企业业务数据处理用“work”还是“MQ”
近期公司在做架构梳理已经项目架构方向,不知不觉就引起了使用“work”跑数据还是用“MQ”进行跑数据的争论!
对于争论这件事在各行各业都有,其实我觉得针对“争论”这个词的根源在于一件事情有很多解决方案,每个人的认知不同,
给出的解决方案也不同。然而如果有一个对实际情况都了解和对解决问题有充足认知的情况下,我想他是会权衡利弊的。
我们先列举几个已经算是比较成熟的开源框架:
WORK:TBschedule、Quartz、spring schedule、JDK的time ,线程池定时等;
MQ:RocketMQ、RabbitMQ、Kafka、ActiveMQ、MSMQ、ZeroMQ等等;
好,废话不多说,我们就事论事,我们就单纯的从以下几个角度来评论以下到底谁(work/mq)更有优势:
1、易用性
2、可扩展性
3、可监控性
4、性能
5、可堆积数据量
6、稳定性
以上是我列出的几个对比选项,我们将逐一解说。(对于work和MQ的选型不是本人讨论的范围不做深入讨论)
我们就拿上面列出的work系列的第一个与MQ系列的第一个进行比较:
Tbshcedule与RocketMQ,这两个都是阿里开发并开源的比较起来可能会更好一点。擂台开始

1、易用性
WORK:TBSchedule最新版本使用zookeeper作为注册一致性等功能的调和器,zookeeper本身很稳定不用怎么管理,
开发代码是直接继承接口,然后自己实现业务逻辑,处理完成之后需要做状态回传处理(比如更新数据状态)
处理失败,会多次重复处理可能会因为一条数据的失败而导致后面数据处理不了(除非自己做优先级策略)
定义数据平均分发策略。
读取数据会平均分发到对应的处理器类,可批量,部署的时候需要调整策略,最小时间间隔是1s
RocketMQ:开源的架构模式为多个节点注册到命名服务,生产者与消费者以及broker的分发负载通过命名服务来管理。
开发代码同样是继承接口实现,然后数据分发到对应的处理器类,最后成功与否返回对应的ack,处理失败不影响
后续数据处理,失败数据会延迟重复处理多次。同样可批量,没有定时执行的概念,有数据就处理,几乎不会等待。
小结:处理数据同样都依赖数据状态标记,但是RocketMQ已经为我们实现了基本失败处理的简单机制,不是特别的情况,
已经足够用了,这是优势之一,数据处理状态不用与第三方系统交互,这是优势之二。其中有TBSchedule有一点就是
自己定义数据平均分发策略,目前不能评判是缺点还是优点,文章后面会说明
2、可扩展性
可扩展性从两个方面讲,一个是基础服务,一个是消费服务。
基础服务就是我用这两个框架的时候肯定需要相关的基础作为支撑,比如TBSchedule需要zookeeper,RocketMQ需要borker等
基础服务:
WORK:TBSchedule需要zookeeper,zookeeper的可扩展性比较一般,是CP型的,不过zookeeper非常稳定可以互相抵消
RocketMQ:需要架设broker和namespace两种服务,两种服务都是可以平行横向扩展的,
然而RocketMQ的主要数据交换服务broker是可以在线透明扩展的,不用重启生产和消费客户端
小结:基础服务说实话可比性不是很强烈,都比较稳定,没有相差太大。
消费服务:
WORK:TBSchedule任务处理客户端可以直接copy一份然后运行起来,注册一下,调整一下线程分配,虽然有步骤但是还算简单
RocketMQ:直接copy处理程序运行包启动运行就OK了,线程会自动调节(开发的时候会根据服务器配置业务量等调整一个合理的范围)
小结:是不是感觉RocketMQ更方便那,大家了解了架构之后自然会知道两个的区别。
3、可监控性
WORK:TBSchedule只有任务主机及线程存活监控监控,数据挤压以及处理速度需要自己额外开发
