java内置线程池ThreadPoolExecutor源码学习记录
背景
公司业务性能优化,使用java自带的Executors.newFixedThreadPool()方法生成线程池。但是其内部定义的LinkedBlockingQueue容量是Integer.MAX_VALUE。考虑到如果数据库中待处理数据量很大有可能会在短时间内往LinkedBlockingQueue中填充很多数据,导致内存溢出。于是看了一下线程池这块的源码,并在此记录。
类图
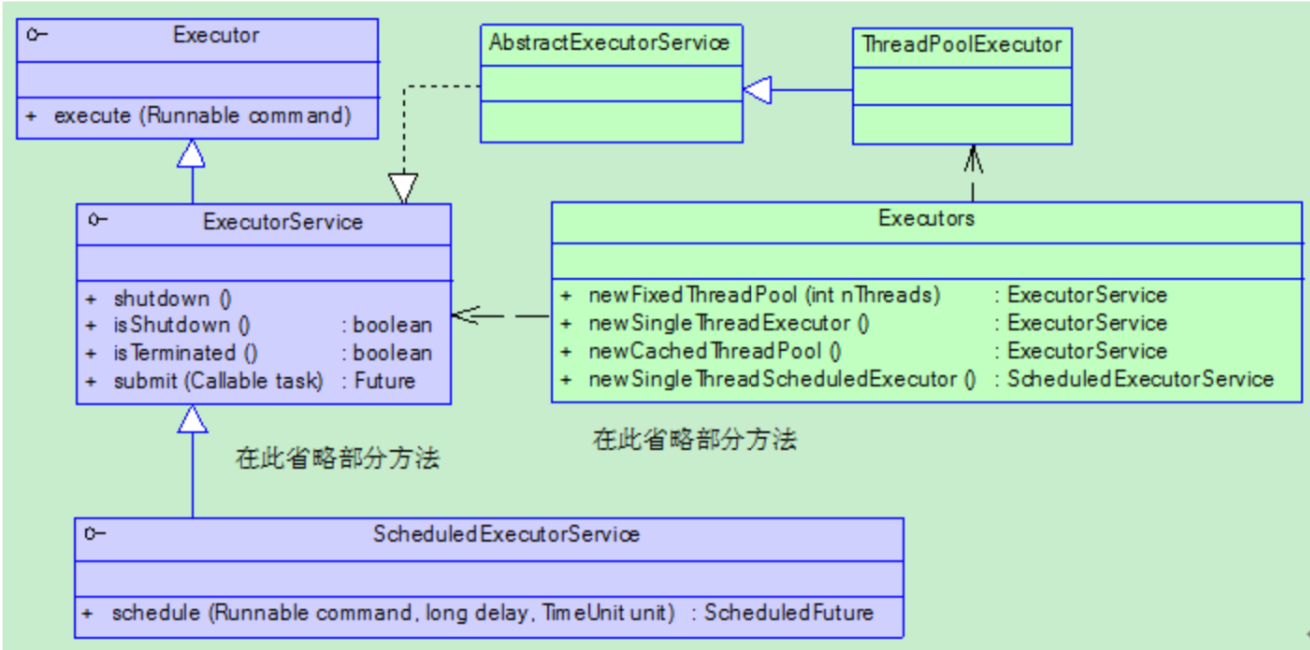
Executor是一个顶层接口,在它里面只声明了一个方法execute(Runnable),返回值为void,参数为Runnable类型,从字面意思可以理解,就是用来执行传进去的任务的;
ExecutorService接口继承了Executor接口,并声明了一些方法:submit、invokeAll、invokeAny以及shutDown等
抽象类AbstractExecutorService实现了ExecutorService接口,基本实现了ExecutorService中声明的所有方法;submit() 方法
ThreadPoolExecutor继承了类AbstractExecutorService。实现了execute(Runnable)方法。
Executors提供的集中工厂方法都是调用的ThreadPoolExecutor的构造方法。因为这个构造方法参数比较多 所以提供了几个经典的实现。
ExecutorService newCachedThreadPool = Executors.newFixedThreadPool();
ExecutorService newCachedThreadPool = Executors.newSingleThreadExecutor();
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
ExecutorService newCachedThreadPool = Executors.newScheduledThreadPool();
本篇违章主要包括以下几点内容。这也是解决背景中提到的问题的主要历程。
1.ThreadPoolExecutor构造方法
2.ExecutorService submit() 方法的实现
2.Executor execute() 方法的实现
3.reject() 拒绝策略
ThreadPoolExecutor构造方法
构造方法中赋值的成员标量:
// 构造方法中用到的成员变量
private volatile int corePoolSize; //核心池的大小(即线程池中的线程数目大于这个参数时,提交的任务会被放进任务缓存队列)
private volatile int maximumPoolSize; //线程池最大能容忍的线程数
private volatile long keepAliveTime; //线程空闲之后存货时间 (线程数量大于corePoolSize之后)
private final BlockingQueue<Runnable> workQueue; //任务缓存队列,用来存放等待执行的任务
private volatile ThreadFactory threadFactory; //线程工厂,用来创建线程
private volatile RejectedExecutionHandler handler; //任务拒绝策略
通过代码可以知道 Executors提供的集中工厂方法实际都是调用的同一个ThreadPoolExecutor的构造方法。当然我们也可以通过自己调用ThreadPoolExecutor构造方法 自己设置参数 从而获得很贴合我们业务的线程池。
AbstractExecutorService submit() 方法
/**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
其实是调用了execute() 方法,execute()方法 由ThreadPoolExecutor类实现。
ThreadPoolExecutor execute()方法
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 29位
private static final int COUNT_BITS = Integer.SIZE - 3;
// 0001 1111 1111 1111 1111 1111 1111 1111
private static final int CAPACITY = (1 << COUNT_BITS) - 1; // runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS; // Packing and unpacking ctl
// 高三位 代表 状态
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 低三位 代表 数量
private static int workerCountOf(int c) { return c & CAPACITY; }
