Scrapy定时执行爬取任务与定时关闭任务
当我们利用Python scrapy框架写完脚本后,脚本已经可以稳定的进行数据的爬取,但是每次需要手动的执行,太麻烦,如果能自动运行,在自动关闭那就好了,经过小编研究,完全是可以实现的,今天小编介绍2种方案来解决这个问题
由于scrapy框架本身没有提供这样的功能,所以小编采用了linux 中crontab的方式进行定时任务的爬取
方案一:
编写shell脚本文件cron.sh
#! /bin/bash
export PATH=$PATH:/usr/local/bin
cd /home/python3/scrapydemo/Ak17/AK17/spiders
nohup scrapy crawl novel >> novel.log 2>&1 &
终端执行命令crontab -e,规定crontab要执行的命令和要执行的时间频率,这里我需要每5分钟就执行scrapy crawl novel 这条爬取命令:
# daemon's notion of time and timezones.
#
# Output of the crontab jobs (including errors) is sent through
# email to the user the crontab file belongs to (unless redirected).
#
# For example, you can run a backup of all your user accounts
# at 5 a.m every week with:
# 0 5 * * 1 tar -zcf /var/backups/home.tgz /home/
#
# For more information see the manual pages of crontab(5) and cron(8)
#
# m h dom mon dow command
*/5 * * * * sh /home/python3/scrapydemo/Ak17/cron.sh
* 如果报错No MTA installed, discarding output,可以重定向到/dev/null,这个文件是一个无底洞,无法打开
例如:*/5 * * * * sh /home/python3/scrapydemo/Ak17/cron.sh > /dev/null 2>&1
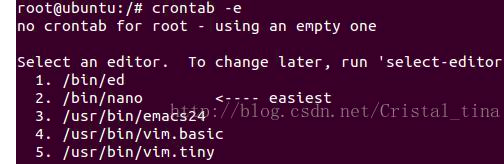
如果输入crontab -e后显示如下,直接随便输入一个数字即可,小编这里输入的2
编辑好后,执行命令打开crontab的日志,默认linux系统是不开启的,将cron.*这一行前的注释打开:
vi /etc/rsyslog.d/50-default.conf

重启系统日志服务
sudo service rsyslog restart
最后就可以使用tail –f /var/log/cron.log查看crontab的日志了
方案二:
和方案一唯一的区别是没有日志的输出信息,直接修改定时任务即可
终端执行命令crontab -e,规定crontab要执行的命令和要执行的时间频率
# daemon's notion of time and timezones.
#
# Output of the crontab jobs (including errors) is sent through
# email to the user the crontab file belongs to (unless redirected).
#
# For example, you can run a backup of all your user accounts
# at 5 a.m every week with:
# 0 5 * * 1 tar -zcf /var/backups/home.tgz /home/
#
# For more information see the manual pages of crontab(5) and cron(8)
#
# m h dom mon dow command
*/5 * * * * cd /home/python3/scrapydemo/Ak17/AK17/spiders && /usr/local/bin/scrapy crawl novel
关闭定时任务:
scrapy的setting中添加一个配置项
CLOSESPIDER_TIMEOUT = 82800 # 23小时后结束爬虫
解释一下
CLOSESPIDER_TIMEOUT
默认值: 0
一个整数值,单位为秒。如果一个spider在指定的秒数后仍在运行, 它将以 closespider_timeout 的原因被自动关闭。 如果值设置为0(或者没有设置),spiders不会因为超时而关闭。
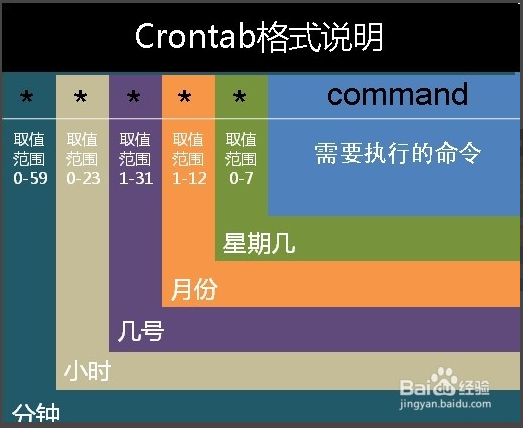
顺便说一下crontab的常见格式:
每分钟执行 */1 * * * *
每小时执行 0 * * * *
每天执行 0 0 * * *
每周执行 0 0 * * 0
每月执行 0 0 1 * *
每年执行 0 0 1 1 *
Scrapy定时执行爬取任务与定时关闭任务的更多相关文章
- scrapy定时执行抓取任务
在ubuntu环境下,使用scrapy定时执行抓取任务,由于scrapy本身没有提供定时执行的功能,所以采用了crontab的方式进行定时执行: 首先编写要执行的命令脚本cron.sh #! /bin ...
