A million requests per second with Python
https://medium.freecodecamp.com/million-requests-per-second-with-Python-95c137af319
Is it possible to hit a million requests per second with python? Probably not until recently.
A lot of companies are migrating away from Python and to other programming languages so that they can boost their operation performance and save on server prices, but there’s no need really. Python can be right tool for the job.
The Python community is doing a lot of around performance lately. CPython 3.6 boosted overall interpreter performance with new dictionary implementation. CPython 3.7 is going to be even faster, thanks to the introduction of faster call convention and dictionary lookup caches.
For number crunching tasks you can use PyPy with its just-in-time code compilation. You can also run NumPy’s test suite, which now has improved overall compatibility with C extensions. Later this year PyPy is expected to reach Python 3.5 conformance.
All this great work inspired me to innovate in one of the areas where Python is used extensively: web and micro-service development.
Enter Japronto!
Japronto is a brand new micro-framework tailored for your micro-services needs. Its main goals include being fast, scalable, and lightweight. It lets you do both synchronous and asynchronous programming thanks to asyncio. And it’s shamelessly fast. Even faster than NodeJS and Go.
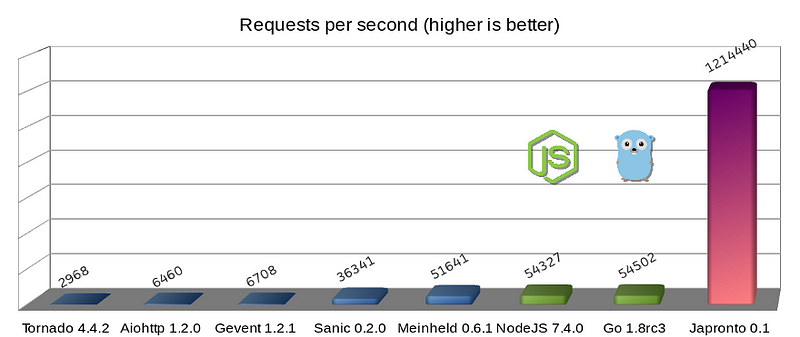
Python micro-frameworks (blue), Dark side of force (green) and Japronto (purple)
Errata: As user @heppu points out, go’s stdlib HTTP server can be 12% faster than this graph shows when written more carefully. Also there’s an awesome fasthttp server for Go that apparently is only 18% slower than Japronto in this particular benchmark. Awesome! For details see https://github.com/squeaky-pl/japronto/pull/12 and https://github.com/squeaky-pl/japronto/pull/14.
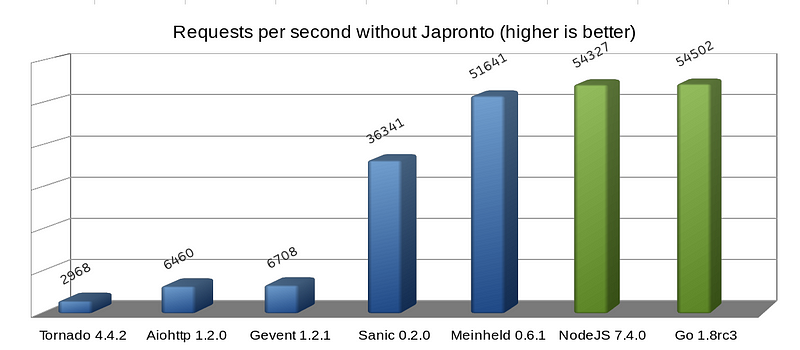
We can also see that Meinheld WSGI server is almost on par with NodeJS and Go. Despite of its inherently blocking design, it is a great performer compared to the preceding four, which are asynchronous Python solutions. So never trust anyone who says that asynchronous systems are always speedier. They are almost always more concurrent, but there’s much more to it than just that.
I performed this micro benchmark using a “Hello world!” application, but it clearly demonstrates server-framework overhead for a number of solutions.
These results were obtained on an AWS c4.2xlarge instance that had 8 VCPUs, launched in São Paulo region with default shared tenancy and HVM virtualization and magnetic storage. The machine was running Ubuntu 16.04.1 LTS (Xenial Xerus) with the Linux 4.4.0–53-generic x86_64 kernel. The OS was reporting Xeon® CPU E5–2666 v3 @ 2.90GHz CPU. I used Python 3.6, which I freshly compiled from its source code.
To be fair, all the contestants (including Go) were running a single-worker process. Servers were load tested using wrk with 1 thread, 100 connections, and 24 simultaneous (pipelined) requests per connection (cumulative parallelism of 2400 requests).
