Stanford机器学习---第一讲. Linear Regression with one variable
原文:http://blog.csdn.net/abcjennifer/article/details/7691571
本栏目(Machine learning)包括单参数的线性回归、多参数的线性回归、Octave Tutorial、Logistic Regression、Regularization、神经网络、机器学习系统设计、SVM(Support Vector Machines 支持向量机)、聚类、降维、异常检测、大规模机器学习等章节。所有内容均来自Standford公开课machine learning中Andrew老师的讲解。(https://class.coursera.org/ml/class/index)
第一章-------单参数线性回归 Linear Regression with one variable
(一)、Cost Function
线性回归是给出一系列点假设拟合直线为h(x)=theta0+theta1*x, 记Cost Function为J(theta0,theta1)
之所以说单参数是因为只有一个变量x,即影响回归参数θ1,θ0的是一维变量,或者说输入变量只有一维属性。

下图中为简化模式,只有theta1没有theta0的情况,即拟合直线为h(x)=theta1*x
左图为给定theta1时的直线和数据点
 ×
×
右图为不同theta1下的cost function J(theta1)
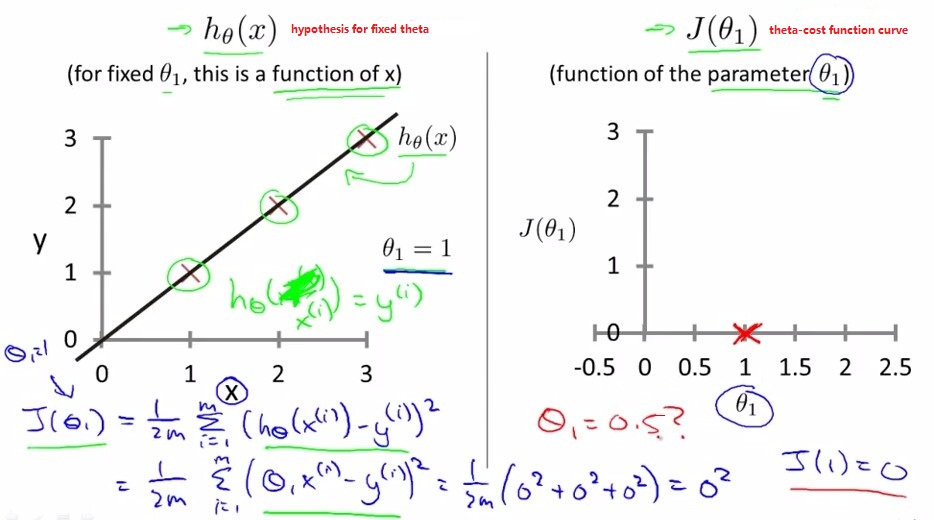
cost function plot:

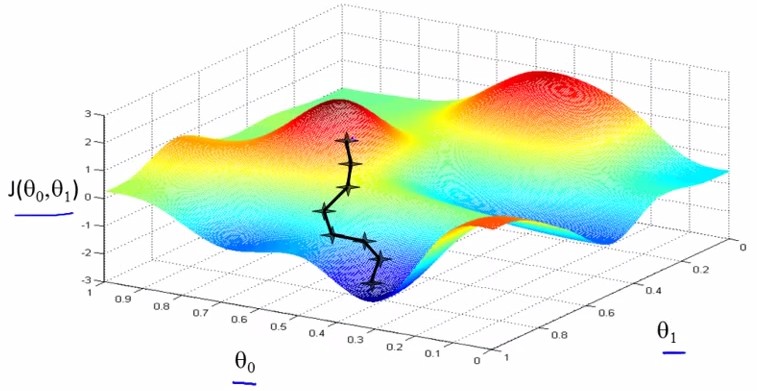
当存在两个参数theta0和theta1时,cost function是一个三维函数,这种样子的图像叫bowl-shape function