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
- 爬虫系列5:scrapy动态页面爬取的另一种思路
前面有篇文章给出了爬取动态页面的一种思路,即应用Selenium+Firefox(参考<scrapy动态页面爬取>).但是selenium需要运行本地浏览器,比较耗时,不太适合大规模网页抓 ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- python 3.6 urllib库实现天气爬取、邮件定时给妹子发送天气
#由于每天早上要和妹子说早安,于是做个定时任务,每天早上自动爬取天气,发送天气问好邮件##涉及模块:#(1)定时任务:windows的定时任务# 配置教程链接:http://b ...
- nutch的定时增量爬取
译文来着: http://wiki.apache.org/nutch/Crawl 介绍(Introduction) 注意:脚本中没有直接使用Nutch的爬去命令(bin/nutch crawl或者是& ...
- scrapy爬虫案例--爬取阳关热线问政平台
阳光热线问政平台:http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1 爬取最新问政帖子的编号.投诉标题.投诉内容以 ...
- Scrapy实战篇(八)之Scrapy对接selenium爬取京东商城商品数据
本篇目标:我们以爬取京东商城商品数据为例,展示Scrapy框架对接selenium爬取京东商城商品数据. 背景: 京东商城页面为js动态加载页面,直接使用request请求,无法得到我们想要的商品数据 ...
- Scrapy实战篇(六)之Scrapy配合Selenium爬取京东信息(上)
在之前的一篇实战之中,我们已经爬取过京东商城的文胸数据,但是前面的那一篇其实是有一个缺陷的,不知道你看出来没有,下面就来详细的说明和解决这个缺陷. 我们在京东搜索页面输入关键字进行搜索的时候,页面的返 ...
随机推荐
- iOS之SQLite使用详解
#pragma mark - 1.引入<sqlite3.h>头文件//添加libsqlite3.0.tbd#import <sqlite3.h>static sqlite3 * ...
- Leetcode 1——twosum
Given an array of integers, return indices of the two numbers such that they add up to a specific ta ...
- Bate敏捷冲刺每日报告--day2
1 团队介绍 团队组成: PM:齐爽爽(258) 小组成员:马帅(248),何健(267),蔡凯峰(285) Git链接:https://github.com/WHUSE2017/C-team 2 ...
- SpringMVC之HandlerMapping的使用
上篇博客在了解SpringMVC的工作流程时留了一些疑问,今天先学习下HandlerMapping,在HandlerMapping中可以通过HandlerExecutionChain getHandl ...
- vue初尝试--组件
github代码同步网址 组件 (Component) 是 Vue.js 最强大的功能之一.组件可以扩展 HTML 元素,封装可重用的代码.在较高层面上,组件是自定义元素,Vue.js 的编译器为它添 ...
- JAVA_SE基础——67.System类
System类对大家都不陌生吧! 以前经常需要打印结果时使用的都是"System.out.println()"语句,这句代码中就使用了System类.System类定义了一些与系统 ...
- Mybatis学习日志
在Mybatis深入学习的一周中,总感觉跟着师傅的视屏讲解什么都能懂,但实际自己操作的时候才发现自己一脸懵逼,不知道从何入手.但还好自己做了点笔记.在此记录一下自己浅度学习Mybatis遇到几个小问题 ...
- io文本加密
文本加密习题 package io; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.Inpu ...
- LeetCode & Q13-Roman to Integer-Easy
Math String Description: Given a roman numeral, convert it to an integer. Input is guaranteed to be ...
- 我的前端故事----来聊聊react-native应用的健康监控
监控什么 今天我们来聊聊如何监控你的应用程序,这里的监控说的不是让我们去监控用户,而是监控应用的健康状态,什么是健康状态呢?对于后端的同学来说,在微服务的架构下,每个子服务是否正常工作.返回的结果是否 ...