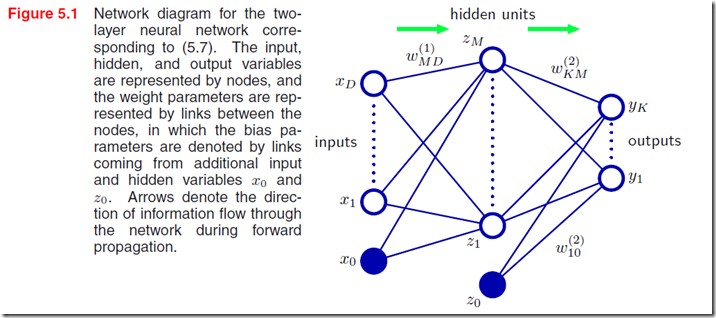
我们可以专门增加x0=1和z0=1两个变量输入,这样可以把bias(偏移、截距)项合并到累加里面,简化了表达,因此可以得到:

以及:
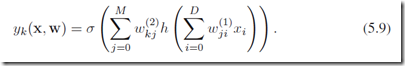
下面的推导会用(5.9)的形式。如果看过第四章关于感知机(perception)的介绍,就会发现上面的形式就相当于用了两层的感知机模型,也是因为这样,神经网络模型也被称为多层感知机(the multilayer perceptron, or MLP)模型。区别是感知机模型采用输出0/1的步长函数(step-function),而NN采用连续的如sigmoid这样的非线性函数在中间的隐藏层单元,说明NN对于参数是可导的,这一点在NN模型的训练中很重要。
如果隐层单元的激励函数都是采用线性的,那么不管连续几层,最终模型还是一个线性模型。而且如果隐层单元比输入单元或者输出单元少的话,那么就会有信息损失,类似于在隐层做了一次数据降维。目前来看,很少有人关注多层线性单元的神经网络模型。上面图5.1是一个最为典型的NN模型结构,它可以很容易的得到拓展——继续把输出层作为隐层,并增加新的层次,采用和之前一样的函数传递方法。业界在称呼NN模型的层次上有一些统一,有些人把图5.1叫做3层网络,而在本书中更推荐这个模型为2层,因为参数可调的层只有2层。
另外一种对模型的泛化方法是像图5.2这样,input的节点可以直接连接到output,并不一定需要一层一层传递。(注:这样的NN结构更广义,优化的时候BP也一样可以应付,但是是怎么产生这些越层连接的呢?这一点书中没有展开,不知道这样的模型在深度网络结构中有没有应用呢?有同学看到一定要留言告知哈~)
另外一个很重要的性质,NN模型可以是稀疏的,事实上大脑也是这样的,不是所有的神经元都是活跃的,只有非常少的一小部分会活跃,不同层的神经元之间也不可能是全连接的。后面再5.5.6节中,我们将看到卷积神经网络采用的稀疏网络结构的例子。
我们自然可以设计出更复杂的网络结构,不过一般来说我们都限定网络结构为前向网络,也就是说不存在封闭的有向环,可以见图5.2表示的那样,每一个隐层单元或者是输出单元可以通过下面计算得到:

于是,当有输入时,网络中的所有单元都会逐步被影响进而激活(也有可能不激活)。神经网络模型有很强的近似拟合功能,因此也被称为universal approximators.
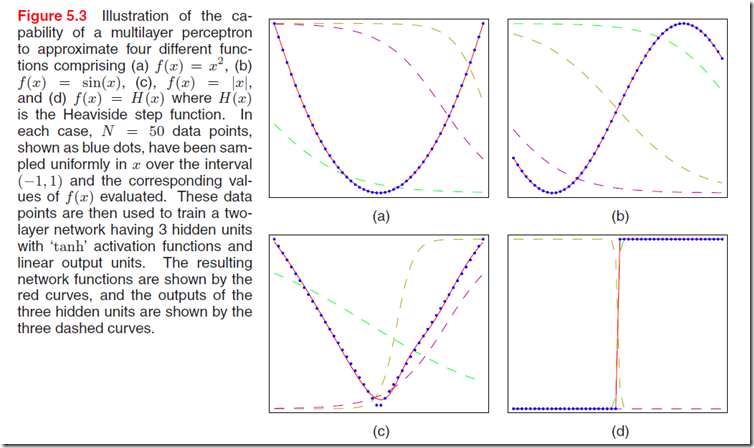
事实上两层的NN模型就可以拟合任意function,只要隐层单元足够多以及参数训练的足够好。下面的图5.3说明了NN模型的拟合能力。解释请看图左边的描述。
5.1.1 权值空间的对称性
这是前向网络一个有趣的性质,比如我们来看图5.1这样的典型两层网络,考察一个隐层单元,如果我们把它的输入参数的符号全部取反,以tanh函数为例,我们会得到相反的激励函数值,即tanh(−a) = −tanh(a)。然后把这个单元所有的输出连接权重也都取反,我们又可以得到相同的output输出,也就是说,实际上有两组不同的权值取值可以得到相同的output输出。如果有M个隐层单元,实际上有2M种等价的参数取值方案。
另外,如果我们把隐层的两个单元的输入输出权重互相间调换一下,那么整个网络最终output是一样的,也就是说任何一种权重的取值组合是所有M!中的一种。可见上面这样的神经网络居然有M!2M的权值对称性可能。这样的性质在很多激励函数都是有的,但是一般来说我们很少关心这一点。
今天开始学习模式识别与机器学习Pattern Recognition and Machine Learning (PRML),章节5.1,Neural Networks神经网络-前向网络。的更多相关文章
- 今天开始学模式识别与机器学习(PRML),章节5.1,Neural Networks神经网络-前向网络。
今天开始学模式识别与机器学习Pattern Recognition and Machine Learning (PRML),章节5.1,Neural Networks神经网络-前向网络. 话说上一次写 ...
