shell关于文件操作
一、如何将一个十进制的整数用2进制表示出来?
echo "obase=2;50" | bc
二、Linux下经常需要删除空白行,grep,sed,awk,tr等工具均可实现
grep -v '^$' filename
sed '/^$/d' filename
awk '{if($0!="") print $0}' filename
tr -s '\n' < filename
三、shell中if 判断语句中的匹配模式
=~ 表示匹配
if [[ $slave =~ "140$" ]]
then
echo "end with 140"
fi
四、awk中split的用法
有一个文件存在两域,第一域是基因名字,第二域是别名,别名存在多个,以|分割,要求将基因名和别名一一对应,如将下图转换成下下图的结果

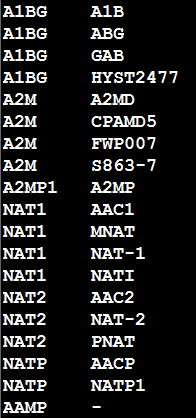
awk -F"\t" -v OFS="\t" '{if($2~/\|/){len=split($2,a,"|");for(i=1;i<=len;i++)print $1,a[i]}else print $0}' input > result
#~表示第二域匹配到|,按|分割保存到数组a
#split()返回a的长度,并遍历a
#else未匹配到|则直接输出
五、join对两个文件相同域进行合并操作
现在有两个文件,其中两个文件有部分相同的域,如何筛选出这些域相同的记录,如A,B文件如下图:
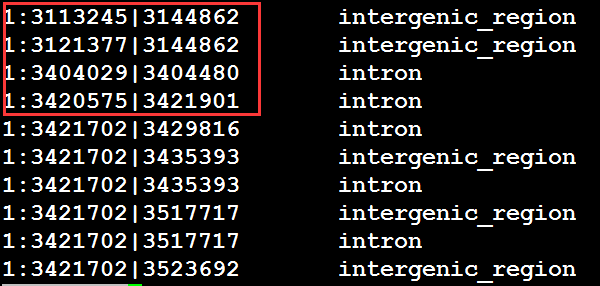

从上可以看出两个文件前四行有相同的域,那么我想把这些相同域的记录筛选出来,即前四行筛选出来,该怎么做呢?注意:join操作必须按指定的域进行排过序
join -1 1 -2 4 file_one file_two
'''
1:3113245|3144862 intergenic_region 1 3113245 3144862
1:3121377|3144862 intergenic_region 1 3121377 3144862
1:3404029|3404480 intron 1 3404029 3404480
1:3420575|3421901 intron 1 3420575 3421901
''' #-1和-2指定连接的域 join -1 4 -2 1 two one
'''
1:3113245|3144862 1 3113245 3144862 intergenic_region
1:3121377|3144862 1 3121377 3144862 intergenic_region
1:3404029|3404480 1 3404029 3404480 intron
1:3420575|3421901 1 3420575 3421901 intron
'''
六、有两个关键词,如何将这两个关键词之间的行打印出来?
