SQLServer学习笔记<>相关子查询及复杂查询
二.查询缺少值的查询
在这里我们加入要查询2008年每一天的订单有多少?首先我们可以查询下订单表的订单日期在2008年的所有订单信息。
1 select distinct orderdate,count(*) as N'每日订单量' from sales.orders
2 where orderdate between '20080101' and '20081231'
3 group by orderdate
查询结果如图:
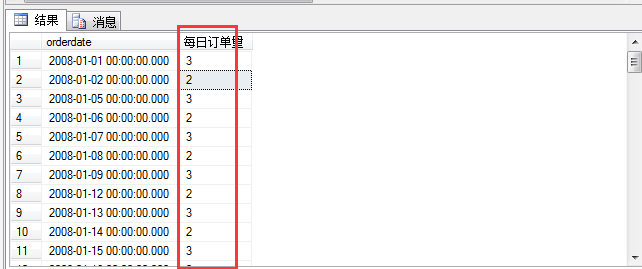
从上面可以看出来,每天的订单的数量根据orderdate分组以后统计出来啦,但是我们发现有的日期是不存在的,比如2008-01-01、2008-01-02....却没有发现2008-01-03日期的订单数量,加入我们要求看到每天的订单了?(这种要求大多数来源于财务报表的统计),这就要求我们进行表构造,我们可以构造一个包含2008年的每一年日期,然后进行表关不就得出来每一天的都包含的订单嘛。说着我就开始做吧,先开始构造一个包含2008年每一天的表。
1 create table nums
2 (
3 n int
4 );
5
6 select * from nums;
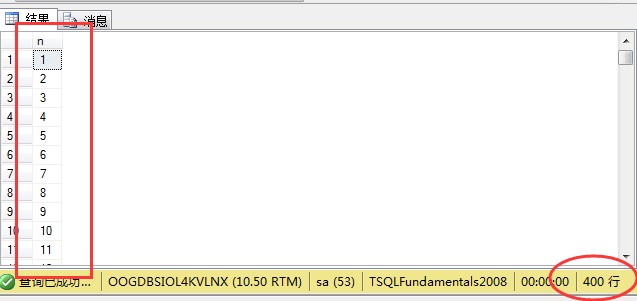
创建一个nums空表,用来保存连续的日期。接着就可以往表里面插入一些数据。

1 declare @i int;
2 set @i=0;
3 while @i<400
4 begin
5 set @i=@i+1;
6 insert into nums(n) values(@i);
7 end
可以看到表里面插入和1到400有序的数字:
接着我们就可以构造连续日期了,日期的相加前面已经学习过dateadd(),如果想一起学习一下,可以看一下前面的笔记:
sqlserver学习笔记1:http://www.cnblogs.com/liupeng61624/p/4354983.html
sqlserver学习笔记2:http://www.cnblogs.com/liupeng61624/p/4367580.html
sqlserver学习笔记3:http://www.cnblogs.com/liupeng61624/p/4375135.html
sqlserver学习笔记4:http://www.cnblogs.com/liupeng61624/p/4388959.html
继续说日期的相加,在这里我们通过日期相加,就可以构造2008年的每一天:
1 select dateadd(day,n,'20071231')
2 from nums;
构造的日期结果如图:
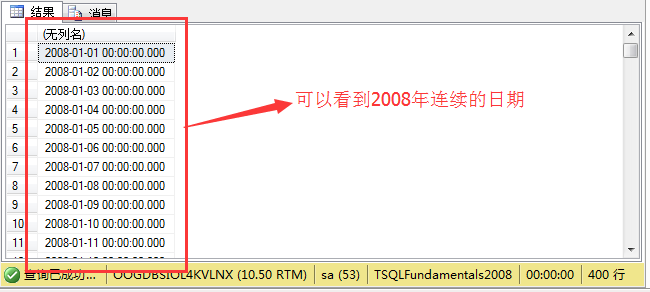
日期构造完以后,那么我们就可以利用这个结果集跟订单表Sales.orders进行一个连接。
1 select dateadd(day,f.n,'20071231'),count(orderid) as N'每日订单数量'
