python反反爬,爬取猫眼评分
python反反爬,爬取猫眼评分.
解决网站爬取时,内容类似:$#x12E0;样式,且每次字体文件变化。
下载FontCreator

.
用FontCreator打开base.woff.查看对应字体关系
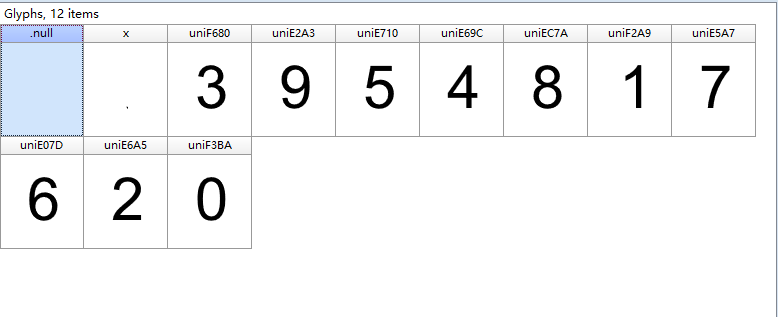
初始化时将对应关系写入字典中。
#!/usr/bin/env python
# coding:utf-8
# __author__ = "南楼" import requests
import re
import os from fontTools.ttLib import TTFont #下载字体
class MaoYan(object): def __init__(self):
self.url = 'http://maoyan.com/films/1198214'
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"
}
self.base_num = {} # 编号—数字
self.base_obj = {} # 编号—对象
# base.woff 为当前网站下载的一个字体
self.base_font_file = TTFont('./fonts/base.woff')
# 需要先下载字体编辑软件(FontCreator),以便查看对应关系
self.base_num["uniF3BA"] = ""
self.base_num["uniF2A9"] = ""
self.base_num["uniE6A5"] = ""
self.base_num["uniF680"] = ""
self.base_num["uniE69C"] = ""
self.base_num["uniE710"] = ""
self.base_num["uniE07D"] = ""
self.base_num["uniE5A7"] = ""
self.base_num["uniEC7A"] = ""
self.base_num["uniE2A3"] = "" for key in self.base_num:
self.base_obj[key] =self.base_font_file['glyf'][key] def baseobj(self):
for key in self.base_num: self.base_obj[key] =self.base_font_file['glyf'][key] # 获得woff内编号对应的字体对象
return self.base_obj # 发送请求获得响应
def get_html(self, url):
response = requests.get(url, headers=self.headers)
return response.content def create_font(self, re_font_file):
# 列出已下载文件
file_list = os.listdir('./fonts')
# 判断是否已下载
if re_font_file not in file_list: print('不在字体库中, 下载:', re_font_file)
url = 'http://vfile.meituan.net/colorstone/' + re_font_file
new_file = self.get_html(url)
with open('./fonts/' + re_font_file, 'wb') as f:
f.write(new_file) # 打开字体文件,创建 self.font_file属性
self.font_file = TTFont('./fonts/' + re_font_file) def get_num_from_font_file(self, re_star): newstar = re_star.upper().replace("&#X", "uni")
realnum = newstar.replace(";", "")
numlist = realnum.split(".")