: comment
file:
1
2
3
3
4
5
6
7
7
8
9
10
comment #将3和7之间的行打印出来
awk '/3/,/7/{print $0}' file
'''
3
3
4
5
6
7
'''
#可见将3和7之间的行一块儿打印出来了,其中3有2行,7只打印出一行
#如果不想打印出3和7关键词行
awk '/3/,/7/{if(i>1)print x;x=$0;i++}' file
'''
3
4
5
6
''' awk '/3/,/7/{if(i>2)print x;x=$0;i++}' file
'''
4
5
6
'''
七、awk中substr()函数使用
substr():截取字符串,返回从起始位置起,指定长度之子字符串;若未指定长度,则返回从起始位置到字符串末尾的子字符串。
格式:
substr(s,p) 返回字符串s中从p开始的后缀部分
substr(s,p,n) 返回字符串s中从p开始长度为n的后缀部分
#将fastq转换为fasta
awk '{if(NR%4 == 1){print ">" substr($0, 2)}}{if(NR%4 == 2){print}}' fastq > fasta
八、有一文件

如何根据红框中的值是否相同,将两行或者多行变成一行,GENE_ID列按逗号分隔,结果如下:

awk -F"GENE_ID=" 'BEGIN{tem=0}{split($2,array,";"); if($1!=tem){printf("\n%sGENE_ID=%s",$1,array[1]);tem=$1}else{printf(",%s",array[1])}}' paragon | sed '/^$/d'
#coding=utf-8
import sys
in_file = sys.argv[1]
#需要保存上一行的name和line
#注意输入文件bed要先排序:sort -V your_bed
name_before = ''
line_before = ''
with open(in_file) as f1:
for eachline in f1:
array = eachline.strip().split('\t')
if array[3] != name_before:
if line_before:
print line_before
gene_id = array[-1].strip().split(';')[0]
new_line = '\t'.join((array[0:-1] + [gene_id]))
name_before = array[3]
line_before = new_line else:
gene_id = array[-1].strip().split(';')[0].split('=')[-1]
line_before = line_before + ',' + gene_id #print the last line
print line_before
九、如何提取字符串中的数字部分
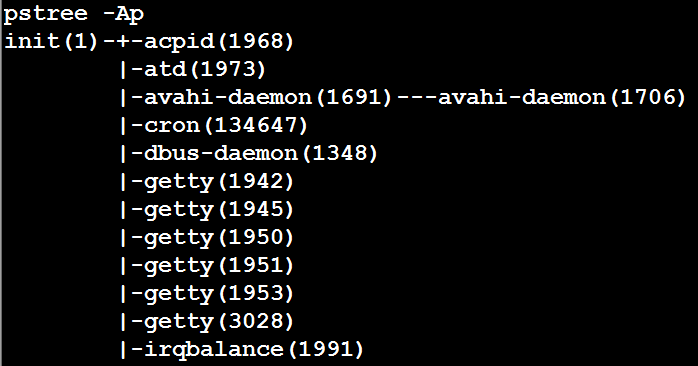
如执行上面的命令,想提取其中的数字部分:
pstree -Ap | tr -cd "[0-9])" | sed 's/)/\n/g' | less
-d表示删除,[0-9]表示所有数字,-c表示对条件取反,所以tr -cd "[0-9]"这句话的意思就是,剔除非数字的字符
十、一个文件vim编辑中文显示正常,more或者less显示乱码
执行下面的命令试试:
cat data_20190306.csv | iconv -f GBK -t UTF-8 > data_20190306_new.csv
如果vi中文乱码:
vi ~/.vimrc
#添加:set fileencodings=utf-8,gbk
如果使用python打开文件报UnicodeDecodeError错误,则可以再linux下使用file命令,查看文件编码格式,然后open时候指定encoding参数,如:
Little-endian UTF-16 Unicode text, with CRLF, CR line terminators
说明文件是utf-16编码,并且是\n\r换行
十一、windows文件转换unix文件
vi一个文件:
set ff? #显示当前文件格式
set ff=unix #设置成unix格式
set ff=dos #设置成dos格式
或者dos2unix命令,但是得先安装
shell关于文件操作的更多相关文章
- 让你提前知道软件开发(22):shell脚本文件操作
文章1部分 再了解C语言 shell脚本中的文件操作 [文章摘要] 编写shell脚本时,经常会涉及到对文件的操作,比方从文件里读取一行数据.向文件追加一行数据等. 完毕文件读写操作的方法有非常多,了 ...
- Shell脚本文件操作
Linux Shell http://baike.baidu.com/link?url=2LxUhKzlh5xBUgQrS0JEc61xi761nvCS7SHJsa1U1SkVbw3CC869AoUC ...
- Java文件操作API功能与Windows DOS命令和Linux Shell 命令类比
Java文件操作API功能与Windows DOS命令和Linux Shell 命令类比: Unix/Linux (Bash) Windows(MS-DOS) Java 进入目录 cd cd - 创建 ...
