分布式监控系统开发【day38】:监控数据如何画图(九)
一、画图代码
1、收集处理数据
class GraphGenerator(object):
'''
generate graphs
''' def __init__(self,request,redis_obj):
self.request = request
self.host_id = self.request.GET.get('host_id')
self.service_name = self.request.GET.get('service_key')
self.index_key = self.request.GET.get('index_key')
self.time_range = self.request.GET.get('time_range')
self.sub_service_name = self.request.GET.get('sub_service_key')
self.redis = redis_obj print("sub service key:", self.sub_service_name) def get_graph_data(self):
#data_store_key = "StatusData_%s_%s_latest" %(self.host_id,self.service_name)
data_store_key = "StatusData_%s_%s_%s" %(self.host_id,self.service_name,self.time_range)
data_set = self.redis.lrange(data_store_key,0,-1)
print("data store key:", data_store_key)
print("data point nums:", len(data_set))
#print("data points:", data_set)
service_obj = models.Service.objects.get(name=self.service_name)
data_dic = {} #store graph data later
for item in service_obj.items.select_related():
data_dic[item.key] = [] if data_set: #make sure data set not empty print("service data for graph:", data_dic)
if self.sub_service_name == None or self.sub_service_name == 'undefined':
for data_point in data_set:
#data_point sample data:('-->', {u'status': 0, u'iowait': u'0.00', u'system': u'1.01', u'idle': u'96.98', u'user': u'2.01', u'steal': u'0.00', u'nice': u'0.00'}, 1461840915.038072)
val,timestamp = json.loads(data_point)
if val:
for k,v in val.items():
if k in data_dic:
'''if len(data_dic[k]) > 0: #不是第一次存值
