Kylin系列之二:原理介绍
Kylin系列之二:原理介绍
2018年4月15日
15:52
因何而生
Kylin和hive的区别
1. hive主要是离线分析平台,适用于已经有成熟的报表体系,每天只要定时运行即可。
2. Kylin主要是MLOAP(多维在线分析平台)。在线意味着提供快速的相应速度。主要适用于分析师不知道自己需要哪些数据,建立怎样的模型,需要不断的摸索,查询一致形成一个完整的模型和方案。
3. 通常的做法是在Kylin中进行数据的调研,探索,建立模型。形成固定模式后在hive中进行运行。
原理与架构
1. 基本原理是使用MR或者Spark对数据进行全方面的计算;然后将结果集存储到HBase中;分析师在进行数据调研时就可以直接访问HBase的结果集了。
2. 因为在Kylin进行预计算的过程中,我们是不知道分析师需要哪些结果的,因此,Kylin会尽可能多的尽心预计算,这样就会耗费很多的运算和存贮资源。因此如何对Cuboid进行修剪以及segmen的合并等是优化的重点
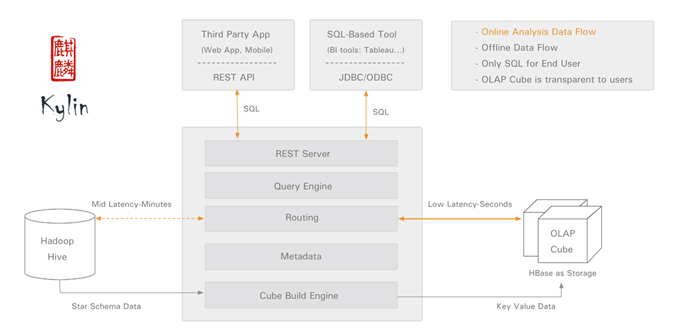
3. 如图我们可以看出Kylin的架构:
A. 预计算逻辑:通过REST API 或者JDBC,ODBC的方式,将Cube提交给Kylin引擎,引擎将Cube解析为相应的MR程序,从hive中获取数据相关的元素据,然后在Hadoop集群中运行,并将结果存储在HBase中。Cube预计算结束
B. 查询预计算逻辑:通过REST API 或者JDBC,ODBC的方式,将Cube提交给Kylin引擎,Kylin将数据解析为相应的HBase代码,在HBase中进行查询,然后将结果返回给调用方
4. Kylin在本质上只是一个查询解析引擎,将Cube或者SQL方言解析为相应的查询语句,然后脚本相应的服务端进行计算
A. Hive:主要提供表的元数据信息。Kylin链接Hive获取查询表在hdfs上的路径。
B. Hadoop:提供基础的数据存储服务。
C. MR/Spark:提供计算引擎,Kylin将Cube解析为相应的执行代码,交给MR/Spark运行。
D. HBase:负责存储Kylin中相关的Cube,Model元数据,并存放Cube进行预计算的结果集。
E. Zeppline/Tableau:进行结果数据的查询与展示。
架构如下(截图来自官网):
基本概念
维度(Dimension)和度量(Measure)
1. 维度是观察数据的角度,比如:人的性别,学生的年级等。在SQL中,我们可以认为被group by的字段就是维度。也可以理解为统计中的称名数据
2. 度量是表示可以用来计算的列,比如学生考试成绩,消费者的交易金额等。在SQL中我们可以认为可以被聚合函数进行计算,比如sum(),avg()的都是度量
3. 维度和度量并不是绝对意义的分割的,他们之间是可以相互转换的。比如我们要统计学生分数的分布情况,这个时候分数就是一个维度列;当我们统计学生的平均分时,这个时候分数就是一个度量列。
4. 维度的基数:即维度列字段的个数。如性别这一维度的基数是2,只有男女;季节这一维度列的基数是4,因为只有春夏秋冬四季。但是如果将学生的学号作为维度列的话,一个学校有1万名学生的话,该维度的基数列为1万。通产基数超过一百万的维度称为超高基数维度,需要引起Cube设计者注意。
事实表,维度表
1. 这是BI中的概念。各种维度加上都做构成一个事实。比如学生的学号与姓名,加上考试成绩构成一个事实