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节5.2-5.3,Neural Networks神经网络训练(BP算法)
转载请注明出处:http://www.cnblogs.com/xbinworld/p/4265530.html 这一篇是整个第五章的精华了,会重点介绍一下Neural Networks的训练方法——反 ...
- Pattern Recognition And Machine Learning读书会前言
读书会成立属于偶然,一次群里无聊到极点,有人说Pattern Recognition And Machine Learning这本书不错,加之有好友之前推荐过,便发了封群邮件组织这个读书会,采用轮流讲 ...
- Pattern Recognition and Machine Learning (preface translation)
前言 鉴于机器学习产生自计算机科学,模式识别却起源于工程学.然而,这些活动能被看做同一个领域的两个方面,并且他们同时在这过去的十年间经历了本质上的发展.特别是,当图像模型已经作为一个用来描述和应用概率 ...
- Pattern Recognition and Machine Learning 模式识别与机器学习
模式识别(PR)领域: 关注的是利⽤计算机算法⾃动发现数据中的规律,以及使⽤这些规律采取将数据分类等⾏动. 聚类:目标是发现数据中相似样本的分组. 反馈学习:是在给定的条件下,找到合适的动作, ...
- Pattern Recognition And Machine Learning (模式识别与机器学习) 笔记 (1)
By Yunduan Cui 这是我自己的PRML学习笔记,目前持续更新中. 第二章 Probability Distributions 概率分布 本章介绍了书中要用到的概率分布模型,是之后章节的基础 ...
- 学习笔记-----《Pattern Recognition and Machine Learning》Christopher M. Bishop
Preface 模式识别这个词,以前一直不懂是什么意思,直到今年初,才开始打算读这本广为推荐的书,初步了解到,它的大致意思是从数据中发现特征,规律,属于机器学习的一个分支. 在前言中,阐述了什么是模式 ...
- Pattern recognition and machine learning 疑难处汇总
不断更新ing......... p141 para 1. 当一个x对应的t值不止一个时,Gaussian nosie assumption就不合适了.因为Gaussian 是unimodal的,这意 ...
- Pattern Recognition and Machine Learning-01-Preface
Preface Pattern recognition has its origins in engineering, whereas machine learning grew out of com ...
随机推荐
- Python(x,y) 的 FTP 下载地址
因为 Python(x,y) 软件包托管在 Google code 上 https://code.google.com/p/pythonxy/,所以国内比较难下载. 这里推荐一个 FTP 下载地址:f ...
- Python 中的浅拷贝和深拷贝
1. 列表和字典,直接赋值,都是浅拷贝,即赋值双方指向同一地址,因为 Python 对可变对象按引用传递. >>> a = [1, 2, 3] >>> b = a ...
- RestFul风格API(Swagger)--从零开始Swagger
引言:随着技术的革新,现在的系统基本上都是前后端分离,并且在各自的道路上越走越远,而前后端之间通信或者联系的桥梁就是API,而这里基于RESTful风格的API框架就来了!欲知后事如何,客官别急,往下 ...
- Rommel - C# 浅谈 接口(Interface)的作用
鉴于网上太多太多的对C# 接口的误解,想来想去还是自己做一个完美的接口 篇章 继承"基类"跟继承"接口"都能实现某些相同的功能,但有些接口能够完成的功能是只用基 ...
- 图解HTTP,TCP,IP,MAC的关系
入门 用户发了一个HTTP的请求,想要访问我们网站的首页,这个HTTP请求被放在一个TCP报文中,再被放到一个IP数据报中,最终的目的地就是我们的115.39.19.22. 进阶 IP数据报其实是通过 ...
- .net core实践系列之SSO-跨域实现
前言 接着上篇的<.net core实践系列之SSO-同域实现>,这次来聊聊SSO跨域的实现方式.这次虽说是.net core实践,但是核心点使用jquery居多. 建议看这篇文章的朋友可 ...
- (转)C#中的那些全局异常捕获
C#中的那些全局异常捕获(原文链接:http://www.cnblogs.com/taomylife/p/4528179.html) 1.WPF全局捕获异常 public partia ...
- vue-area-linkage Vue省市区三级列表联动插件使用
官方演示地址 // v5及之后的版本 数据依赖于area_data npm i --save vue-area-linkage area-data import Vue from 'vue'; imp ...
- P66 整环的零元
R/I=0的零因子是0+I吗? 如果不是,那请问R/I的零因子是什么呢? R/I没有零因子 R/I的零元 是I中的元素定义的等价类 么 a是理想I的元素,自然也是R的元素
- [2017BUAA软工助教]团队开发阶段CheckList
alpha阶段流程与相关节点 以下流程与团队项目中个人的得分点是一一对应的,详见QA文档中"个人在团队项目的得分部分" http://www.cnblogs.com/Childis ...