last_point_save_time = data_dic[k][-1][0] #microseconds
data_point_interval =settings.STATUS_DATA_OPTIMIZATION[self.time_range][0]
if timestamp*1000 - last_point_save_time > data_point_interval:
#这里出现中断了
data_dic[k].append([last_point_save_time + data_point_interval,0])
else:#没有中断过,什么都 不用做哈哈
pass
'''
if type(v) is not list:
data_dic[k].append([timestamp*1000,float(v)])
else: #v = [avg,max,min,mid]
data_dic[k].append([timestamp*1000,float(v[0])]) #暂时只往前台 返回 average数据
else: #has sub service
print("\033[44;1m------------subservice key: %s, %s\033[0m" %(self.sub_service_name,self.service_name))
for data_point in data_set:
#data_point sample data:('-->', {u'status': 0, u'iowait': u'0.00', u'system': u'1.01', u'idle': u'96.98', u'user': u'2.01', u'steal': u'0.00', u'nice': u'0.00'}, 1461840915.038072)
val,timestamp = json.loads(data_point)
if val:
if val.get('data'):
for sub_service_key,v_dic in val['data'].items():
for k,v in v_dic.items():
if k in data_dic:
if type(v) is not list:
data_dic[k].append([timestamp*1000,float(v)])
else: #v = [avg,max,min,mid]
data_dic[k].append([timestamp*1000,float(v[0])]) #暂时只往前台 返回 average数据 for k,v in data_dic.items():
print(k,v) return data_dic
2、生成流量图
from monitor import models
import json
from CrazyMonitor import settings class GraphGenerator2(object):
'''
产生流量图
'''
def __init__(self,request,redis_obj):
self.request = request
self.redis = redis_obj
self.host_id = self.request.GET.get('host_id')
self.time_range = self.request.GET.get('time_range') def get_host_graph(self):
'''
生成此主机关联的所有图
:return:
'''