2 from nums f left join sales.orders m on
3 dateadd(day,f.n,'20071231')= m.orderdate
4 group by dateadd(day,f.n,'20071231')
5 order by dateadd(day,f.n,'20071231')
结果如图所示:
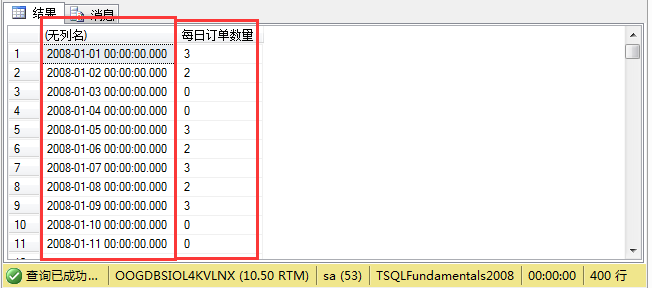
(2)子查询,即查询结果可以作为一个查询条件。
例如:我们要查询雇员表(Hr.employees)里面年龄最小的雇员信息。sql语句可以这样写:
1 select max(birthdate) as N'生日'
2 from hr.employees
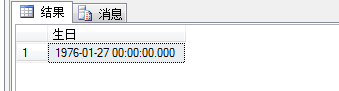
在这里我们知道可以用聚合函数max进行查询,但是加入我们还要查询出年龄最小的名字,即lastname,sql语句如下,可以发现报错,因为max聚合函数,是对一组结果进行处理,而lastname并不包含在聚合函数中,故报错。

那么在这里我们就要用到子查询来处理,可以讲年龄最小的结果作为查询结果来进一步查询。
1 select birthdate,lastname
2 from hr.employees
3 where birthdate=
4 (
5 select max(birthdate)
6 from hr.employees
7 )
查询结果如图所示:
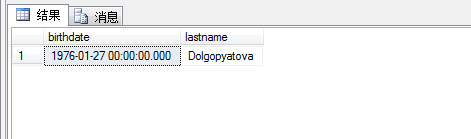
继续子查询,加入我们要将下订单最贵的那个客户找出来,给颁发一个Svip级别荣誉,并且找出他所在的国家已经他个人的一些基本信息。
根据上面子查询,我们可以这样写我们的sql,首在这里视图Sales.OrderValues里面存储的是订单的一些价格信息。故我们对这张视图进行操作。
- 首先找出订单最贵的信息
1
2 select max(val) as N'最贵订单'
3 from Sales.OrderValues
2. 然后找出最贵订单的顾客ID是多少
1 select custid from Sales.OrderValues
2 where val=(
3 select max(val) as N'最贵订单'
4 from Sales.OrderValues
5 )
3. 接着我们就可以在顾客表里面找出ID等于查询来的这个ID,同时查找出所在国家。
1 select custid,contactname,country
2 from sales.customers where custid=
3 (
4 select custid from Sales.OrderValues
5 where val=
6 (
7 select max(val) as N'最贵订单'
8 from Sales.OrderValues
9 )
10 )
结果如图所示:
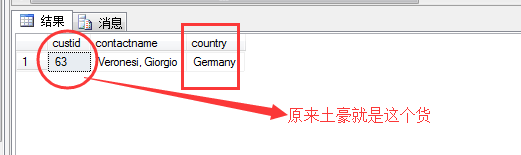
三.相关子查询,即查询的嵌套另一个查询,其中有涉及到相互关联的条件。