// 把状态和数量两个值 揉在一起
// private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static int ctlOf(int rs, int wc) { return rs | wc; }
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// 获取到当前有效的线程数和线程池的状态
int c = ctl.get();
// 1.获取当前正在运行线程数是否小于核心线程池,是则新创建一个线程执行任务,否则将任务放到任务队列中
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2.当前核心线程池中全部线程都在运行workerCountOf(c) >= corePoolSize,所以此时将线程放到任务队列中
// 线程池是否处于运行状态,且是否任务插入任务队列成功。注意这块 && 是做了优化如果前面条件失败后面语句不会处理
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//在此检查线程池是否处于运行状态,如果不是则使刚刚的任务出队。和上面一样 && 是做了优化如果前面条件失败后面语句不会处理
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果没有执行的线程,就再开启一个线程(有可能没有核心线程)
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3.插入队列不成功 offer() 方法失败是因为队列满了,此时就新创建线程去执行任务,创建失败抛出异常
else if (!addWorker(command, false))
reject(command);
}
// CAS修改clt的值+1,成功退出cas循环,失败继续
if (compareAndIncrementWorkerCount(c))
break retry;
//将新建的线程加入到线程池中
workers.add(w);
int s = workers.size();
//修正largestPoolSize的值
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
addWorker()方法 总结起来就两部分
1.CAS+失败重试操作来将线程数加1
2.新建一个线程并启用。
RejectedExecutionHandler拒绝策略
java 内置的四种拒绝策略。
public static class AbortPolicy implements RejectedExecutionHandler // 抛出java.util.concurrent.RejectedExecutionException异常
public static class CallerRunsPolicy implements RejectedExecutionHandler //直接在 execute 方法的调用线程中运行被拒绝的任务。如果执行程序已关闭,则会丢弃该任务
public static class DiscardPolicy implements RejectedExecutionHandler // 不做任何处理 直接丢弃
public static class DiscardOldestPolicy implements RejectedExecutionHandler // 丢弃老的
自定义拒绝策略:
new RejectedExecutionHandler() {
// 自定义拒绝策略
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
try {
// 如果LinkedBlockingQueue存满了,阻塞等待有空间后再加入元素。(put方法是阻塞的)
LOGGER.info("LinkedBlockingQueue has been full ");
// put() 方法是阻塞的,如果队列没有空间会一直等待。
executor.getQueue().put(r);
LOGGER.info("thread has been put in");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
总结一点:当用java内置的一些工具的时候,如果有不理解的一定要 深入去看源码。从根本上找解决思路。
java内置线程池ThreadPoolExecutor源码学习记录的更多相关文章
- Java并发之线程池ThreadPoolExecutor源码分析学习
线程池学习 以下所有内容以及源码分析都是基于JDK1.8的,请知悉. 我写博客就真的比较没有顺序了,这可能跟我的学习方式有关,我自己也觉得这样挺不好的,但是没办法说服自己去改变,所以也只能这样想到什么 ...
- Java核心复习——线程池ThreadPoolExecutor源码分析
一.线程池的介绍 线程池一种性能优化的重要手段.优化点在于创建线程和销毁线程会带来资源和时间上的消耗,而且线程池可以对线程进行管理,则可以减少这种损耗. 使用线程池的好处如下: 降低资源的消耗 提高响 ...
