redis通过pipeline提升吞吐量
案例目标
简单介绍 redis pipeline 的机制,结合一段实例说明pipeline 在提升吞吐量方面发生的效用。
案例背景
应用系统在数据推送或事件处理过程中,往往出现数据流经过多个网元;
然而在某些服务中,数据操作对redis 是强依赖的,在最近的一次分析中发现:
一次数据推送会对 redis 产生近30次读写操作!
在数据推送业务中的性能压测中,以数据上报 -> 下发应答为一次事务;
而对于这样的读写模型,redis 的操作过于频繁,很快便导致系统延时过高,吞吐量低下,无法满足目标;
优化过程 主要针对业务代码做的优化,其中redis 操作经过大量合并,最终降低到原来的1/5,而系统吞吐量也提升明显。
其中,redis pipeline(管道机制) 的应用是一个关键手段。
pipeline的解释
Pipeline指的是管道技术,指的是客户端允许将多个请求依次发给服务器,过程中而不需要等待请求的回复,在最后再一并读取结果即可。
管道技术使用广泛,例如许多POP3协议已经实现支持这个功能,大大加快了从服务器下载新邮件的过程。
Redis很早就支持管道(pipeline)技术。(因此无论你运行的是什么版本,你都可以使用管道(pipelining)操作Redis)
普通请求模型
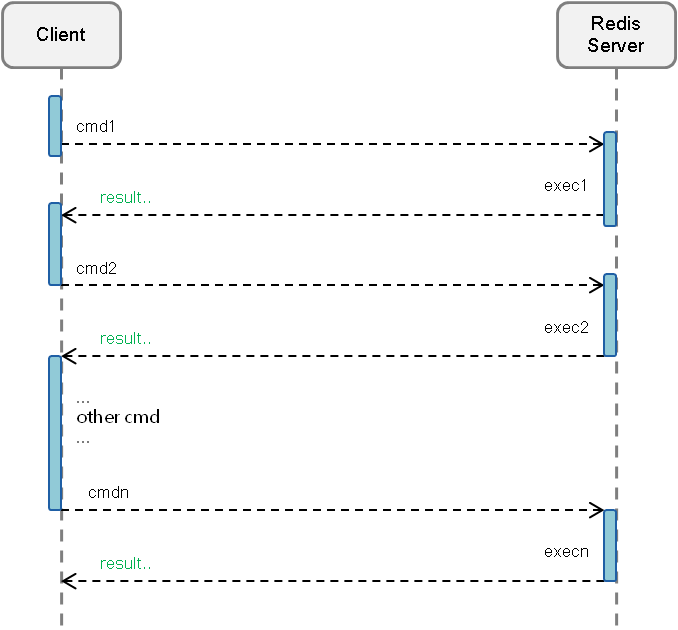
[图-pipeline1]
Pipeline请求模型
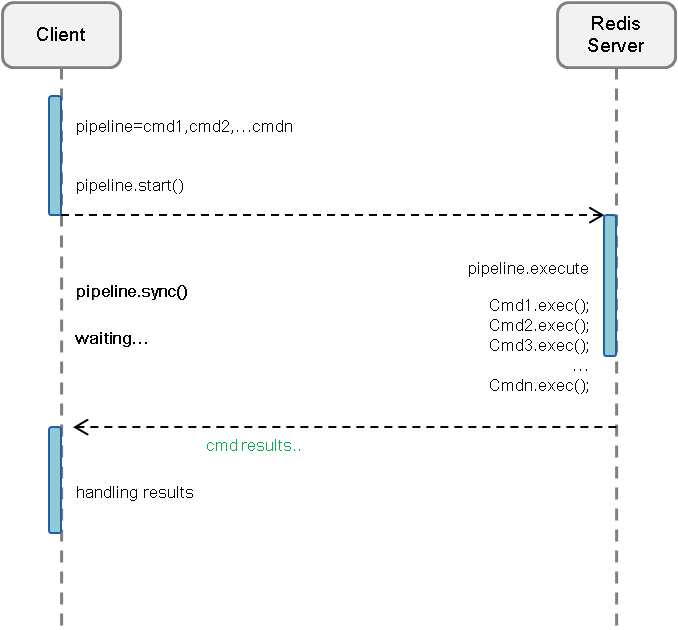
[图-pipeline2]
从两个图的对比中可看出,普通的请求模型是同步的,每次请求对应一次IO操作等待;
而Pipeline 化之后所有的请求合并为一次IO,除了时延可以降低之外,还能大幅度提升系统吞吐量。
代码实例
说明
本地开启50个线程,每个线程完成1000个key的写入,对比pipeline开启及不开启两种场景下的性能表现。
相关常量
// 并发任务
private static final int taskCount = 50;
// pipeline大小
private static final int batchSize = 10;
// 每个任务处理命令数
private static final int cmdCount = 1000;
private static final boolean usePipeline = true;
初始化连接
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxActive(200);
poolConfig.setMaxIdle(100);
poolConfig.setMaxWait(2000);
poolConfig.setTestOnBorrow(false);
poolConfig.setTestOnReturn(false);
jedisPool = new JedisPool(poolConfig, host, port);
并发启动任务,统计执行时间
public static void main(String[] args) throws InterruptedException {
init();
flushDB();
long t1 = System.currentTimeMillis();
ExecutorService executor = Executors.newCachedThreadPool();
CountDownLatch latch = new CountDownLatch(taskCount);
for (int i = 0; i < taskCount; i++) {
executor.submit(new DemoTask(i, latch));
}
latch.await();
executor.shutdownNow();
