Flume日志采集系统
1.简介
Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。
Flume支持在日志系统中定制各类数据发送方用于收集数据,同时Flume提供对数据进行简单的处理并写到各种数据接受方的能力。
当前Flume有两个版本,Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng (由于Flume-ng经过重大重构与Flume-og有很大不同,使用时需注意区分)
两个版本的区别
Flume-og采用了多Master的方式,为了保证配置数据的一致性,Flume引入了ZooKeeper用于保存配置文件,在配置文件发生变化时,ZooKeeper可以通知Flume Master节点,Flume Master间使用gossip协议同步数据。
Flume-og中读入线程同样做写操作,如果写出慢的话将阻塞 Flume 接收数据的能力。
Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。
Flume-ng读入数据和写出数据现在由不同的工作线程处理(Runner),这种异步的设计使读入线程可以顺畅的工作而无需关注下游的任何问题。
Flume的优势
1.Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS、HBase。
2.当收集数据的速度超过写入数据的时候,此时Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供平稳的数据。
3.Flume的管道是基于事务的,保证了数据在传送和接收时的一致性。
Flume的应用场景
1.Flume可以高效的将多个网站服务器的日志信息存入HDFS/HBase中。
2.除了日志信息以外,Flume也可以用来收集规模宏大的社交网络节点事件数据(比如facebook、twitter、亚马逊)
*本文只阐述Flume-ng版本的组件及使用。
2.Flume的结构模型
Flume由Source、Channel、Sink三大组件组成。
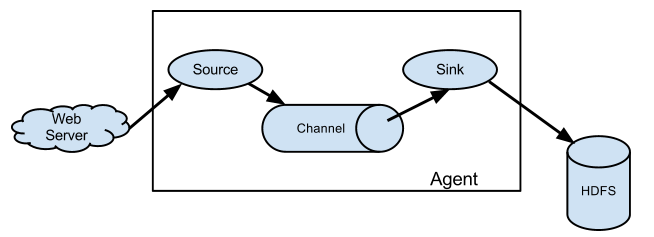
Source:从Client上收集数据并对数据进行格式化,以Event(事件)的形式传递给单个或多个Channel。
Flume的数据流由事件(Event)充当,事件是Flume的基本数据单位,事件携带日志数据(字节数组形式,包含头信息)
Channel:短暂的存储容器,将从Source接收到的Event进行缓存直到被Sink消费掉,Channel是Source和Sink之间的桥梁,Channal是一个完整的事务,能保证了数据在收发时的一致性,并且一个Channel可以同时和任意数量的Source和Sink建立连接。
Sink:从Channel中消费数据(Event)并传递到存储容器(Hbase、HDFS)或其他的Source中。
*Flume以Agent为最小的独立运行单元,Agent依赖于JVM,一个Agent的运行就伴随一个JVM实例的产生。
*一台机器可以运行多个Agent,一个Agent中可以包含多个Source和Sink。
3.各个组件的实现
*Flume提供了大量内置的Source、Channel和Sink类型,不同类型的Source,Channel和Sink可以自由组合,组合方式基于用户设置的配置文件。
Source组件

Channel组件
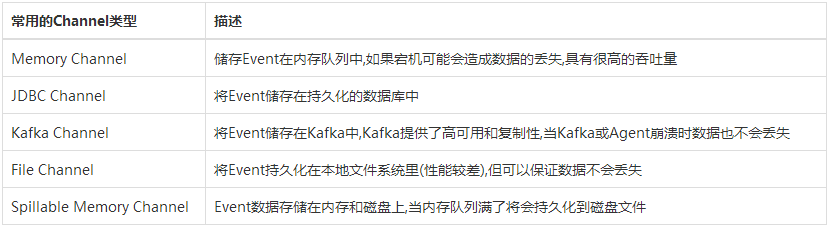
Sink组件

*不同类型的Source、Channel、Sink有其特定的属性,配置时需要根据实际情况去设置。
4.Flume的使用
1.安装
Flume依赖于JDK6以上的版本,因此首先要安装JDK并且添加环境变量JAVA_HOME。

从Flume官网中下载对应的tar.gz安装包 ,将下载后的安装包放到Linux中并进行解压(系统软件放到/usr目录下)
添加Flume的bin目录到PATH环境变量中以便使用