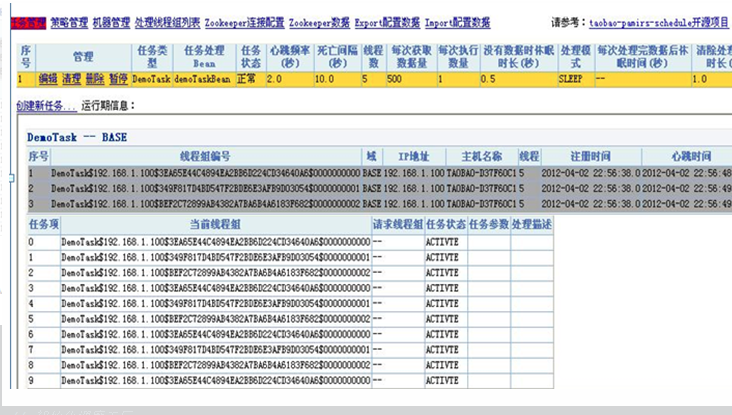
RocketMQ:对数据处理实例(消费端)等都有数据处理速度和待处理积压量相关显示。
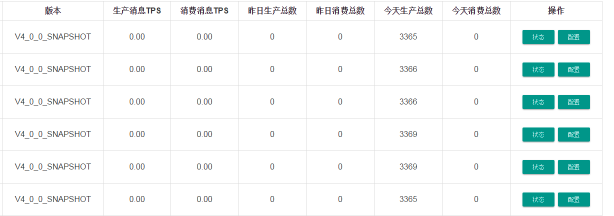
小结:不知道大家更需要哪个,哪个更好,自己斟酌选择吧!这个不多说
4、性能
其实对于性能我就不展开说了没什么可比性,关键是取决于业务处理的速度,如果非要较真的话,
TBSchedule每个线程执行有1秒的停顿,不过这个可以忽略(不要告诉我说你就处理10几条数据,每条几毫秒就处理完了)
虽然不较真但是从第一点易用性看还是有差别的,因为RocketMQ做数据状态回传的时候应该会更快,因为不依赖其他数据载体,
因为数据载体就是broker本身,优化的更好。
5、可堆积数量
两个框架的堆积数量也不太好比较,因为TBSchedule依赖的是其他数据载体(比如数据库),
RocketMQ使用的是索引加文件几乎是无限堆积(为什么是“几乎”,自行查资料,关键取决于磁盘大小)
这里反过来对第四点做一点补充就是,堆积量上来之后对于RocketMQ性能几乎没什么影响,
但是对于TBSchedule可能就取决于数据载体了
6、稳定性
这个也不展开讨论,直接说实际使用情况
TBSchedule会有时不时的莫名其妙的假死现象
RocketMQ最多是因为硬件承载量不够而拒绝服务,但是还是能提供服务的。
大家自己心里评判吧!
可能有很多人说这两个东西是没有可比性的,因为根本就是不同的框架,一个是定时任务一个是消息传输,说的很对,但是你反过来想
都是为了处理业务数据,都是将数据从一种状态或结构转换成另一种。很多情况下两者都可以做完同样的事情,所以就带来了争论和选择
如果你那RocketMQ和操作系统linux比较我想这真的是没有可比性的。
最后还是简单总结一下
Work和MQ都是随时代或者说是技术发展的过程逐渐演变的,work是定时任务的高级扩展,MQ是伴随着业务发展而逐渐流行起来的框架设计
两者都在企业信息化发展中起到关键的作用,然而work却在逐渐慢慢消退,但是不太可能会被替代(这里不是指被MQ替代),当然更不会被MQ替代
MQ框架现在发展非常迅猛,虽然在一段时间内还会非常迅猛,同样时代在变化,技术在发展,慢慢陨落是不可避免的,只是时间问题而已。
两个框架都有自己更适合的使用场景(使用场景包括人和业务这里就不具体举例说明了),脱离业务的设计都是耍流氓。
希望本篇文章对你有帮助。
企业业务数据处理用“work”还是“MQ”的更多相关文章
- 大数据BI系统挖掘企业业务上的价值
相信关注过我们的肯定知道BI是什么,但是老话常谈以防新朋友不知道BI的含义,BI(Business Intelligence)即商务智能,它是一套完整的解决方案,用来将企业中现有的数据进行有效的整合 ...
- ChatOps如何变革企业业务
[编者按]本文作者为日志分析软件公司 Logz.io 的联合创始人 Tomer Levy,主要介绍 ChatOps 的特点与发展历程,以及将来可能带来的业务变革.文章系国内 ITOM 管理平台 One ...
- AI落地企业业务的一些问题
这两年大家都在喊未来已来,软件企业不管有没有算法工程师都竖起了AI的大旗,传统企业不管现在OA现状如何都想在数据转型.智能制造.机器智能方面尝尝鲜,感觉好像和前两年的互联网+风潮有点像,最近半年我在某 ...
- 什么是业务运维,企业如何实现互联网+业务与IT的融合
业务运维并不是一个新概念,针对传统信息架构提出的业务服务管理就是把以业务为核心的IT系统与IT基础设施性能进行整合运维的解决方案.然而随着互联网+转型的不断推进,基础设施的智能化和广泛云化成为IT发展 ...