- Linux文件操作的主要接口API及相关细节
操作系统API: 1.API是一些函数,这些函数是由linux系统提供支持的,由应用层程序来使用,应用层程序通过调用API来调用操作系统中的各种功能,来干活 文件操作的一般步骤: 1.在linux系统 ...
- python 文件操作(转)
python中对文件.文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块. 得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd() 返回指定目录下的所有文件和目 ...
- python文件操作
总是记不住API.昨晚写的时候用到了这些,但是没记住,于是就索性整理一下吧: python中对文件.文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块. 得到当前工作目录,即当前Pyth ...
- Python之路第一课Day3--随堂笔记(文件操作)
一.集合的介绍 1.集合操作 集合是一个无序的,不重复的数据组合,它的主要作用如下: 去重,把一个列表变成集合,就自动去重了 关系测试,测试两组数据之前的交集.差集.并集等关系 常用操作 s = se ...
- 关于Python中的文件操作(转)
总是记不住API.昨晚写的时候用到了这些,但是没记住,于是就索性整理一下吧: python中对文件.文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块. 得到当前工作目录,即当前Pyth ...
- 关于python文件操作
http://www.cnblogs.com/rollenholt/archive/2012/04/23/2466179.html 总是记不住API.昨晚写的时候用到了这些,但是没记住,于是就索性整理 ...
随机推荐
- 部署crm项目
准备工作 使用xftp将项目传到linux 将knight 传到linux上 将项目的数据导出 mysqldum -uroot -p --all-database > alldb.dump 在w ...
- 微服务配合docker使用
1.docker 安装 rabbitmq 启动脚本: docker run -d --name rabbitmq --publish : \ --publish : --publish : --pub ...
- maven加载本地jar包到repository
maven加载本地jar到repository 这是一个常见场景,此处以本地opencv jar文件导入repository为例 1.Ubuntu下 mvn install:install-file ...
- BZOJ4317Atm的树&BZOJ2051A Problem For Fun&BZOJ2117[2010国家集训队]Crash的旅游计划——二分答案+动态点分治(点分树套线段树/点分树+vector)
题目描述 Atm有一段时间在虐qtree的题目,于是,他满脑子都是tree,tree,tree…… 于是,一天晚上他梦到自己被关在了一个有根树中,每条路径都有边权,一个神秘的声音告诉他,每个点到其他的 ...
- robotframework中RIDE的下载及安装
1.首先说一下我当前的环境配置 win10系统64位 python3.6.5,已配置环境变量 2.安装RIDE前需要安装的依赖包(使用pip就可以直接安装) 首先必须有robotframework这就 ...
- 【HDU - 4344】Mark the Rope(大整数分解)
BUPT2017 wintertraining(15) #8E 题意 长度为n(\(n<2^{63}\))的绳子,每隔长度L(1<L<n)做一次标记,标记值就是L,L是n的约数. 每 ...
- 用keras实现基本的回归问题
数据集介绍 共有506个样本,拆分为404个训练样本和102个测试样本 该数据集包含 13 个不同的特征: 人均犯罪率. 占地面积超过 25000 平方英尺的住宅用地所占的比例. 非零售商业用地所占的 ...
- html内嵌框架
html内嵌框架 <iframe>标签会创建包含另外一个html文件的内联框架(即行内框架),src属性来定义另一个html文件的引用地址,frameborder属性定义边框,scroll ...
- [HEOI2016/TJOI2016]游戏 解题报告
[HEOI2016/TJOI2016]游戏 看起来就是个二分图匹配啊 最大化匹配是在最大化边数,那么一条边就代表选中一个坐标内的点 但是每一行不一定只会有一个匹配 于是把点拆开,按照'#'划分一下就好 ...
- BZOJ2406矩阵
题目描述 题解 最大值最小,一眼二分没的说. 然后考虑建出这么个图,每行看做一个点,每列看做一个点,每个点看做一条连接行与列的边,源点向每行连s-mid__s+mid的边,行与列连L__R的边,列到汇 ...