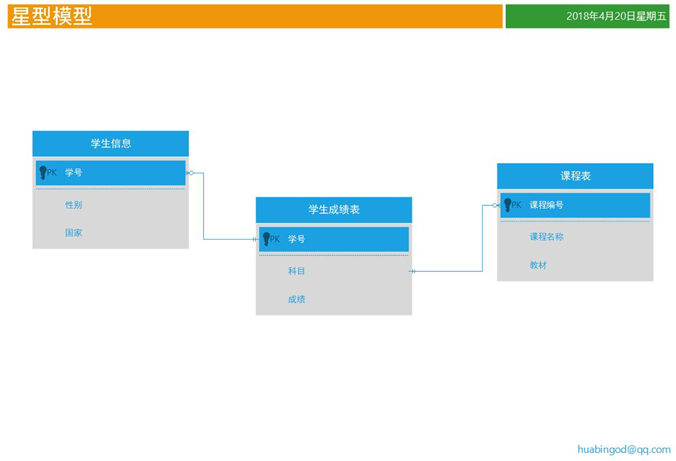
雪花与星型模型
1. 所谓的雪花模型指一个事实表链接多个维度表,且维度之间存在关系,维度表拥有自己的维度表
2. 所谓的星型模型只一个事实表链接多个维度表,维度表之间没有关系
3. Kylin可以处理星型模型,对雪花模型无能为力(或者需要转换成星型模型)
Cube和Cuboid
1. Cube是一个表中选中参与预计算的所有维度的所有基数的组合总称,而Cuboid是其中的一个组合,所有的Cuboid的总体就是所有的维度的所有基数。
2. 如下面的表,假设我们分析的维度列有两个(也就是该cube中有两个维度列,分别为性别国家),那所有的Cuboid是:【男】,【女】,【中国】,【英国】,【美国】,【男,中国】,【女,中国】,【男,英国】,【女,英国】,【男,美国】,【女,美国】。其中【】就是一个Cuboid,所有的可能的集合就是一个Cube(当然在具体分析中可以对Cuboid进行裁剪,以进行优化)
3. 也就说,Kylin的预计算,就是对度量列的统计,然后group by Cube中的所有Cuboid.
4. 可以想象的,如果维度过多或者维度的基数过高,就会导致Kylin在进行计算时,会将数据膨胀到很大,耗费计算和存储资源。因此如何优化Cube的构建将是优化的突破点
关于表和图的角色分析
1. 学生信息表和课程表是维度表,学生成绩表是事实表
2. 学生成绩表中的学号和课程编号通常在SQL中被放入group by中,是维度;而成绩经常被sum,avg是度量
3. 如果仅有三张表,那么三张表构成一个星型模型(这里设计的既不符合RDMS的设计要求);假设在学生信息表的国家并不是国家的名称,而是国家的编码,在另外有一张国家表,专门用来存储国家和国家代码的映射关系。那么学生信息表,学生成绩表,国家表就构成了一个雪花模型。
数据表示例
学生信息表:
|
学号 |
性别 |
国家 |
姓名 |
|
001 |
男 |
中国 |
张三 |
|
002 |
女 |
英国 |
李四 |
|
003 |
男 |
美国 |
王五 |
学生成绩表:
|
学号 |
课程编号 |
成绩 |
|
001 |
1 |
100 |
|
001 |
2 |
99 |
|
002 |
1 |
88 |
|
002 |
2 |
77 |
|
003 |
1 |
66 |
|
004 |
2 |
55 |
课程表
|
课程编号 |
课程名称 |
教材 |
|
1 |
英语 |
怎么也学不会 |
|
2 |
计算机 |
从入门到放弃 |
雪花模型
Kylin系列之二:原理介绍的更多相关文章
- Spring Cloud系列(二) 介绍
Spring Cloud系列(一) 介绍 Spring Cloud是基于Spring Boot实现的微服务架构开发工具.它为微服务架构中涉及的配置管理.服务治理.断路器.智能路由.微代理.控制总线.全 ...
- Git系列教程二 基础介绍
一.存储方式 如果让我们设计一个版本控制系统,最简单的方式就是每做一次更改就生成一个新的文件. 这样的方式太占用空间,所以传统的版本控制系统都是保存一个文件的某个版本的全部内容以及其他版本相对于这个版 ...
- Python零基础学习系列之二--Python介绍及环境搭建
1-1.Python简介: Python是一种解释型.面向对象.动态数据类型的高级程序设计语言.Python由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年.像P ...