2. 配置文件
在flume的conf目录下创建flume.conf,在该配置文件中进行组件的配置。
#指定Agent的组件名称
agentA.sources = x
agentA.sinks = z
agentA.channels = y #Source组件的相关配置
agentA.sources.x.type = spooldir
agentA.sources.x.spoolDir = /data #Sink组件的相关配置
agentA.sinks.z.type = logger #Channel组件的相关配置
agentA.channels.y.type = memory
agentA.channels.y.capacity =
agentA.channels.y.transactionCapacity = #绑定Source和Sink到Channel上
agentA.sources.x.channels = y
agentA.sinks.z.channel = y
使用Spooling Directory Source类型,监听/data目录下的文件.
使用Memory Channel,事件存储在内存中。
使用Logger Sink,将数据写入Flume的log中。
*当/data目录新增文件后,Spooling Directory Source就会读取文件中的数据,然后将数据以Event形式传给Channel,Logger Sink再消费Channel中的事件将数据写入Log中。
3 .启动
flume-ng agent -c $指定flume的conf目录 -f $指定使用的配置文件 --name $指定要启动的agent名称
Flume日志采集系统的更多相关文章
- Flume日志采集系统——初体验(Logstash对比版)
这两天看了一下Flume的开发文档,并且体验了下Flume的使用. 本文就从如下的几个方面讲述下我的使用心得: 初体验--与Logstash的对比 安装部署 启动教程 参数与实例分析 Flume初体验 ...
- Flume日志采集框架的使用
文章作者:foochane 原文链接:https://foochane.cn/article/2019062701.html Flume日志采集框架 安装和部署 Flume运行机制 采集静态文件到h ...
- 【转】Flume日志收集
from:http://www.cnblogs.com/oubo/archive/2012/05/25/2517751.html Flume日志收集 一.Flume介绍 Flume是一个分布式.可 ...
- Apache Flume日志收集系统简介
Apache Flume是一个分布式.可靠.可用的系统,用于从大量不同的源有效地收集.聚合.移动大量日志数据进行集中式数据存储. Flume简介 Flume的核心是Agent,Agent中包含Sour ...
- flume日志采集框架使用
flume日志采集框架使用 本次学习使用的全部过程均不在集群上,均在本机环境,供学习参考 先决条件: flume-ng-1.6.0-cdh5.8.3.tar 去cloudrea下载flume框架,笔 ...
- Net分布式系统之七:日志采集系统(1)
日志对大型应用系统或者平台尤其重要,系统日志采集.分析是系统运维.维护及用户分析的基础. 一.系统日志分类 一般系统日志可分为三大类: 1.用户行为日志:通过采集系统用户使用系统过程中,一系列的操作日 ...
- 生产系统ELK日志采集系统
总结下,生产在运转的日志采集系统!后续的扩展在于elasticsearch节点与logstash节点与kafka+zookeeper,目的提高吞吐量!
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- scribe、chukwa、kafka、flume日志系统对比
scribe.chukwa.kafka.flume日志系统对比 1. 背景介绍许多公司的平台每天会产生大量的日志(一般为流式数据,如,搜索引擎的pv,查询等),处理 这些日志需要特定的日志系统,一 ...
随机推荐
- Adobe RIA 开发工程师认证考试大纲
AdobeRIA 开发工程师认证考试大纲 考题数量:共90道题,考试通过正确率:60% 考试时间:120分钟 试题种类:单选题.多选题和判断题 1. Adobe RIA基础知识(2道题) ...
- xml字符串转为XmlDocument
string xml = "<xml><logistics_express_get_respose><express_detail><company ...
- C#的动态链接库和XML配置
今天对昨天的实例进行了改进和提高,将堆排序和冒泡排序封装在一个动态链接库中,提供函数调用和事件委托.此外加入XML进行配置,在XML中存入相关配置信息,提供一个单独的XmlClass对其进行操作,加深 ...
- Vue2.0结合webuploader实现文件分片上传
Vue项目中遇到了大文件分片上传的问题,之前用过webuploader,索性就把Vue2.0与webuploader结合起来使用,封装了一个vue的上传组件,使用起来也比较舒爽. 上传就上传吧,为什么 ...
- .Net利用Newtonsoft进行解析Json的快捷方法
现在异构系统之间的数据交换多采用Json格式 .Net如何快捷地解析Json和将Object转换成json呢? 1.利用Newtonsoft解析Json字符串 在百度上查找资料,利用Newtonsof ...
- Shell 的特殊变量
2017-08-02 1.$0 获取当前脚本的名称或全路径 cat name.sh Linux shell sh name.sh echo $0 name.sh 2.$n(n >=1) 获取脚本 ...
- [Luogu2617]Dynamic Rankings(整体二分)
Luogu 动态区间第K大的整体二分解法 之前学主席树的时候就做了这道题(明明是树套树不是主席树啊),码量挺大而且调了我一个晚上.换成整体二分我半个小时就写完了而且一A. 写起来就是爽. 其实原理很简 ...
- [SDOI2013]费用流
然而这是一道网络流... 如果满足Bob,使总费用最大: 设最大流的每条边流量(不是容量)为w[i],分配到每条边的费用为p[i],最大流量为wmax,p[i]的和为P 那么显然w[i] * p[i] ...
- [BZOJ1657] [Usaco2006 Mar] Mooo 奶牛的歌声 (单调栈)
Description Farmer John's N (1 <= N <= 50,000) cows are standing in a very straight row and mo ...
- [BZOJ4542] [Hnoi2016] 大数 (莫队)
Description 小 B 有一个很大的数 S,长度达到了 N 位:这个数可以看成是一个串,它可能有前导 0,例如00009312345.小B还有一个素数P.现在,小 B 提出了 M 个询问,每个 ...