host_obj = models.Host.objects.get(id=self.host_id)
service_data_dic = {}
template_list = list(host_obj.templates.select_related())
for g in host_obj.host_groups.select_related():
template_list.extend(list(g.templates.select_related()))
template_list = set(template_list)
for template in template_list:
for service in template.services.select_related():
service_data_dic[service.id] = {
'name':service.name,
'index_data':{},
'has_sub_service': service.has_sub_service,
'raw_data':[],
'items': [item.key for item in service.items.select_related() ]
}
'''if not service.has_sub_service:
for index in service.items.select_related():
service_data_dic[service.id]['index_data'][index.key] = {
'id': index.id,
'name':index.name,
'data':[]
}
#else: #like nic service
''' print(service_data_dic)
#service_data_dic
#开始取数据
for service_id,val_dic in service_data_dic.items():
#if val_dic['has_sub_service'] == False:
service_redis_key = "StatusData_%s_%s_%s" %(self.host_id,val_dic['name'],self.time_range)
print('service_redis_key',service_redis_key)
service_raw_data = self.redis.lrange(service_redis_key,0,-1)
service_raw_data = [item.decode() for item in service_raw_data]
service_data_dic[service_id]['raw_data'] = service_raw_data return service_data_dic
3、画图展示
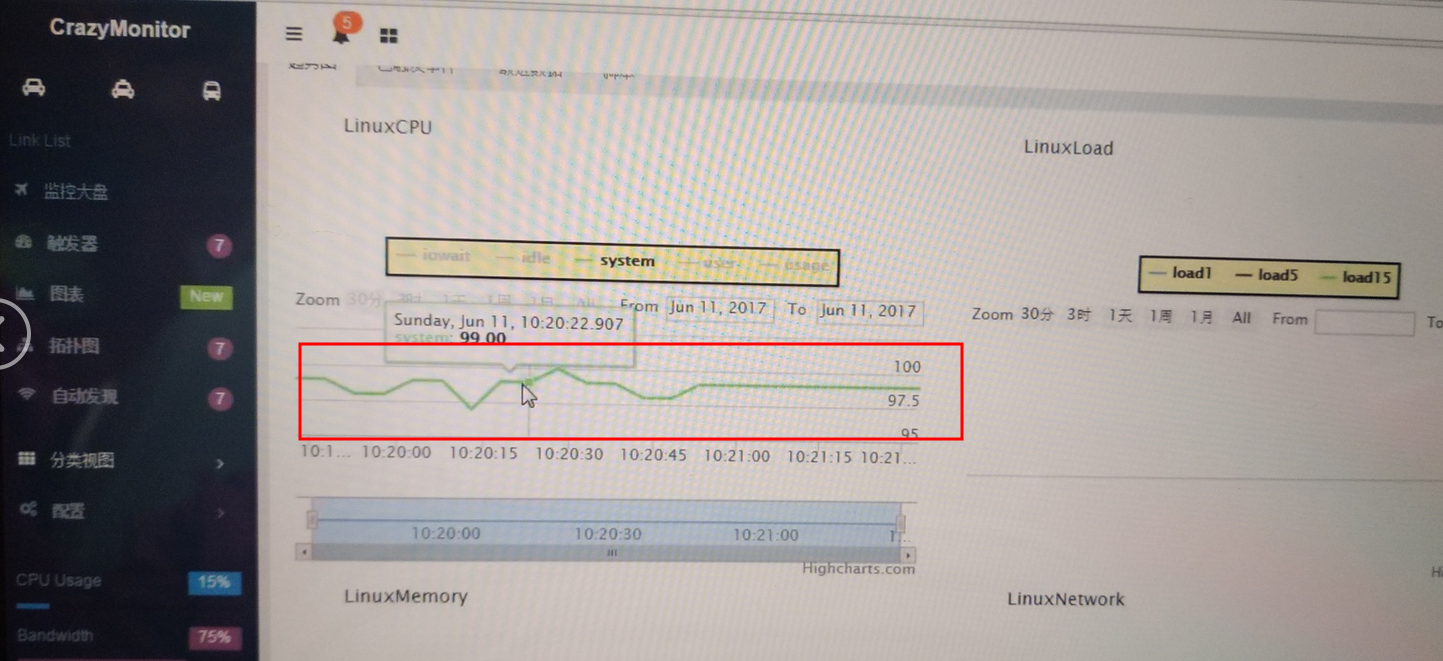
二、国外画图软件hcharts
1、官方网址
www.hcharts.cn
2、静态图讲解
3、动态图片讲解
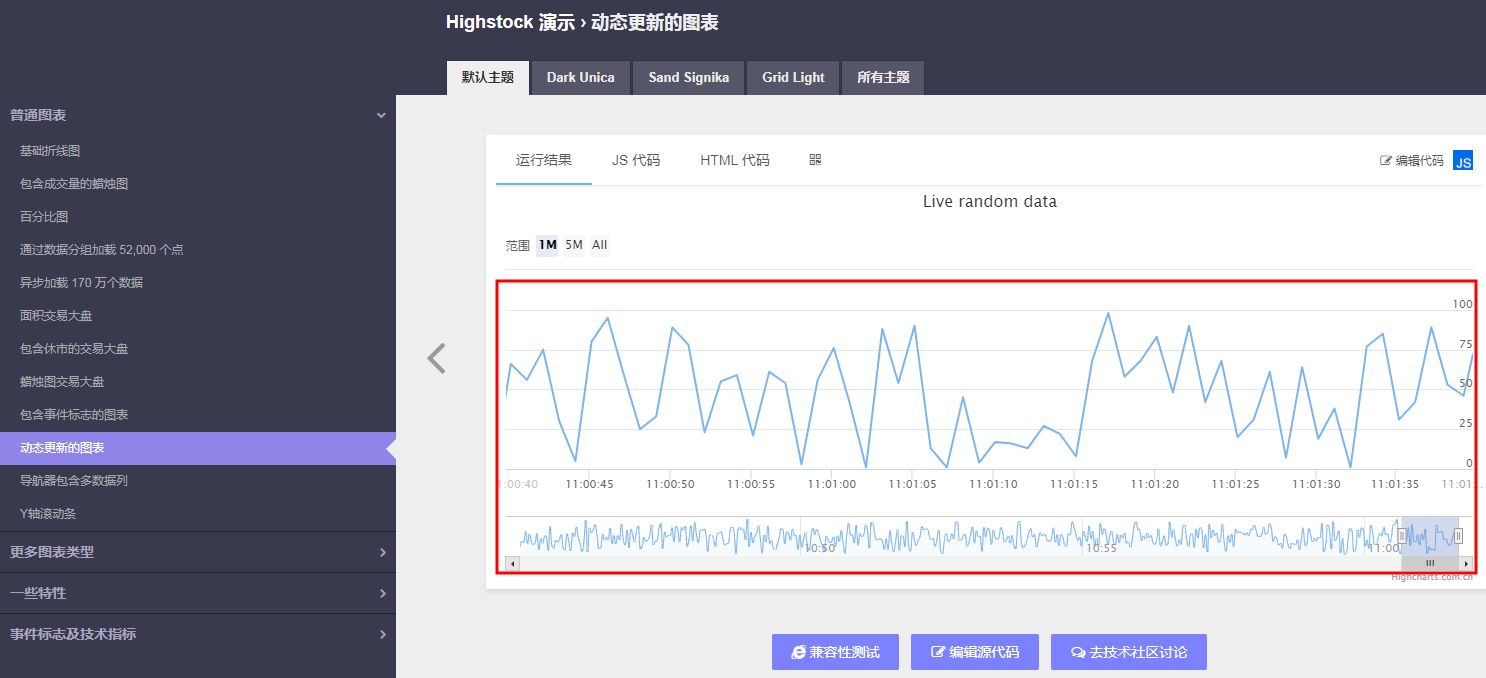
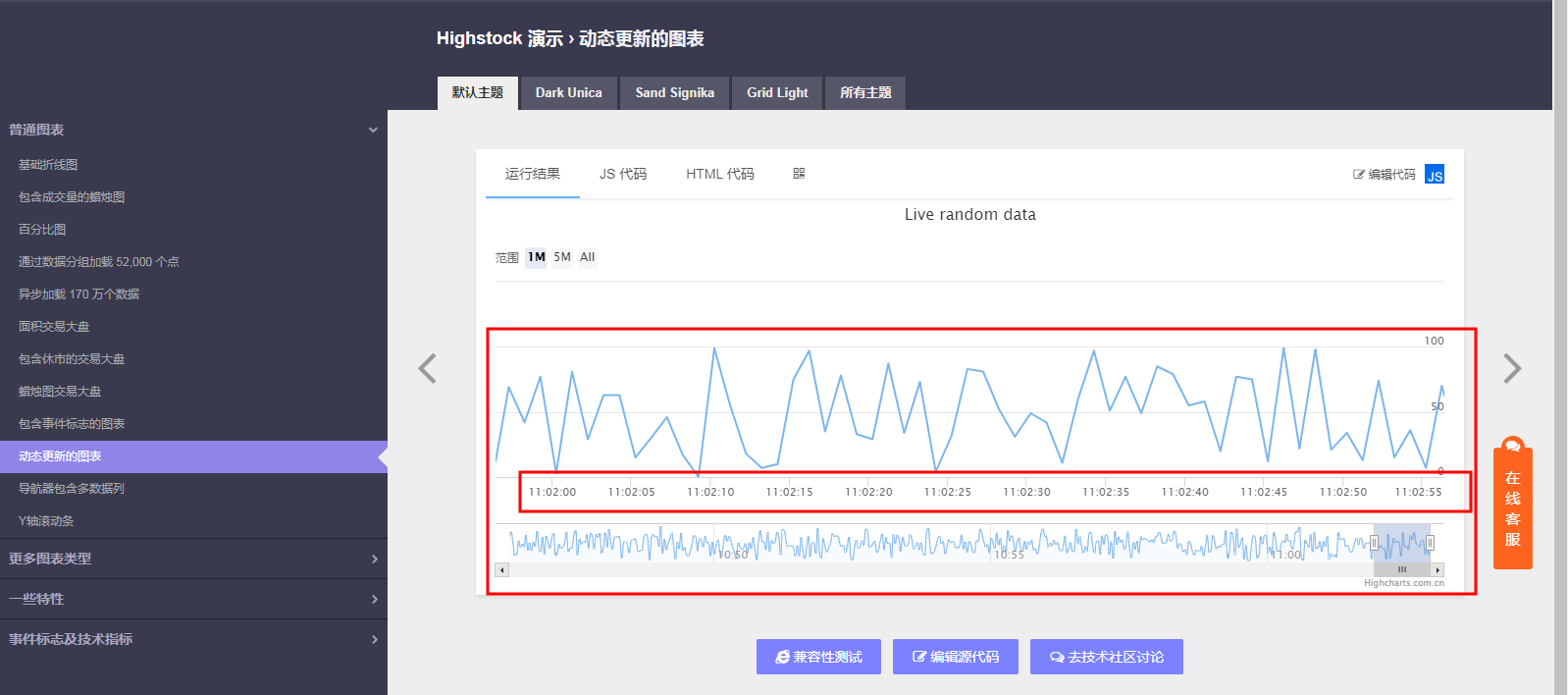
动态看红框
4、API使用
1、数据格式
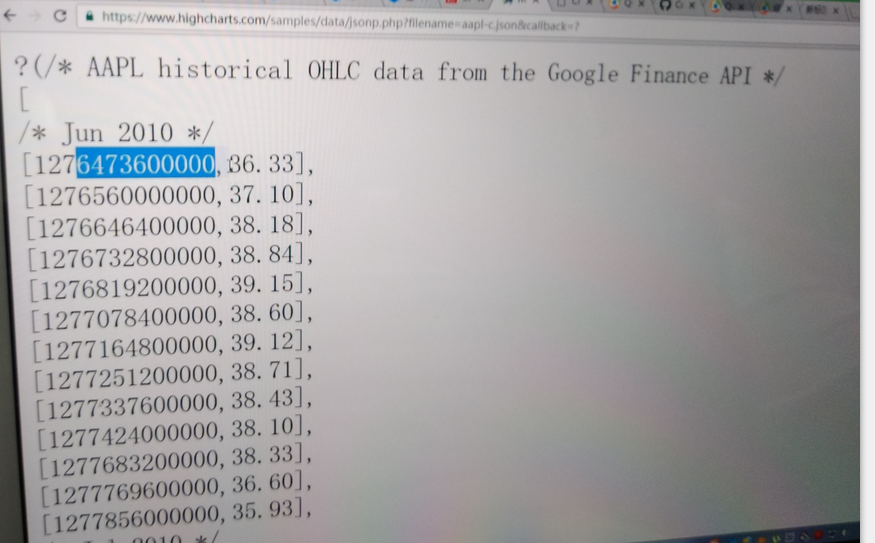
2、api文档
https://api.hcharts.cn/6/highcharts/index.html