long t2 = System.currentTimeMillis();
System.out.println("execution finish time(s):" + (t2 - t1) / 1000.0);
}
DemoTask 封装了执行key写入的细节,区分不同场景
public void run() {
logger.info("Task[{}] start.", id);
try {
if (usePipeline) {
runWithPipeline();
} else {
runWithNonPipeline();
}
} finally {
latch.countDown();
}
logger.info("Task[{}] end.", id);
}
不使用Pipeline的场景比较简单,循环执行set操作
for (int i = 0; i < cmdCount; i++) {
Jedis jedis = get();
try {
jedis.set(key(i), UUID.randomUUID().toString());
} finally {
if (jedis != null) {
jedisPool.returnResource(jedis);
}
}
if (i % batchSize == 0) {
logger.info("Task[{}] process -- {}", id, i);
}
}
使用Pipeline,需要处理分段,如10个作为一批命令执行
for (int i = 0; i < cmdCount;) {
Jedis jedis = get();
try {
Pipeline pipeline = jedis.pipelined();
int j;
for (j = 0; j < batchSize; j++) {
if (i + j < cmdCount) {
pipeline.set(key(i + j), UUID.randomUUID().toString());
} else {
break;
}
}
pipeline.sync();
logger.info("Task[{}] pipeline -- {}", id, i + j);
i += j;
} finally {
if (jedis != null) {
jedisPool.returnResource(jedis);
}
}
}
运行结果
不使用Pipeline,整体执行26s;而使用Pipeline优化后的代码,执行时间仅需要3s!
NoPipeline-stat
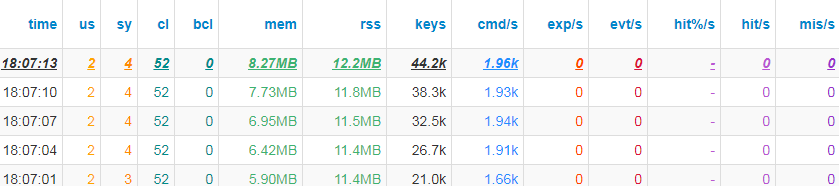
[图-nopipeline]
Pipeline-stat

[图-pipeline]
注意事项
- pipeline机制可以优化吞吐量,但无法提供原子性/事务保障,而这个可以通过Redis-Multi等命令实现。
参考这里 - 部分读写操作存在相关依赖,无法使用pipeline实现,可利用Script机制,但需要在可维护性方面做好取舍。
扩展阅读
官方文档-Redis-Pipelining
官方文档-Redis-Transaction
redis通过pipeline提升吞吐量的更多相关文章
- 【redis】pipeline - 管道模型
redis-pipeline 2020-02-10: 因为我把github相关的wiki删了,所以导致破图...待解决.(讲真github-wiki跟project是2个url,真的不好用) 因为用的 ...
- redis 使用管道提升写入的性能[pipeline]
看了手册的都知道multi这个命令的作用就好比是mysql的事务的功能,但是大家都知道事务吗,就是在操作的过程中,把整个操作当作一个原子来处理,避免由于中途出错而导致最后产生的数据不一致,而产生BUG ...