例如:我们要查询每个顾客下的订单数量,前面我们已经学习过,有两种方法都可以实现:
1.用group......by分组
1 select custid, count(*) as N'订单数量' from sales.orders
2 group by custid order by custid
2.利用count.....over
1 select distinct custid,count(*) over (partition by custid) as N'订单数量'
2 from sales.orders
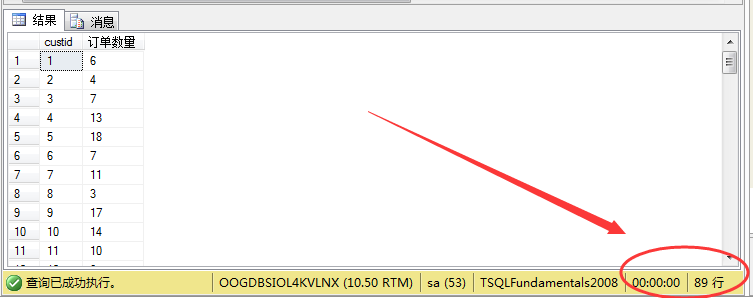
第三种方式我们就用相关子查询来解决,可以这样理解:就是我们没查一位顾客的订单数量就是去订单表里面顾客Id相同的都取出来,然后利用聚合函数求和。顾客ID我们可以从顾客表里面取出来,然后这个ID就等于订单表里面的ID。所以根据分析我们写sql如下:
1 select n.custid,n.contactname,
2 (
3 select count(*)
4 from sales.orders m
5 where m.custid=n.custid
6 ) as N'订单数量'
7 from sales.customers n
其结果如图所示:
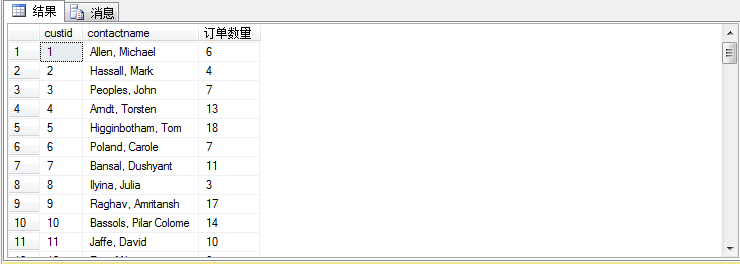
这样也可以把顾客下的订单数量算出来,这里就是利用到了外层查询跟内层查询条件作为比对求和。也就是我们说的相关子查询。
四.多值子查询
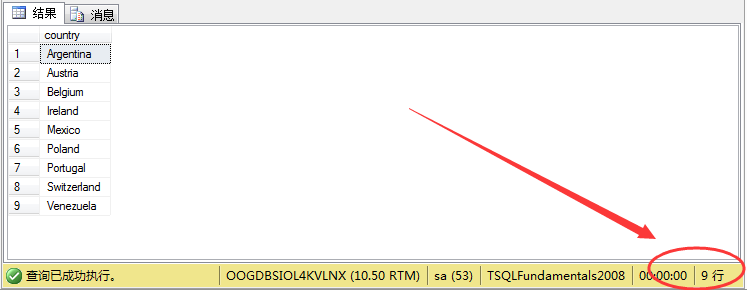
例如:我们要查询存在顾客但却没有供应商的国家,即这个国家中有顾客,没有供应商公司。
一般情况下:我们会采用常用的sql写法:
1
2 select distinct m.country from sales.customers m
3 where m.country not in
4 (
5 select n.country from production.suppliers n
6 )
结果如图所示:
既然有了not.....in写法,当然存在exists的写法,同样可以实现要求,exists对于结果集若存在则返回true,不存在返回false。我们可以这样理解:外层查询将country传递到内层查询,看看存不存在其中,其中内存查询包含多个结果,所以就叫做多值子查询。所以sql语句可以这样写:
1 select distinct m.country from sales.customers m
2 where not exists
3 (
4 select n.country from production.suppliers n
5 where n.country= m.country
6 )
结果如图所示:
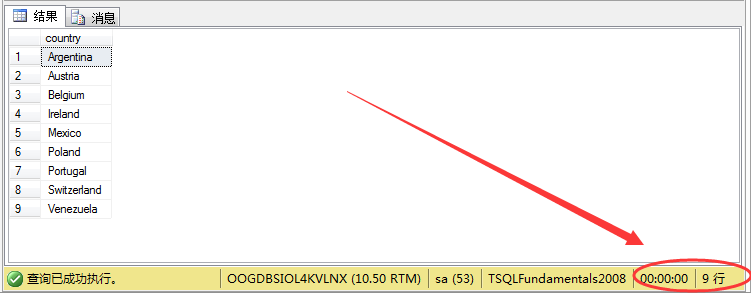
可以看到其结果跟not.....in查出来的结果一样,满足条件。
五.复杂子查询
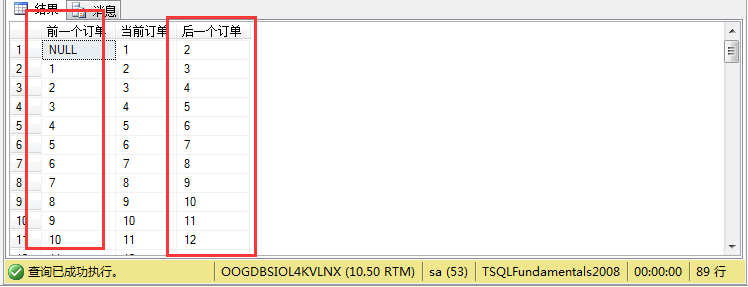