- 迅雷程浩:企业外包服务,下一个大的风口?(2B业务一定要懂销售和营销的人,这点和2C 不一样)
我今年暑假去了趟硅谷,一天去一个朋友的公司拜访,发现这公司没有前台,前台桌子上放了一个显示器.我刚进去,显示器里的老印就跟我打招呼 "How may I help you?" 事后 ...
- JSAAS BPM快速开发平台-企业管理软件,专属你的企业管家
前言: 2020年,企业该如何去选择合适的信息化规划管理软件,基于目前社会软件杂乱无章,选择企业业务贴近的管理软件,甚是困难,市场上一些大品牌公司的产品,定位高,价格高,扩展难,等等一系列的问题,对于 ...
- 某中国500强企业BI系统成功应用案例
随着某集团20多年的不断发展发展,现已成为中国500强.中国大企业集团竞争力前25强.中国信息化标杆企业和国家重点火炬高新技术企业.拥有总资产数十亿元.员工数万名,涉足电力.家电.能源.等多个行业,并 ...
- Slickflow.NET 开源工作流引擎基础介绍(二) -- 引擎组件和业务模块的交互
集成流程引擎的必要性 业务过程的变化是在BPM系统中常见的现象,企业管理层需要不断优化组织架构,改造业务流程,不可避免地带来了业务流程的变化,企业信息系统就会随之面临重构的可能性.一种直接的方式是改造 ...
- ESB 企业服务总线
整理的OSChina 第 38 期高手问答 —— ESB 企业服务总线,嘉宾为@肖俊_David . @肖俊_David 恒拓开源架构师,热衷于JAVA开发,有多年的企业级开发经验.曾参和设计和开发基 ...
随机推荐
- .NET Core实战项目之CMS 第十三章 开发篇-在MVC项目结构介绍及应用第三方UI
作为后端开发的我来说,前端表示真心玩不转,你如果让我微调一个位置的样式的话还行,但是让我写一个很漂亮的后台的话,真心做不到,所以我一般会选择套用一些开源UI模板来进行系统UI的设计.那如何套用呢?今天 ...
- Elasticsearch之删除索引
1. #删除指定索引 # curl -XDELETE -u elastic:changeme http://localhost:9200/acc-apply-2018.08.09 {&qu ...
- python:数据库连接操作入门
模块 import pymssql,pyodbc 模块说明 pymssql和pyodbc模块都是常用的用于SQL Server.MySQL等数据库的连接及操作的模块,当然一些其他的模块也可以进行相应的 ...
- 行为驱动:Cucumber + Selenium + Java(四) - 实现测试用例的参数化
在上一篇中,我们介绍了Selenium + Cucumber + Java框架下的使用Tags对测试用例分组的实现方法,这一篇我们用数据表格来实现测试用例参数化. 4.1 什么是用例参数化 实际测试中 ...
- RabbitMQ消息队列(八)-通过Topic主题模式分发消息(.Net Core版)
前两章我们讲了RabbitMQ的direct模式和fanout模式,本章介绍topic主题模式的应用.如果对direct模式下通过routingkey来匹配消息的模式已经有一定了解那fanout也很好 ...
- 从SQL Server CloudDBA 看云数据库智能化
最近阿里云数据库SQL Server在控制台推出了CloudDBA服务,重点解决数据库性能优化领域问题,帮助客户更好的使用好RDS数据库,这是继MySQL之后第二个关系型数据库提供类似的服务. 数 ...
- Spring Boot(十三)RabbitMQ安装与集成
一.前言 RabbitMQ是一个开源的消息代理软件(面向消息的中间件),它的核心作用就是创建消息队列,异步接收和发送消息,MQ的全程是:Message Queue中文的意思是消息队列. 1.1 使用场 ...
- CAN总线学习记录之三:总线中主动错误和被动错误的通俗解释
首先建议把广泛使用的"主动错误"和"被动错误"概念换成"主动报错"和"被动报错". 1. 主动报错站点 只要检查到错误, ...
- 细说MVC中仓储模式的应用
文章提纲 概述要点 理论基础 详细步骤 总结 概述要点 设计模式的产生,就是在对开发过程进行不断的抽象. 我们先看一下之前访问数据的典型过程. 在Controller中定义一个Context, 例如: ...
- C# Quartz定时任务corn时间设置详解
http://cron.qqe2.com/ 如果不会 或者想检验自己是否写的对就 通过这个网站 检测 或自动生成 * * * * * * ...