- jmeter入门系列文章二 版本号介绍
转载时请标注源自:http://blog.csdn.net/musen518 jmeter版本号公布频率一般为1年,每年会有一个版本号升级 截止2015年底,最新版本号为2.13,最新最全的更新信息一 ...
- 使用腾讯云 GPU 学习深度学习系列之二:Tensorflow 简明原理【转】
转自:https://www.qcloud.com/community/article/598765?fromSource=gwzcw.117333.117333.117333 这是<使用腾讯云 ...
- Storm 系列(二)实时平台介绍
Storm 系列(二)实时平台介绍 本章中的实时平台是指针对大数据进行实时分析的一整套系统,包括数据的收集.处理.存储等.一般而言,大数据有 4 个特点: Volumn(大量). Velocity(高 ...
- 单片机小白学步系列(二十) IO口原理
IO口操作是单片机实践中最基本最重要的一个知识,本篇花了比較长的篇幅介绍IO口的原理. 也是查阅了不少资料,确保内容正确无误,花了非常长时间写的. IO口原理原本须要涉及非常多深入的知识,而这里尽最大 ...
- SpringBoot系列之日志框架介绍及其原理简介
SpringBoot系列之日志框架介绍及其原理简介 1.常用日志框架简介 市面上常用日志框架:JUL.JCL.jboss-logging.logback.log4j.log4j2.slf4j.etc. ...
- faster-rcnn系列原理介绍及概念讲解
faster-rcnn系列原理介绍及概念讲解 faster-rcnn系列原理介绍及概念讲解2 转:作者:马塔 链接:https://www.zhihu.com/question/42205480/an ...
随机推荐
- java1.8版本的HashMap源码剖析
一.摘要 以下分析内容均是基于JDK1.8产生的,同时也和JDK1.7版本的hashmap做了一些比较.在1.7版本中,HashMap的实现是基于数组+链表的形式,而在1.8版本中则引入了红黑树,但其 ...
- c语言最后一次作业
1.当初你是如何做出选择计算机专业的决定的? 我再来到大学之前,通过查询和询问,了解到当前计算机行业就业需求量较高,同时我对计算机的几年过去比较高了,在高中时期就有过在大学学习计算机行业的知识与专业的 ...
- 高级软件工程2017第5次作业—— 团队项目:需求改进&系统设计
Deadline:2017-10-23(周一) 21:00pm 注:以下内容参考 集大作业 1.评分规则: 按时交 - 有分,检查的项目包括后文的四个方面 需求&原型改进 - 20分 系统设计 ...
- 201621123050 《Java程序设计》第13周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图.OneNote或其他)归纳总结多网络相关内容. 2. 为你的系统增加网络功能(购物车.图书馆管理.斗地主等)-分组完成 为了让你的系统可以被多个用户通过网 ...
- AWS EMR上搭建HBase环境
0. 概述 AWS的EMR服务为客户提供的托管 Hadoop 框架可以让您轻松.快 速.经济高效地在多个动态可扩展的 Amazon EC2 实例之间分发和处理 大量数据.您还可以运行其他常用的分发框架 ...
- mysql命令行大全
1.连接Mysql 格式: mysql -h主机地址 -u用户名 -p用户密码1.连接到本机上的MYSQL.首先打开DOS窗口,然后进入目录mysql\bin,再键入命令mysql -u root ...
- New UWP Community Toolkit - AdaptiveGridView
概述 UWP Community Toolkit 中有一个自适应的 GridView 控件 - AdaptiveGridView,本篇我们结合代码详细讲解 AdaptiveGridView 的实现 ...
- HTML事件处理程序
事件处理程序中的代码执行时,有权访问全局作用域中任何代码. //为按钮btn_event添加了两个个事件处理程序,而且该事件会在冒泡阶段触发(最后一个参数是false). var btn_event ...
- Ubuntu Desktop 16.04 LTS 下成功配置Jupyter的两个python内核版本(2.7x,3.5x)
Ubuntu Desktop 16.04 LTS 安装好系统默认就有python两个不同版本(2.7.12和3.5.2) 现在来熟悉一下jupyter的对python这两个不同python版本的内核 ...
- Linux - IDA - 安装 ( 带F5功能 )
Linux - IDA - 安装 ( 带F5功能 ) 0x00 前言 最近在熟悉deepin系统,想着把逆向的一些软件也迁移过去,但像ida,Ollydbg这些工具一般都是在windows下使用,所以 ...