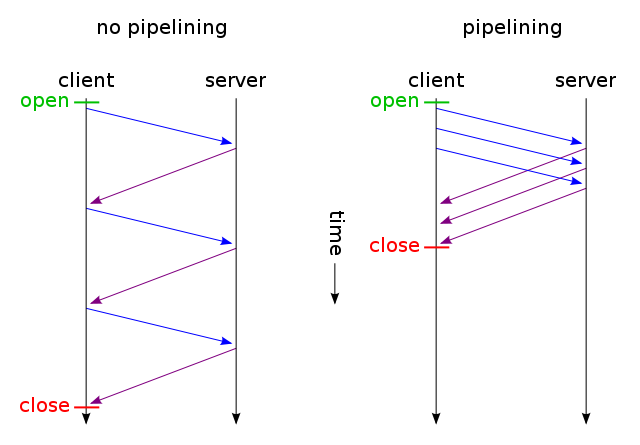
HTTP pipelining (image credit Wikipedia)
HTTP pipelining is crucial here since it’s one of the optimizations that Japronto takes into account when executing requests.
Most of the servers execute requests from pipelining clients in the same fashion they would from non-pipelining clients. They don’t try to optimize it. (In fact Sanic and Meinheld will also silently drop requests from pipelining clients, which is a violation of HTTP 1.1 protocol.)
In simple words, pipelining is a technique in which the client doesn’t need to wait for the response before sending subsequent requests over the same TCP connection. To ensure integrity of the communication, the server sends back several responses in the same order requests are received.
The gory details of optimizations
When many small GET requests are pipelined together by the client, there’s a high probability that they’ll arrive in one TCP packet (thanks to Nagle’s algorithm) on the server side, then be read back by one system call.
Doing a system call and moving data from kernel-space to user-space is a very expensive operation compared to, say, moving memory inside process space. That’s why doing it’s important to perform as few as necessary system calls (but no less).
When Japronto receives data and successfully parses several requests out of it, it tries to execute all the requests as fast as possible, glue responses back in correct order, then write back in one system call. In fact the kernel can aid in the gluing part, thanks to scatter/gather IO system calls, which Japronto doesn’t use yet.
Note that this isn’t always possible, since some of the requests could take too long, and waiting for them would needlessly increase latency.
Take care when you tune heuristics, and consider the cost of system calls and the expected request completion time.

Japronto gives a 1,214,440 RPS median of grouped continuous data, calculated as the 50th percentile, using interpolation.
Besides delaying writes for pipelined clients, there are several other techniques that the code employs.
Japronto is written almost entirely in C. The parser, protocol, connection reaper, router, request, and response objects are written as C extensions.
Japronto tries hard to delay creation of Python counterparts of its internal structures until asked explicitly. For example, a headers dictionary won’t be created until it’s requested in a view. All the token boundaries are already marked before but normalization of header keys, and creation of several str objects is done when they’re accessed for the first time.
Japronto relies on the excellent picohttpparser C library for parsing status line, headers, and a chunked HTTP message body. Picohttpparser directly employs text processing instructions found in modern CPUs with SSE4.2 extensions (almost any 10-year-old x86_64 CPU has it) to quickly match boundaries of HTTP tokens. The I/O is handled by the super awesome uvloop, which itself is a wrapper around libuv. At the lowest level, this is a bridge to epoll system call providing asynchronous notifications on read-write readiness.

Picohttpparser relies on SSE4.2 and CMPESTRI x86_64 intrinsic to do parsing
Python is a garbage collected language, so care needs to be taken when designing high performance systems so as not to needlessly increase pressure on the garbage collector. The internal design of Japronto tries to avoid reference cycles and do as few allocations/deallocations as necessary. It does this by preallocating some objects into so-called arenas. It also tries to reuse Python objects for future requests if they’re no longer referenced instead of throwing them away.
All the allocations are done as multiples of 4KB. Internal structures are carefully laid out so that data used frequently together is close enough in memory, minimizing the possibility of cache misses.
Japronto tries to not copy between buffers unnecessarily, and does many operations in-place. For example, it percent-decodes the path before matching in the router process.
Open source contributors, I could use your help.
I’ve been working on Japronto continuously for past 3 months — often during weekends, as well as normal work days. This was only possible due to me taking a break from my regular programmer job and putting all my effort into this project.
I think it’s time to share the fruit of my labor with the community.
Currently Japronto implements a pretty solid feature set:
- HTTP 1.x implementation with support for chunked uploads
- Full support for HTTP pipelining
- Keep-alive connections with configurable reaper
- Support for synchronous and asynchronous views
- Master-multiworker model based on forking
- Support for code reloading on changes
- Simple routing
I would like to look into Websockets and streaming HTTP responses asynchronously next.
There’s a lot of work to be done in terms of documenting and testing. If you’re interested in helping, please contact me directly on Twitter. Here’s Japronto’s GitHub project repository.
Also, if your company is looking for a Python developer who’s a performance freak and also does DevOps, I’m open to hearing about that. I am going to consider positions worldwide.