- 分布式缓存Redis之Pipeline(管道)
Redis的pipeline(管道)功能在命令行中没有,但redis是支持pipeline的,而且在各个语言版的client中都有相应的实现. 由于网络开销延迟,就算redis server端有很强的 ...
- Redis大幅性能提升之Batch批量读写
Redis大幅性能提升之Batch批量读写 提示:本文针对的是StackExchange.Redis 一.问题呈现 前段时间在开发的时候,遇到了redis批量读的问题,由于在StackExchange ...
- Jmeter 压力测试笔记(3)--脚本调试/签名/cookie/提升吞吐量/降低异常率/提升单机并发性能
import XXXsign.Openapi2sign;---导入jar包中的签名方法 String str1 = "12121"; ---需要被签名的字段:向开发了解需要哪些哪些 ...
- redis之pipeline使用
redis之pipeline 我们要完成一个业务,可能会对redis做连续的多个操作,这有很多个步骤是需要依次连续执行的.这样的场景,网络传输的耗时将是限制redis处理量的主要瓶颈. 那么此时就可以 ...
- Redis利用Pipeline加速查询速度的方法
1. RTT Redis 是一种基于客户端-服务端模型以及请求/响应协议的TCP服务.这意味着通常情况下 Redis 客户端执行一条命令分为如下四个过程: 发送命令 命令排队 命令执行 返回结果 客户 ...
- Redis 管道pipeline
Redis是一个cs模式的tcp server,使用和http类似的请求响应协议. 一个client可以通过一个socket连接发起多个请求命令. 每个请求命令发出后client通常会阻塞并等待red ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
随机推荐
- JSON 数据操作
2018,狗年.如果在你出生日期的年份上加12等于2018的话,私聊我,今年是你的本命年,你得发红包!!! 子(鼠).丑(牛).寅(虎).卯(兔).辰(龙).巳(蛇).午(马).未(羊).申(猴).酉 ...
- js网页返回顶部和楼层跳跃的实现原理
这是简单的效果图. (实现楼层间的跳跃,主要依靠的是 window.scrollTo(x,y)方法 ,将浏览器的可见区域移动到指定的x,y坐标上.) 说楼层跳跃前,先温习下,一般网页在高度较大时, ...
- 如何转换MySQL表的引擎
有很多种方法可以将表的存储引擎转换成另一种引擎.每种方法都有其优缺点,在这里介绍四种方法: 选择优先级(pt-online-schema-change > 创建与查询 > 导出和导入 &g ...
- HttpClient 模拟发送Post和Get请求 并用fastjson对返回json字符串数据解析,和HttpClient一些参数方法的deprecated(弃用)的综合总结
最近在做一个接口调用的时候用到Apache的httpclient时候,发现引入最新版本4.5,DefaultHttpClient等老版本常用的类已经过时了,不推荐使用了:去官网看了一下在4.3之后就抛 ...
- Django之cookie验证
先不用太多的蚊子描述什么是cookie,先做一个小实验: 此时我们在谷歌浏览器(一个客户端)和IE浏览器(另一个用户)测试: 刺客我们发现在两台浏览器都可以访问,而且不用进入login验证就可以登录, ...
- sqlalchemy-数据库操作
import datetime from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarat ...
- Luogu P1231 教辅的组成
Luogu P1231 教辅的组成 题目背景 滚粗了的HansBug在收拾旧语文书,然而他发现了什么奇妙的东西. 题目描述 蒟蒻HansBug在一本语文书里面发现了一本答案,然而他却明明记得这书应该还 ...
- TCP/IP(三)数据链路层~1
前言 其实前面一堆讲的物理层的概念,会感觉特别的难理解,因为这是一个非常强大的计算机网络体系的底层知识,没有关系!我们大致了解一下就行了. 一.数据链路层概述 这是百度的简介 看图:理解一下,数据链路 ...
- [bzoj3955] [WF2013]Surely You Congest
首先最短路长度不同的人肯定不会冲突. 对于最短路长度相同的人,跑个最大流就行了..当然只有一个人就不用跑了 看起来会T得很惨..但dinic在单位网络里是O(m*n^0.5)的... #include ...
- 总结过滤器,监听器,servlet的异同点,已经执行顺序。
1.过滤器 Servlet中的过滤器Filter是实现了javax.servlet.Filter接口的服务器端程序,主要的用途是过滤字符编码.做一些业务逻辑判断等.其工作原理是,只要你在web.xml ...