将上图中的cost function在二维上用不同颜色的等高线映射为如下右图,可得在左图中给定一个(theta0,theta1)时又图中显示的cost function.
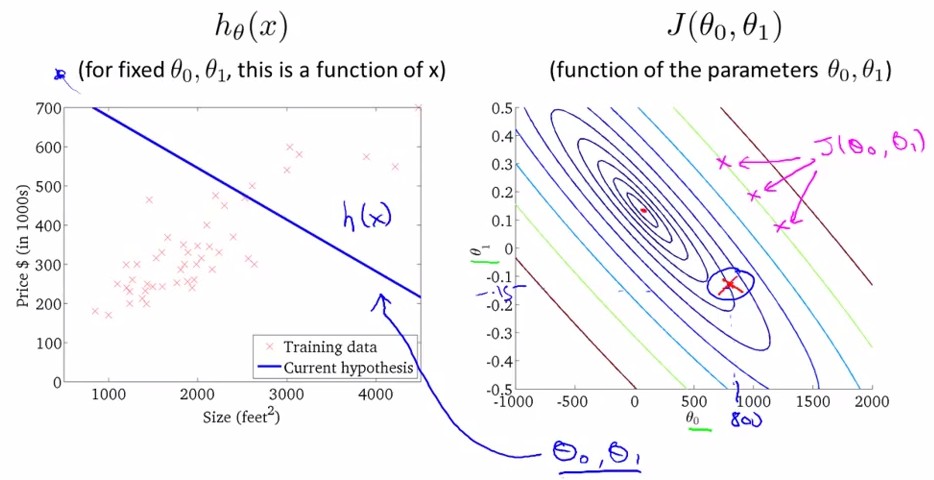

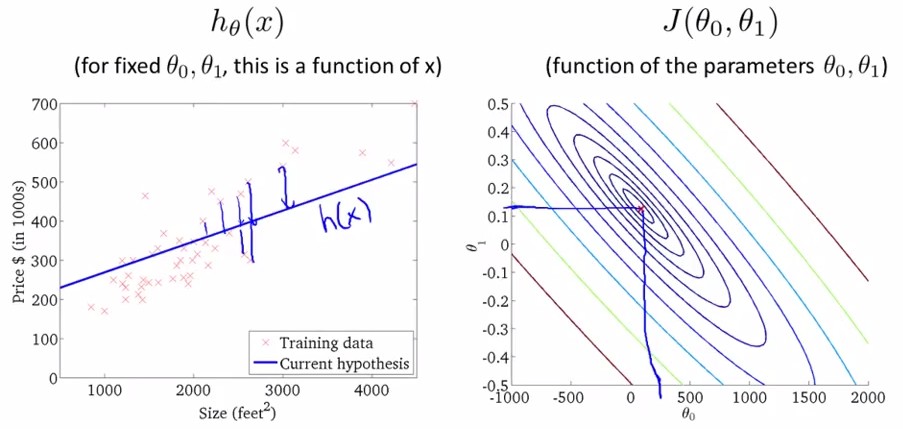
我们的目的是最小化cost function,即上图中最后一幅图,theta0=450,theta1=0.12的情况。
(二)、Gradient descent
gradient descent是指梯度下降,为的是将cost funciton 描绘出之后,让参数沿着梯度下降的方向走,并迭代地不断减小J(theta0,theta1),即稳态。

每次沿着梯度下降的方向:
参数的变换公式:其中标出了梯度(蓝框内)和学习率(α):

gradient即J在该点的切线斜率slope,tanβ。下图所示分别为slope(gradient)为正和负的情况:
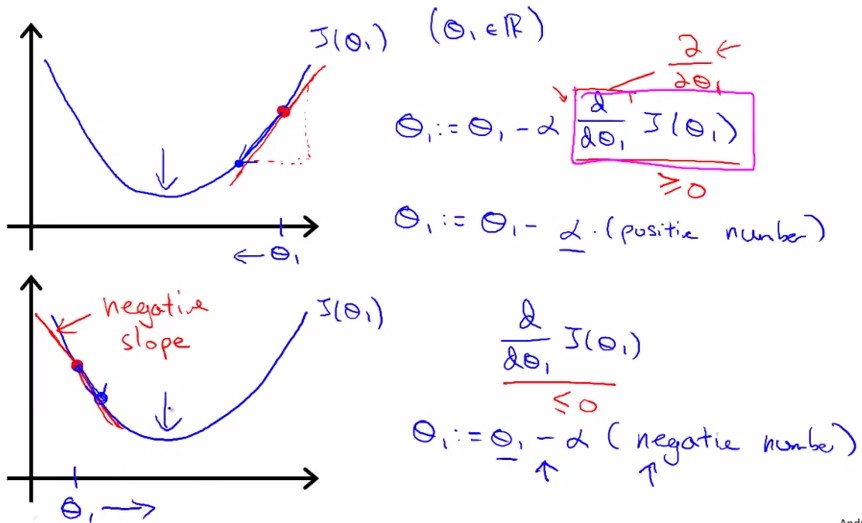
同时更新theta0和theta1,左边为正解:

