精进之路之lru
原理
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
实现1
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
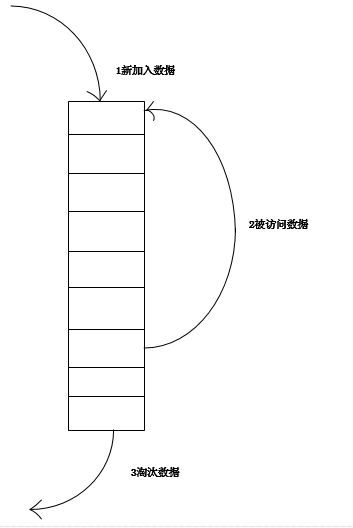
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
使用LinkedHashMap实现
LinkedHashMap底层就是用的HashMap加双链表实现的,而且本身已经实现了按照访问顺序的存储。此外,LinkedHashMap中本身就实现了一个方法removeEldestEntry用于判断是否需要移除最不常读取的数,方法默认是直接返回false,不会移除元素,所以需要重写该方法。即当缓存满后就移除最不常用的数。
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private static final long serialVersionUID = 1L;
//缓存大小
private int cacheSize;
public LRUCache(int cacheSize) {
//第三个参数true是关键
super(10, 0.75f, true);
this.cacheSize = cacheSize;
}
/**
* 缓存是否已满
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
boolean r = size() > cacheSize;
if (r) {
System.out.println("清除缓存key:" + eldest.getKey());
}
return r;
}
//测试
public static void main(String[] args) {
LRUCache<String, String> cache = new LRUCache<String, String>(5);
cache.put("1", "1");
cache.put("2", "2");
cache.put("3", "3");
cache.put("4", "4");
cache.put("5", "5");
System.out.println("初始化:");
System.out.println(cache.keySet());
System.out.println("访问3:");
cache.get("3");
System.out.println(cache.keySet());
System.out.println("访问2:");
cache.get("2");
System.out.println(cache.keySet());
System.out.println("增加数据6,7:");
cache.put("6", "6");
cache.put("7", "7");
System.out.println(cache.keySet());
}
实现2
LRUCache的链表+HashMap实现
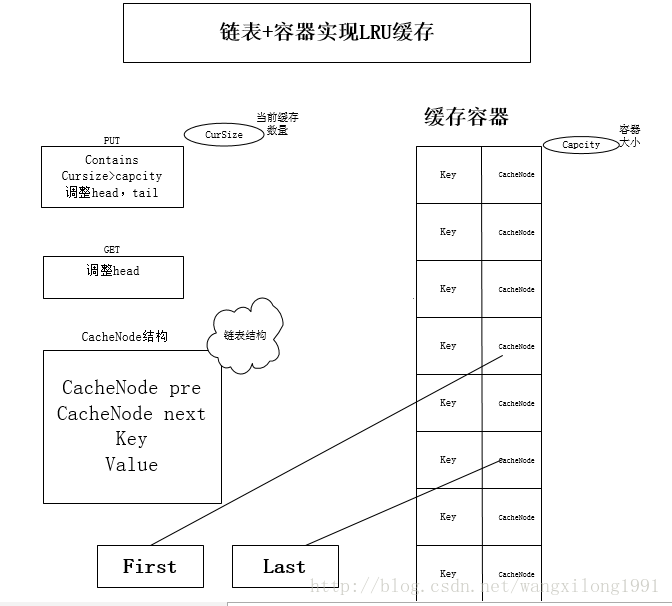
传统意义的LRU算法是为每一个Cache对象设置一个计数器,每次Cache命中则给计数器+1,而Cache用完,需要淘汰旧内容,放置新内容时,就查看所有的计数器,并将最少使用的内容替换掉。 它的弊端很明显,如果Cache的数量少,问题不会很大, 但是如果Cache的空间过大,达到10W或者100W以上,一旦需要淘汰,则需要遍历所有计算器,其性能与资源消耗是巨大的。效率也就非常的慢了。它的原理: 将Cache的所有位置都用双连表连接起来,当一个位置被命中之后,就将通过调整链表的指向,将该位置调整到链表头的位置,新加入的Cache直接加到链表头中。这样,在多次进行Cache操作后,最近被命中的,就会被向链表头方向移动,而没有命中的,而想链表后面移动,链表尾则表示最近最少使用的Cache。当需要替换内容时候,链表的最后位置就是最少被命中的位置,我们只需要淘汰链表最后的部分即可。上面说了这么多的理论, 下面用代码来实现一个LRU策略的缓存。非线程安全,若实现安全,则在响应的方法加锁。
public class LRUCacheDemo<K, V> {
private int currentCacheSize;
private int CacheCapcity;
private HashMap<K, CacheNode> caches;
private CacheNode first;
private CacheNode last;
public LRUCacheDemo(int size) {
currentCacheSize = 0;
this.CacheCapcity = size;
caches = new HashMap<>(size);
}
public void put(K k, V v) {
CacheNode node = caches.get(k);
if (node == null) {
if (caches.size() >= CacheCapcity) {
caches.remove(last.key);
removeLast();
}
node = new CacheNode();
node.key = k;
}
node.value = v;
moveToFirst(node);
caches.put(k, node);
}
public Object get(K k) {
CacheNode node = caches.get(k);
if (node == null) {
return null;
}
moveToFirst(node);
return node.value;
}
public Object remove(K k) {
CacheNode node = caches.get(k);
if (node != null) {