- Java并发包源码学习系列:线程池ThreadPoolExecutor源码解析
目录 ThreadPoolExecutor概述 线程池解决的优点 线程池处理流程 创建线程池 重要常量及字段 线程池的五种状态及转换 ThreadPoolExecutor构造参数及参数意义 Work类 ...
- 【Java并发编程】21、线程池ThreadPoolExecutor源码解析
一.前言 JUC这部分还有线程池这一块没有分析,需要抓紧时间分析,下面开始ThreadPoolExecutor,其是线程池的基础,分析完了这个类会简化之后的分析,线程池可以解决两个不同问题:由于减少了 ...
- 为什么阿里Java规约禁止使用Java内置线程池?
IDEA导入阿里规约插件,当你这样写代码时,插件就会自动监测出来,并给你红线提醒. 告诉你手动创建线程池,效果会更好. 在探秘原因之前我们要先了解一下线程池 ThreadPoolExecutor 都有 ...
- Python线程池ThreadPoolExecutor源码分析
在学习concurrent库时遇到了一些问题,后来搞清楚了,这里记录一下 先看个例子: import time from concurrent.futures import ThreadPoolExe ...
- 线程池ThreadPoolExecutor源码分析
在阿里编程规约中关于线程池强制了两点,如下: [强制]线程资源必须通过线程池提供,不允许在应用中自行显式创建线程.说明:使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源 ...
- 线程池ThreadPoolExecutor源码解读研究(JDK1.8)
一.什么是线程池 为什么要使用线程池?在多线程并发开发中,线程的数量较多,且每个线程执行一定的时间后就结束了,下一个线程任务到来还需要重新创建线程,这样线程数量特别庞大的时候,频繁的创建线程和销毁线程 ...
- 浅析线程池 ThreadPoolExecutor 源码
首先看下类的继承关系,不多介绍: public interface Executor {void execute(Runnable);} public interface ExecutorServic ...
随机推荐
- fiddler 应用
一 pc 端抓取 例:本地调试代码,转换域名,请求网络数据 1:设置代理,以smart header 为例 ip为 127.0.0.1 端口与自己的fillder一致,注意将不代理的地址列表做修改 ...
- vue 源码学习二 实例初始化和挂载过程
vue 入口 从vue的构建过程可以知道,web环境下,入口文件在 src/platforms/web/entry-runtime-with-compiler.js(以Runtime + Compil ...
- Elasticsearch 滚动重启 必读
关键词:elasticsearch , es , 滚动重启 , 禁止分片 由于之前es GC没有怎么调优,结果今天被大量scroll查询查挂了,GC 卡死了.然后为了先恢复给业务使用,也没什么其他办法 ...
- History of program
第一阶段:1950与1960年代 1.三个现代编程语言: (1)Fortran (1955),名称取自"FORmula TRANslator"(公式翻译器),由约翰·巴科斯等人所发 ...
- 马昕璐/唐月晨 《面向对象程序设计(java)》第十一周学习总结
一:理论部分. 一般将数据结构分为两大类:线性数据结构和非线性数据结构 线性数据结构:线性表.栈.队列.串.数组和文件 非线性数据结构:树和图. 线性表:1.所有数据元素在同一个线性表中必须是相同的数 ...
- 漏测BUG借鉴
2. websocket: 用户频繁刷新,后台每次请求新的排队,内存溢出 1. websocket: 北京中心连接正常,外地中心,连接超时,应考虑到外地延迟问题
- java代码编译与C/C++代码编译的区别
Java编译原理 1.Java编译过程与c/c++编译过程不同 Java编译程序将java源程序编译成jvm可执行代码--java字节码. Java在编译过程中一般会按照以下过程进行: (1)JDK根 ...
- Pycharm画五角星
import turtle turtle.setup(600,400,0,0) turtle.bgcolor('red') turtle.color('yellow') turtle.fillcolo ...
- php-cgi占用太多cpu资源而导致服务器响应过慢
服务器环境:redhat linux 5.5 , nginx , phpfastcgi 在此环境下,一般php-cgi运行是非常稳定的,但也遇到过php-cgi占用太多cpu资源而导致服务器响应过慢 ...
- 企业IT管理员IE11升级指南【9】—— IE10与IE11的功能对比
企业IT管理员IE11升级指南 系列: [1]—— Internet Explorer 11增强保护模式 (EPM) 介绍 [2]—— Internet Explorer 11 对Adobe Flas ...