# gly_list = self.font_file.getGlyphOrder() #uni列表['glyph00000', 'x', 'uniF680', 'uniE2A3', 'uniE710', 'uniE69C', 'uniEC7A', 'uniF2A9', 'uniE5A7', 'uniE07D', 'uniE6A5', 'uniF3BA']
star_rating = []
for hax_num in numlist:
font_file_num = self.font_file['glyf'][hax_num]
for key in self.baseobj():
if font_file_num == self.base_obj[key]:
star_rating.append(self.base_num[key])
# 星级评分待优化,暂不支持10.0,
star_rating = star_rating[0]+"."+star_rating[1]
return star_rating def start_crawl(self):
html = self.get_html(self.url).decode('utf-8') # 正则匹配字体文件
re_font_file = re.findall(r'vfile\.meituan\.net\/colorstone\/(\w+\.woff)', html)[0]
self.create_font(re_font_file)
# 正则匹配星级评分
re_star_rating = re.findall(r'<span class="index-left info-num ">\s+<span class="stonefont">(.*?)</span>\s+</span>', html)[0]
star_rating = self.get_num_from_font_file(re_star_rating)
print("星级评分:", star_rating) if __name__ == '__main__': m = MaoYan()
m.start_crawl()
python反反爬,爬取猫眼评分的更多相关文章
- python+requests+re匹配抓取猫眼上映电影信息
python+requests抓取猫眼中上映电影,re正则匹配获取对应电影的排名,图片地址,片名,主演及上映时间和评分 import requests import re, json def get_ ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 【Python必学】Python爬虫反爬策略你肯定不会吧?
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 正文 Python爬虫反爬策略三部曲,拥有这三步曲就可以在爬虫界立足了: ...
- python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题
python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题 一丶爬虫概述 通过编写程序'模拟浏览器'上网,然后通 ...
- 票房和口碑称霸国庆档,用 Python 爬取猫眼评论区看看电影《我和我的家乡》到底有多牛
今年的国庆档电影市场的表现还是比较强势的,两名主力<我和我的家乡>和<姜子牙>起到了很好的带头作用. <姜子牙>首日破 2 亿,一举刷新由<哪吒之魔童降世&g ...
- python应用-爬取猫眼电影top100
import requests import re import json import time from requests.exceptions import RequestException d ...
- Python 爬取 猫眼 top100 电影例子
一个Python 爬取猫眼top100的小栗子 import json import requests import re from multiprocessing import Pool #//进程 ...
随机推荐
- js中return false; jquery中需要这样写:return false(); Jquery 中循环 each的用法 for循环
js中return false; jquery中需要这样写:return false(); Jquery 中循环 each的用法 $(".progressName").each(f ...
- __x__(47)0910第六天__IE6到IE11对于包含中文路径的png显示问题
问题:IE6额外地除了中文路径外,对于png24的支持度不高,以致于无法透明. 解决方法1,png8 替换: png8 比 png24 小,质量较低,但是在这里可以替代,以解决问题. 使用 ps 打开 ...
- [LeetCode] Largest Sum of Averages 最大的平均数之和
We partition a row of numbers A into at most K adjacent (non-empty) groups, then our score is the su ...
- day29 二十九、元类、单例
一.eval.exec内置函数 1.eval函数 eval内置函数的使用场景: ①执行字符串会得到相应的执行结果 ②一般用于类型转换得到dict.list.tuple等 2.exec函数 exec应用 ...
- js表单提交到后台对象接收
$.extend({ StandardPost:function(url,args){ var form = $("<form method='post' target='_blank ...
- 关于JQuery中$.get()和$.post()和$.ajax()的区别和使用
首先,这三个方法都是Ajax方法中一种与服务器交换数据的请求类型. 一.$.get() $.get() 方法使用 HTTP GET 请求从服务器加载数据. 使用格式: $.get(url,[data] ...
- RuntimeError: implement_array_function method already has a docstring
根源:Numpy/Scipy/Pandas/Matplotlib/Scikit-learn 出现冲突 解决办法: pip uninstall scikit-learn pip uninstall ma ...
- Linux替换动态库导致正在运行的程序崩溃
在替换so文件时,如果在不停程序的情况下,直接用 cp new.so old.so 的方式替换程序使用的动态库文件会导致正在运行中的程序崩溃.解决的办法是采用“rm+cp” 或“mv+cp” 来替代直 ...
- uCOS-II
/****************************************************/ **关于移植,ucos官网上给的有template,主要思想是实现任务切换的两个函数(任务 ...
- windows red5相关
red5部署 前段时间把red5服务器搭建好了,现在记录下是如何搭建的.1,下载对应版本的red5https://github.com/Red5/red5-server/releases2,如果没有安 ...