截图
3、文档教程
https://www.hcharts.cn/docs
截图

三、国内百度echarts
1、官方网址
http://echarts.baidu.com/index.html
2、地图展示
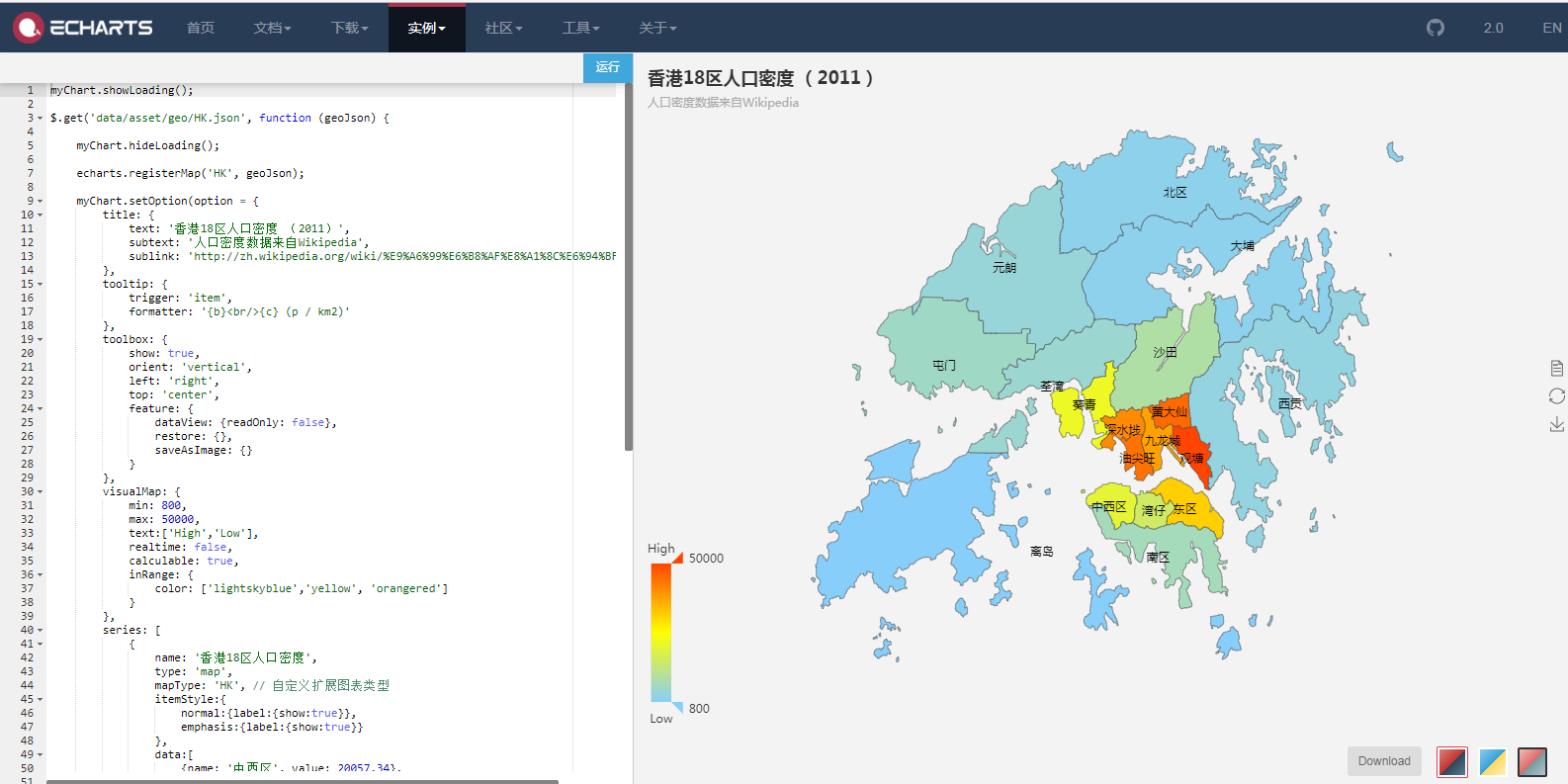
3、3D图展示
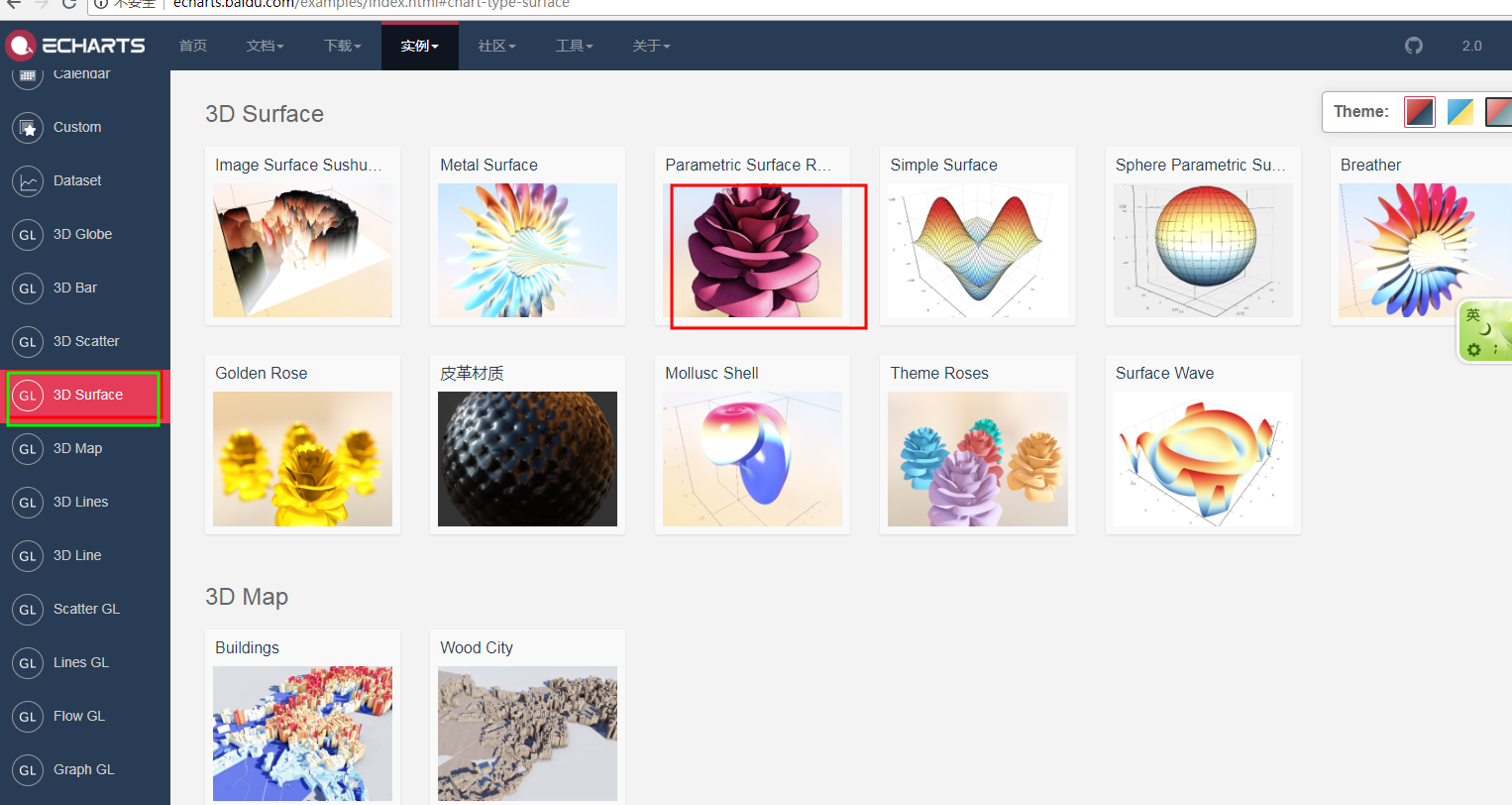
4、文档
1、地址
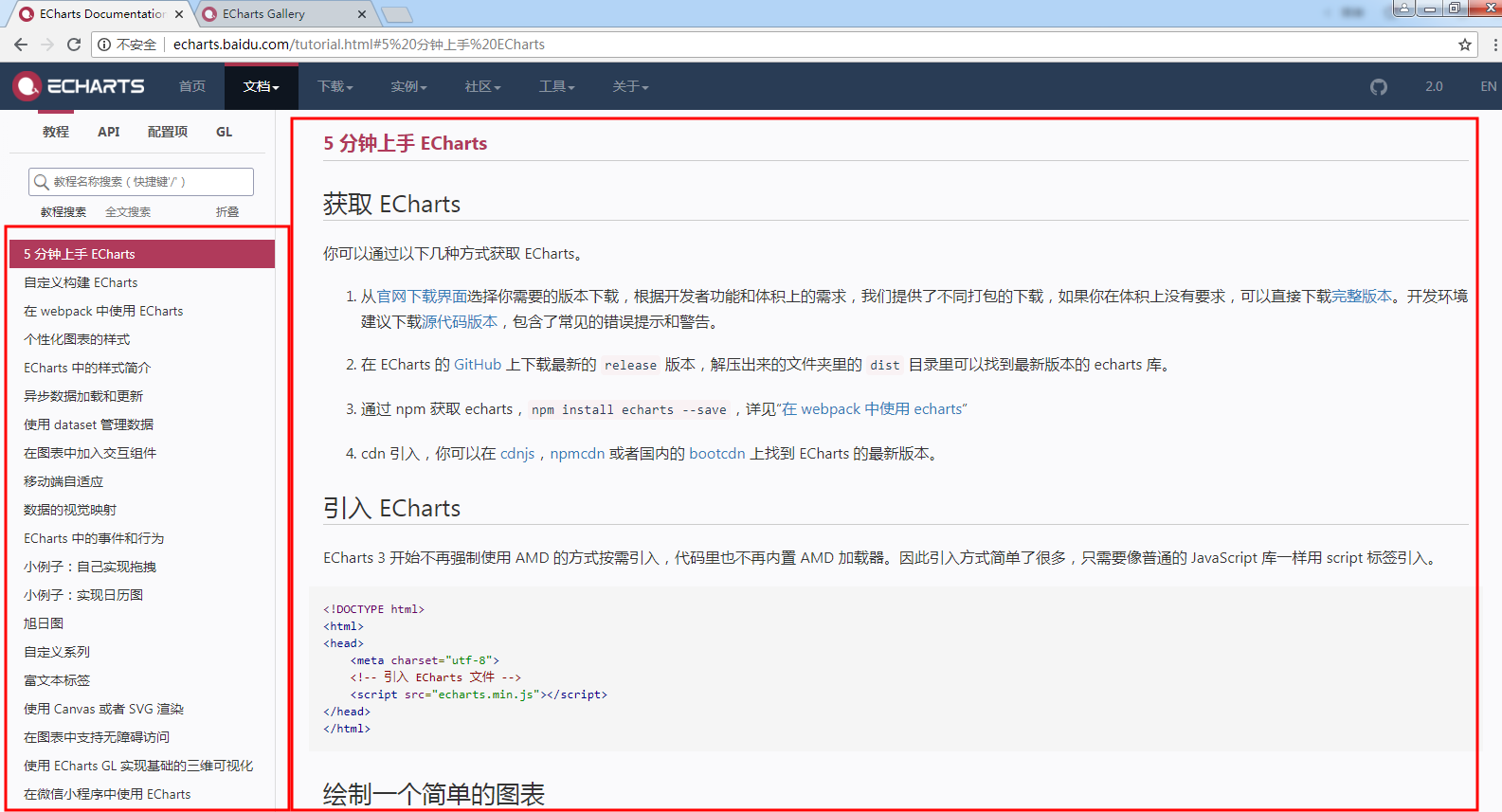
http://echarts.baidu.com/tutorial.html#5%20%E5%88%86%E9%92%9F%E4%B8%8A%E6%89%8B%20ECharts
2、截图
分布式监控系统开发【day38】:监控数据如何画图(九)的更多相关文章
- Python之路,Day20 - 分布式监控系统开发
Python之路,Day20 - 分布式监控系统开发 本节内容 为什么要做监控? 常用监控系统设计讨论 监控系统架构设计 监控表结构设计 为什么要做监控? –熟悉IT监控系统的设计原理 –开发一个 ...
- day26 分布式监控系统开发
本节内容 为什么要做监控? 常用监控系统设计讨论 监控系统架构设计 监控表结构设计 为什么要做监控? –熟悉IT监控系统的设计原理 –开发一个简版的类Zabbix监控系统 –掌握自动化开发项目的程序设 ...
- 分布式监控系统开发【day37】:需求讨论(一)
本节内容 为什么要做监控? 常用监控系统设计讨论 监控需求讨论 如何实现监控服务器的水平扩展? 监控系统架构设计 一.为什么要做监控? 熟悉IT监控系统的设计原理 开发一个简版的类Zabbix监控系统 ...