关于学习率:
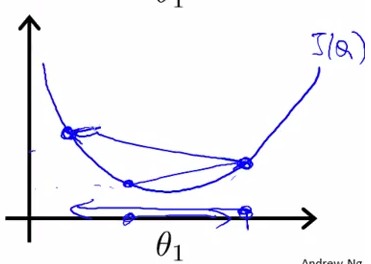
α太小:学习很慢; α太大:容易过学习
所以如果陷入局部极小,则slope=0,不会向左右变换
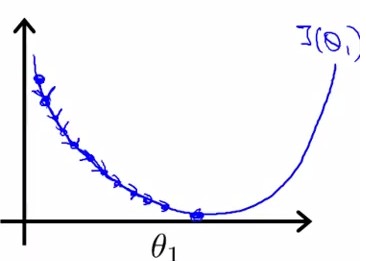
本图表示:无需逐渐减小α,就可以使下降幅度逐渐减小(因为梯度逐渐减小):
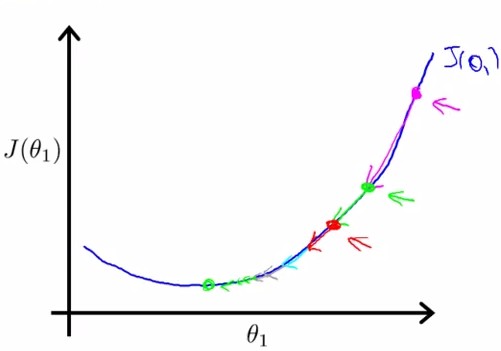
求导后:
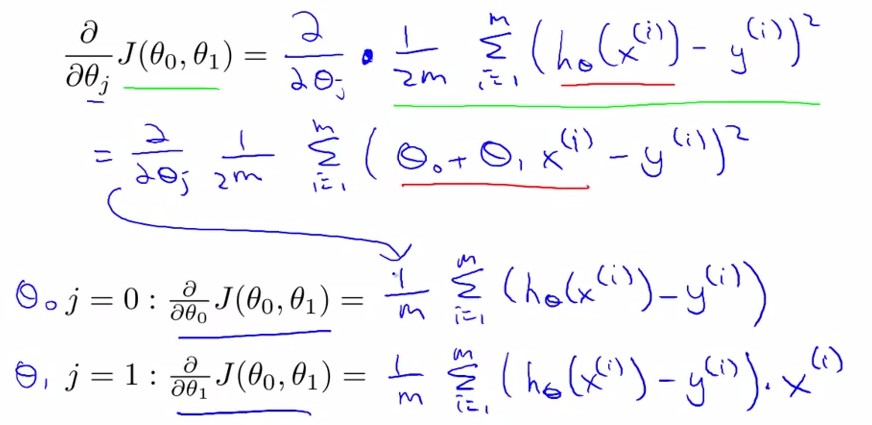
由此我们得到:
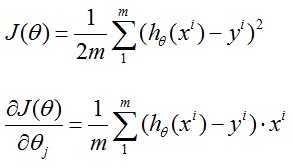