(1)例如:假如我们要查询所有订单当前订单的前一个订单和后一个订单信息,这里我们先分析:
1.首先我们先可以查询出所有的订单。
1 select distinct custid
2 from sales.orders
2.然后查询比当前订单Id小于的订单,同时这个订单是小于当前订单中最大的那个订单(即紧挨着的订单)。
1 select distinct
2 (
3 select max(custid) from
4 sales.orders m where m.custid< n.custid
5 ) as N'前一个订单',n.custid as N'当前订单'
6
7 from sales.orders n
3.同理,可以查出大于当前订单的那个紧挨着的那个订单。
1 select distinct
2 (
3 select max(custid) from
4 sales.orders m where m.custid< n.custid
5 ) as N'前一个订单',n.custid as N'当前订单',
6 (
7 select min(custid) from
8 sales.orders p where p.custid> n.custid
9 ) as N'后一个订单'
10 from sales.orders n
其结果如图所示:
(2)累计聚合
累计聚合在财务统计中,经常用到,比如2007年卖出多少,2008年卖出多少,那么2008年累计卖出就是2007年加上2008年卖出的总和,即累计聚合。
在这里我们有视图Sales.OrderTotalsByYear,其中统计的是每一年的订单总量。
1 select * from Sales.OrderTotalsByYear

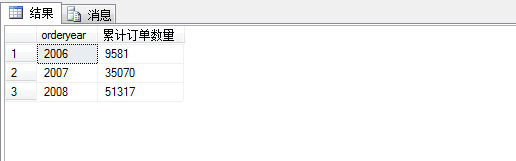
我们可以看到2007年有25489张订单,2008年有16247张订单,2006年有9581张订单。加入我们要求每年累计卖了多少订单,就要用到累计聚合。
1 select n.orderyear,
2 (
3 select sum(qty)
4 from Sales.OrderTotalsByYear m
5 where m.orderyear<=n.orderyear
6 ) as N'累计订单数量'
7 from Sales.OrderTotalsByYear n
8 order by n.orderyear;
结果如图所示:
SQLServer学习笔记<>相关子查询及复杂查询的更多相关文章
- SQLServer学习笔记系列5
一.写在前面的话 转眼又是一年清明节,话说“清明时节雨纷纷”,武汉的天气伴随着这个清明节下了一场暴雨,整个城市如海一样,朋友圈渗透着清明节武汉看海的节奏.今年又没有回老家祭祖,但是心里依然是怀念着那些 ...
- SQLServer学习笔记系列6
一.写在前面的话 时间是我们每个人都特别熟悉的,但是到底它是什么,用什么来衡量,可能很多人会愣在那里.时间可以见证一切,也可以消磨一切,那些过往的点点滴滴可思可忆.回想往年清明节过后,在家乡的晚上总能 ...