- Python之分布式监控系统开发
为什么要做监控? –熟悉IT监控系统的设计原理 –开发一个简版的类Zabbix监控系统 –掌握自动化开发项目的程序设计思路及架构解藕原则 常用监控系统设计讨论 Zabbix Nagios 监控系统需求 ...
- 基于类和redis的监控系统开发
最近学习python运维开发,编写得一个简单的监控系统,现记录如下,仅供学习参考. 整个程序分为7个部分: 第一个部分根据监控架构设计文档架构如下: .├── m_client│ ├── conf ...
- 分布式监控系统Zabbix3.2监控数据库的连接数
在 分布式监控系统Zabbix3.2跳坑指南 和 分布式监控系统Zabbix3.2给异常添加邮件报警 已经介绍了如何安装以及报警.此篇通过介绍监控数据库的3306端口连接数来了解如何监控其它端口和配置 ...
- 基于SkyWalking的分布式跟踪系统 - 微服务监控
上一篇文章我们搭建了基于SkyWalking分布式跟踪环境,今天聊聊使用SkyWalking监控我们的微服务(DUBBO) 服务案例 假设你有个订单微服务,包含以下组件 MySQL数据库分表分库(2台 ...
- 移动物体监控系统-sprint3移动监控主系统设计与开发
一.移动监控的原理 通过获取摄像头图像,比较前后每一帧的图像数据,从而实现移动物体监控.所有移动监控原理都是这样,只是图像帧的对比的算法不一样. 二.移动物体监控系统的实现 选择开源的移动监控软件mo ...
- 阶段2-新手上路\项目-移动物体监控系统\Sprint3-移动监控主系统设计与开发
移动图像监控系统 去找一些相关开源程序进行移植:百度搜索-linux 移动监控 motion是一套免费开源的移动图像监测程序 前面我们已经使用了很多开源软件,他们的使用方法都是大同小异的 1).先在当 ...
- Linux记录-监控系统开发
需求:使用shell定制各种个性化告警工具,但需要统一化管理.规范化管理.思路:指定一个脚本包,包含主程序.子程序.配置文件.邮件引擎.输出日志等.主程序:作为整个脚本的入口,是整个系统的命脉.配置文 ...
随机推荐
- 【原】Java学习笔记015 - 面向对象
package cn.temptation; public class Sample01 { public static void main(String[] args) { // 传递 值类型参数 ...
- easyUI行删除
function removeRow(target,number) { if (number) { var index = getRowIndex(target); $datagrid.datagri ...
- Python操作MySQL:pymysql模块
连接MySQL有两个模块:mysqldb和pymysql,第一个在Python3.x上不能用,所以我们学pymysql import pymysql # 创建连接 conn = pymysql.con ...
- bibli直播弹幕实时爬取
1 分析数据来源 在不知道弹幕信息在哪里的时候,只能去all里面查看每一个相应的信息,看信息是否含有弹幕信息 在知道弹幕信息文件的时候,我们可以直接用全局文件搜索,定位到弹幕数据文件.操作如下图 2 ...
- Offset Management For Apache Kafka With Apache Spark Streaming
An ingest pattern that we commonly see being adopted at Cloudera customers is Apache Spark Streaming ...
- day9-基础函数的学习(四)
这几天一直赶着写写作业,博客的书写又落下了,要加油鸭,开写 今日份目录 1.内置函数 2.递归函数 开始今日份总结 1.内置函数 内置函数就是python内部包含的函数,总计有68种,不过有些事真的天 ...
- 《通过C#学Proto.Actor模型》之Behaviors
Behaviors就是Actor接收到消息后可以改变处理的方法,相同的Actor,每次调用,转到不同的Actor内方法执行,非常适合按流程进行的场景.Behaviors就通过在Actor内部实例化一个 ...
- Java 控制语句
Java 控制语句
- Linux下安装 Python3
前言 Linux下大部分系统默认自带python2.x的版本,最常见的是python2.6或python2.7版本,默认的python被系统很多程序所依赖,比如centos下的yum就是python2 ...
- OSGI打安装包步骤(底包制作)
相关资源下载 equinox-SDK-LunaSR2 : https://pan.baidu.com/s/1xOzZZ3_VAuQJ3Zfp4W8Yyw 提取码: gjip gemini-web- ...