其中x(i)表示输入数据x中的第i组数据
Stanford机器学习---第一讲. Linear Regression with one variable的更多相关文章
- 机器学习笔记1——Linear Regression with One Variable
Linear Regression with One Variable Model Representation Recall that in *regression problems*, we ar ...
- 李宏毅老师机器学习第一课Linear regression
机器学习就是让机器学会自动的找一个函数 学习图谱: 1.regression example appliation estimating the combat power(cp) of a pokem ...
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable
原文:http://blog.csdn.net/abcjennifer/article/details/7700772 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 机器学习 (一) 单变量线性回归 Linear Regression with One Variable
文章内容均来自斯坦福大学的Andrew Ng教授讲解的Machine Learning课程,本文是针对该课程的个人学习笔记,如有疏漏,请以原课程所讲述内容为准.感谢博主Rachel Zhang的个人笔 ...
- Andrew Ng机器学习 一: Linear Regression
一:单变量线性回归(Linear regression with one variable) 背景:在某城市开办饭馆,我们有这样的数据集ex1data1.txt,第一列代表某个城市的人口,第二列代表在 ...
- 机器学习笔记-1 Linear Regression(week 1)
1.Linear Regression with One variable Linear Regression is supervised learning algorithm, Because th ...
- Andrew Ng机器学习编程作业: Linear Regression
编程作业有两个文件 1.machine-learning-live-scripts(此为脚本文件方便作业) 2.machine-learning-ex1(此为作业文件) 将这两个文件解压拖入matla ...
- 【cs229-Lecture2】Linear Regression with One Variable (Week 1)(含测试数据和源码)
从Ⅱ到Ⅳ都在讲的是线性回归,其中第Ⅱ章讲得是简单线性回归(simple linear regression, SLR)(单变量),第Ⅲ章讲的是线代基础,第Ⅳ章讲的是多元回归(大于一个自变量). 本文的 ...
- MachineLearning ---- lesson 2 Linear Regression with One Variable
Linear Regression with One Variable model Representation 以上篇博文中的房价预测为例,从图中依次来看,m表示训练集的大小,此处即房价样本数量:x ...
随机推荐
- css的小三角实现的方式
先上一个简单的例子哈: 此时的方向向下. 如果想方向向上的话用:border-top:0;border-bottom:4px solid; 1. width:0 height:0 border宽度,颜 ...
- js中的运动
缓慢隐藏与出现 效果: 鼠标移至分享上黄色区域自动向左隐藏. <!DOCTYPE html> <html> <head> <title></tit ...
- 第二十课:js中如何操作元素的属性系统
本章的内容有点复杂,我将用简单的方式来介绍重要的东西,不重要的东西,这里就不讲了,讲了也毛用. 通常我们把对象的非函数成员叫做属性.对元素节点来说,其属性大题分为两大类,固有属性和自定义属性.固有属性 ...
- beta版本贡献率
队名:攻城小分队 031302410 郭怡锋 : 占比:50% 031302411 洪大钊: 占比:30% 031302206 陈振贵: 占比:10% 031302416 黄伟祥: 占比:10%
- 【转】Dubbo_与Zookeeper、SpringMVC整合和使用(负载均衡、容错)
原文链接:http://blog.csdn.net/congcong68/article/details/41113239 互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服 ...
- 安装Eclipse插件
安装Eclipse插件 从eclipse 3.6开始,eclipse有一个marketplace,这个类似现在手机的app store一样,可以在其中检索相关插件,直接安装,打开help--> ...
- 【CodeForces 489A】SwapSort
题 Description In this problem your goal is to sort an array consisting of n integers in at most n sw ...
- spring 第一篇(1-1):让java开发变得更简单(下)转
spring 第一篇(1-1):让java开发变得更简单(下) 这个波主虽然只发了几篇,但是写的很好 上面一篇文章写的很好,其中提及到了Spring的jdbcTemplate,templet方式我之前 ...
- 【bzoj1211】 HNOI2004—树的计数
http://www.lydsy.com/JudgeOnline/problem.php?id=1211 (题目链接) 题意 一个有n个结点的树,设它的结点分别为v1, v2, …, vn,已知第i个 ...
- BZOJ2456 mode
Description 给你一个n个数的数列,其中某个数出现了超过n div 2次即众数,请你找出那个数. Input 第1行一个正整数n. 第2行n个正整数用空格隔开. Output 一行一个正整数 ...