- SQLServer学习笔记系列3
一.写在前面的话 今天又是双休啦!生活依然再继续,当你停下来的时候,或许会突然显得不自在.有时候,看到一种东西,你会发现原来在这个社会上,优秀的人很多,默默 吃苦努力奋斗的人也多!星期五早上按时上班, ...
- SQLServer学习笔记系列2
一.写在前面的话 继上一次SQLServer学习笔记系列1http://www.cnblogs.com/liupeng61624/p/4354983.html以后,继续学习Sqlserver,一步一步 ...
- SQLServer 学习笔记之超详细基础SQL语句 Part 11
Sqlserver 学习笔记 by:授客 QQ:1033553122 -----------------------接Part 10------------------- DECLARE @myavg ...
- SQLServer 学习笔记之超详细基础SQL语句 Part 8
Sqlserver 学习笔记 by:授客 QQ:1033553122 -----------------------接Part 7------------------- --触发器str_trigge ...
- SQLServer 学习笔记之超详细基础SQL语句 Part 7
Sqlserver 学习笔记 by:授客 QQ:1033553122 -----------------------接Part 6------------------- 29 存储过程和触发器 存储过 ...
- SQLServer 学习笔记之超详细基础SQL语句 Part 6
Sqlserver 学习笔记 by:授客 QQ:1033553122 -----------------------接Part 5------------------- 28 聚合函数 --求平均分 ...
- SQLServer 学习笔记之超详细基础SQL语句 Part 5
Sqlserver 学习笔记 by:授客 QQ:1033553122 -----------------------接Part 4------------------- 21使用默认 默认(也称默认值 ...
随机推荐
- 防止IE不支持console.log报错
function log(msg){ if (window["console"]){//判断是否是IE console.log(msg); } }
- C# SQL优化 及 Linq 分页
每次写博客,第一句话都是这样的:程序员很苦逼,除了会写程序,还得会写博客!当然,希望将来的一天,某位老板看到此博客,给你的程序员职工加点薪资吧!因为程序员的世界除了苦逼就是沉默.我眼中的程序员大多都不 ...
- Function call process
摘自自博客网址 http://www.cnblogs.com/bangerlee/archive/2012/05/22/2508772.html ax(accumulator): 可用于存放函数返回值 ...
- linux:问题
1>.Xshell远程连接linux闲置时间过长会自动中断连接: 2>.在linux环境下乱码: 3>.在linux下面执行mv /bin/ls /root/bin之后执行ls就不能 ...
- PostgreSQL Replication之第十章 配置Slony(1)
在PostgreSQL领域中,Slony是最广泛的复制解决方案之一.它不仅是最老的复制方案实现的一个,但也是有最多的外部工具支持的一个,例如PgAdmin3等. 在本章中,我们将深入探究Slony并学 ...
- Maven教程(转载)
转载自:http://www.yiibai.com/maven/ Apache Maven是一个软件项目管理和综合工具.基于项目对象模型(POM)的概念,Maven可以从一个中心资料片管理项目构建,报 ...
- html 标签自己居中
<div style="width: 200px; height: 200px; border: 1px solid red; margin: 0 auto;">< ...
- SQLserver查看数据库端口 脚本
exec sys.sp_readerrorlog 0, 1, 'listening'
- [转]JVM内幕:Java虚拟机详解
本文由 ImportNew - 挖坑的张师傅 翻译自 jamesdbloom.欢迎加入翻译小组.转载请见文末要求. 这篇文章解释了Java 虚拟机(JVM)的内部架构.下图显示了遵守Java SE 7 ...
- Java基础(62):Eclipse调试(Debug)的10条技巧(转)
在看这篇文章前,我推荐你看一下Eclipse 快捷键手册 先提三点 不要使用System.out.println作为调试工具 启用所有组件的详细的日志记录级别 使用一个日志分析器来阅读日志 1.条件断 ...