Final words
All the techniques that I’ve mentioned here are not really specific to Python. They could be probably employed in other languages like Ruby, JavaScript or even PHP. I’d be interested in doing such work, too, but this sadly will not happen unless somebody can fund it.
I’d like to thank Python community for their continuous investment in performance engineering. Namely Victor Stinner @VictorStinner, INADA Naoki @methane and Yury Selivanov @1st1 and entire PyPy team.
For the love of Python.
A million requests per second with Python的更多相关文章
- (转)Making 1 million requests with python-aiohttp
转自:https://pawelmhm.github.io/asyncio/python/aiohttp/2016/04/22/asyncio-aiohttp.html Making 1 millio ...
- worker pool Handling 1 Million Requests per Minute with Golang
小结: 1. 我们决定使用 Go 通道的一种常用模式构建一个两层的通道系统,一个通道用作任务队列,另一个来控制处理任务时的并发量. 这个办法是想以一种可持续的速率.并发地上传数据至 S3 存储,这样既 ...
- python requests模块使用
python的网络编程能力十分强大,其中python中的requests库宣言:HTTP for Humans (给人用的 HTTP 库) 在网络编程中,最基本的任务包含: 发送请求 登录 获取数据 ...
- Python Requests模块讲解4
高级用法 会话对象 请求与响应对象 Prepared Requests SSL证书验证 响应体内容工作流 保持活动状态(持久连接) 流式上传 块编码请求 POST Multiple Multipart ...
- Python requests 安装与开发
Requests 是用Python语言编写HTTP客户端库,跟urllib.urllib2类似,基于 urllib,但比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求, ...
- Python+Requests接口测试教程(2):
开讲前,告诉大家requests有他自己的官方文档:http://cn.python-requests.org/zh_CN/latest/ 2.1 发get请求 前言requests模块,也就是老污龟 ...
- python requests库学习笔记(上)
尊重博客园原创精神,请勿转载! requests库官方使用手册地址:http://www.python-requests.org/en/master/:中文使用手册地址:http://cn.pytho ...
- python爬虫 - python requests网络请求简洁之道
http://blog.csdn.net/pipisorry/article/details/48086195 requests简介 requests是一个很实用的Python HTTP客户端库,编写 ...
- [python爬虫]Requests-BeautifulSoup-Re库方案--Requests库介绍
[根据北京理工大学嵩天老师“Python网络爬虫与信息提取”慕课课程编写 文章中部分图片来自老师PPT 慕课链接:https://www.icourse163.org/learn/BIT-10018 ...
随机推荐
- 程序员的软实力武器-smart原则
smart对于程序员来说不是仅仅意味一个法则: 面对需求和提出需求时候,smart原则可以极大的提高效率 目标管理是使管理者的工作由被动变为主动的一个很好的管理手段,实施目标管理不仅是为了利于员工更加 ...
- 深入认识AsyncTask
1.概述 在android开发中是采用单线程模型,主线程通常称为UI线程,由于UI线程的操作不是线程安全的,因此android规定有关更新界面的操作必须在主线程中进行,其他线程直接报错. 如果我们把所 ...
- 【一天一道LeetCode】#32. Longest Valid Parentheses
一天一道LeetCode系列 (一)题目 Given a string containing just the characters '(' and ')', find the length of t ...
- Leetcode_34_Search for a Range
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/44021767 Given a sorted array o ...
- MT6575 3G切换2G
因为了节省成本,需要从现在的3G方案切换置2G方案,做的修改,做个笔记. 一: 将MTK给过来的补丁编译出如下文件. 二:在mediatek/custom/common/modem/ 路径下增加一个 ...
- AngularJS进阶(二)AngularJS路由问题解决
AngularJS路由问题解决 遇到了一个棘手的问题:点击优惠详情时总是跳转到药店详情页面中去.再加一层地址解决了,但是后来发现问题还是来了: Could not resolve 'yhDtlMain ...
- C++中的虚函数表是什么时期建立的?
虚函数表是在什么时期建立的? 最近参加阿里巴巴公司的内推,面试官问了“虚函数表是在什么时期建立的?”.因为以前对虚函数表的理解不够多,所以就根据程序构建(Build)的四个过程(预编译.编译.汇编和链 ...
- 三消游戏FSM状态机设计图
三消游戏FSM状态机设计图 1) 设计FSM图 2) smc配置文件 ///////////////////////////////////////////////////////////////// ...
- LeetCode之“动态规划”:Word Break && Word Break II
1. Word Break 题目链接 题目要求: Given a string s and a dictionary of words dict, determine if s can be seg ...
- Hibernate之初体验
在开始学Hibernate之前,一直就有人说:Hibernate并不难,无非是对JDBC进一步封装.一句不难,难道是真的不难还是眼高手低? 如果只是停留在使用的层面上,我相信什么技术都不难,看看别人怎 ...