if (node.pre != null) {
node.pre.next = node.next;
}
if (node.next != null) {
node.next.pre = node.pre;
}
if (node == first) {
first = node.next;
}
if (node == last) {
last = node.pre;
}
}
return caches.remove(k);
}
public void clear() {
first = null;
last = null;
caches.clear();
}
private void moveToFirst(CacheNode node) {
if (first == node) {
return;
}
if (node.next != null) {
node.next.pre = node.pre;
}
if (node.pre != null) {
node.pre.next = node.next;
}
if (node == last) {
last = last.pre;
}
if (first == null || last == null) {
first = last = node;
return;
}
node.next = first;
first.pre = node;
first = node;
first.pre = null;
}
private void removeLast() {
if (last != null) {
last = last.pre;
if (last == null) {
first = null;
} else {
last.next = null;
}
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
CacheNode node = first;
while (node != null) {
sb.append(String.format("%s:%s ", node.key, node.value));
node = node.next;
}
return sb.toString();
}
class CacheNode {
CacheNode pre;
CacheNode next;
Object key;
Object value;
public CacheNode() {
}
}
public static void main(String[] args) {
LRUCache<Integer, String> lru = new LRUCache<Integer, String>(3);
lru.put(1, "a"); // 1:a
System.out.println(lru.toString());
lru.put(2, "b"); // 2:b 1:a
System.out.println(lru.toString());
lru.put(3, "c"); // 3:c 2:b 1:a
System.out.println(lru.toString());
lru.put(4, "d"); // 4:d 3:c 2:b
System.out.println(lru.toString());
lru.put(1, "aa"); // 1:aa 4:d 3:c
System.out.println(lru.toString());
lru.put(2, "bb"); // 2:bb 1:aa 4:d
System.out.println(lru.toString());
lru.put(5, "e"); // 5:e 2:bb 1:aa
System.out.println(lru.toString());
lru.get(1); // 1:aa 5:e 2:bb
System.out.println(lru.toString());
lru.remove(11); // 1:aa 5:e 2:bb
System.out.println(lru.toString());
lru.remove(1); //5:e 2:bb
System.out.println(lru.toString());
lru.put(1, "aaa"); //1:aaa 5:e 2:bb
System.out.println(lru.toString());
}
}
扩展:
扩展
1.LRU-K
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
数据第一次被访问时,加入到历史访问列表,如果数据在访问历史列表中没有达到K次访问,则按照一定的规则(FIFO,LRU)淘汰;当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列中删除,将数据移到缓存队列中,并缓存数据,缓存队列重新按照时间排序;缓存数据队列中被再次访问后,重新排序,需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即“淘汰倒数K次访问离现在最久的数据”。
LRU-K具有LRU的优点,同时还能避免LRU的缺点,实际应用中LRU-2是综合最优的选择。由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多
本文参考整理于 https://blog.csdn.net/wangxilong1991/article/details/70172302 ,https://blog.csdn.net/elricboa/article/details/78847305,感谢原作者的精彩分享!!!
精进之路之lru的更多相关文章
- python精进之路1---基础数据类型
python精进之路1---基本数据类型 python的基本数据类型如上图,重点需要掌握字符串.列表和字典. 一.int.float类型 int主要是用于整数类型计算,float主要用于小数. int ...
- ❤️【Android精进之路-01】定计划,重行动来学Android吧❤️
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦. Android精进之路第一篇,确定安卓学习计划. 干货满满,建议收藏,需要用到时常看看.小伙伴们如有问题及需要,欢迎踊跃留言哦~ ~ ~. 前言 ...
- 《Go 精进之路》 读书笔记 (第一次更新)
<Go 精进之路> 读书笔记.简要记录自己打五角星的部分,方便复习巩固.目前看到p120 Go 语言遵从的设计哲学为组合 垂直组合:类型嵌入,快速让一个类型复用其他类型已经实现的能力,实现 ...
- python精进之路 -- open函数
下面是python中builtins文件里对open函数的定义,我将英文按照我的理解翻译成中文,方便以后查看. def open(file, mode='r', buffering=None, enc ...
- 精进之路之AQS及相关组件
AQS ( AbstractQueuedSynchronizer)是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Sem ...
- 精进之路之CAS
CAS (Compare And Swap) 即比较交换, 是一种实现并发算法时常用到的技术,Java并发包中的很多类都使用了CAS技术,本文将深入的介绍CAS的原理. 其算法核心思想如下 执行函数: ...
- 精进之路之volatile
volatile 首先了解下Java 内存模型中的可见性.原子性和有序性. 可见性: 可见性是一种复杂的属性,因为可见性中的错误总是会违背我们的直觉.通常,我们无法确保执行读操作的线程能适时地看到其他 ...
- 精进之路之JMM
JMM (Java Memory Model) java内存模型 Java内存模型的抽象 Java线程之间的通信由Java内存模型(本文简称为JMM)控制,JMM决定一个线程对共享变量的写入何时对另一 ...
- 精进之路之HashMap
HashMap本质的核心就是“数组+链表”,数组对于访问速度很快,而链表的优势在于插入速度快,HashMap集二者于一身. 提到HashMap,我们不得不提各个版本对于HashMap的不同.本文中先从 ...
随机推荐
- python 学习笔记 5 ----> dive into python 3
字符串 文本:屏幕上显示的字符或者其他的记号 计算机认识的东西:位(bit)和字节(byte) 文本的本质:某种字符编码方式保存的内容. 字符编码:一种映射(显示的内容 ----> 内存.磁盘 ...
- Matlab的BP神经网络工具箱及其在函数逼近中的应用
1.神经网络工具箱概述 Matlab神经网络工具箱几乎包含了现有神经网络的最新成果,神经网络工具箱模型包括感知器.线性网络.BP网络.径向基函数网络.竞争型神经网络.自组织网络和学习向量量化网络.反馈 ...
- nodejs 从部署到域名访问
一.Node.js 安装在Ubuntu上 用如下代码下载nodejs 8.x最新版并安装,npm 也会随着一起安装 curl -sL https://deb.nodesource.com/setup_ ...
- 用oracle自带的ssh脚本配置互信
./sshUserSetup.sh -user 用户名 -hosts "主机名1 主机名2 主机名3 ..." -advanced -noPromptPassphrase 这个 ...
- [bzoj P4504] K个串
[bzoj P4504] K个串 [题目描述] 兔子们在玩k个串的游戏.首先,它们拿出了一个长度为n的数字序列,选出其中的一个连续子串,然后统计其子串中所有数字之和(注意这里重复出现的数字只被统计一次 ...
- WinForm界面设计优化过程
以在做的项目为例,记录一下界面美化过程中遇到的问题,由于项目是先做出来之后,又请美工进行稍微调整设计界面,所以会又些限制 1. TabControl的问题----在添加了背景图片后,TabContro ...
- dp背包问题
0-1背包 1.问题定义: 给定n种物品和背包.物品i的重量是wi,价值是vi,每种物品只有一个,背包容量为C.问:应该如何选择装入背包的物品,使得装入背包中的物品总值最大. 2.算法思路: 选择装入 ...
- 有效的括号序列——算法面试刷题4(for google),考察stack
给定一个字符串所表示的括号序列,包含以下字符: '(', ')', '{', '}', '[' and ']', 判定是否是有效的括号序列. 括号必须依照 "()" 顺序表示, & ...
- SQL语句全解,非常棒!
链接自W3school非常详细的SQL教程 http://www.w3school.com.cn/sql/index.asp
- Ubuntu18.04下安装搜狗输入法
Ubuntu18.04下安装搜狗输入法 第一步:安装 fcitx输入框架 sudo apt-get install fcitx 第二步:在官网下载 Linux 版本搜狗输入法 https://piny ...