SQL 中如何删除重复(每列数据都重复)的记录,只保留一行?
如果数据表没有做好约束,那么数据库中难免会遇到数据重复的情况。今天就遇到这么个看起来简单却又费神的问题---如何去重。
------期间感谢微信公众号“有关SQL”的博主大牛提供的指导和建议。大家可以关注下他的公众号。
借鉴下大神的思路,去除重复的核心思想就两个:
1:找到重复记录,删除他们;
2:找到非重复记录,保留他们
两个思想,操作方式不同,取决于重复记录与非重复记录的行数倾斜度。
情况一:数据表本身数据量不大的情况,如何去除重复
一:创建测试表
CREATE TABLE test(id INT ,NAME VARCHAR(20))
二:插入数据
INSERT INTO test VALUES (1,'001')
INSERT INTO test VALUES (2,'002')
INSERT INTO test VALUES (3,'003')
INSERT INTO test VALUES (3,'003')
INSERT INTO test VALUES (3,'003')
INSERT INTO test VALUES (3,'003')
刚开始用SQL的开窗函数对数据行进行排序
SELECT t.id,t.NAME,row_number() OVER (partition by t.id ORDER BY t.id ) AS NUM FROM test AS t
效果如下:
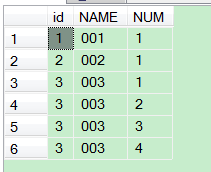
然后发现其实并没有什么用,跟源表无法匹配关联起来,准确的删除4行重复记录里的3行记录。想来想去,唯有强大的游标才能帮到我,因为游标是对数据逐行操作的!!!
想到这点后,咋们说做就做:
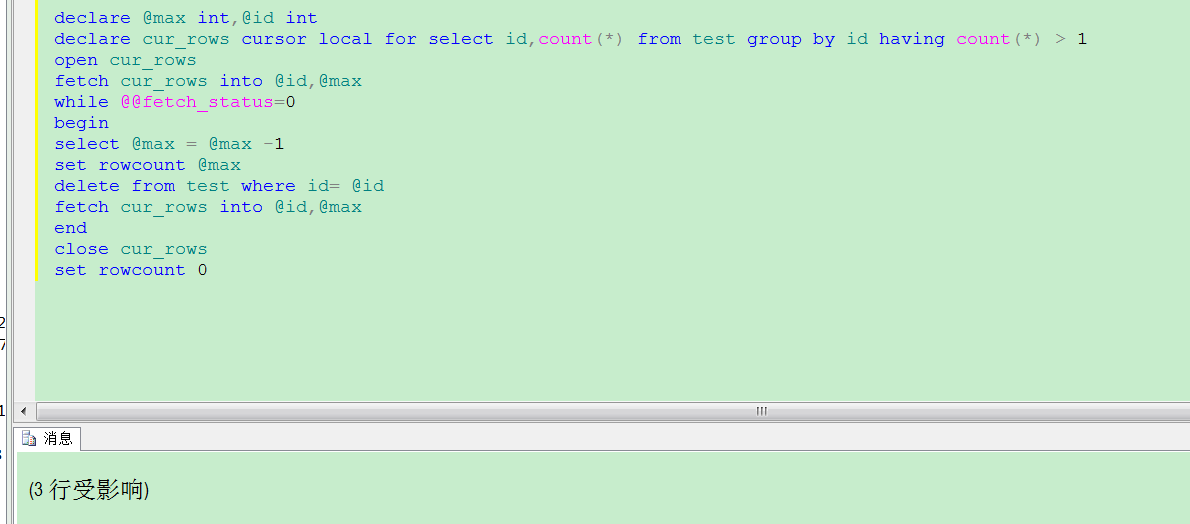
三:游标代码
declare @max int,@id int
declare cur_rows cursor local for select id,count(*) from test group by id having count(*) > 1
open cur_rows
fetch cur_rows into @id,@max
while @@fetch_status=0
begin
select @max = @max -1
set rowcount @max
delete from test where id= @id
fetch cur_rows into @id,@max
end
close cur_rows
set rowcount 0
最后效果:
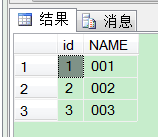
当然,如果只有悉数的几种重复数据行,你也可以这样玩
CREATE TABLE #table1 (id INT,NAME VARCHAR(20),COT1 INT,DEL int )--创建临时表 INSERT INTO #table1--将重复行的信息以及重复行数存放到临时表
SELECT DISTINCT
t.id,t.NAME,t.COT1,t.COT1-1
FROM
(SELECT id,NAME,COUNT(*)OVER (PARTITION BY id) AS COT1 FROM test) AS t
WHERE t.COT1>1
效果如图:

随后执行删除语句:
DELETE TOP (4) a FROM test AS a WHERE a.id=3
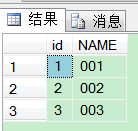
也可达到效果。
情况二:数据表数据量超大,如何去除重复
如果原表重复记录太多,删掉他们肯定费事费时。
delete 操作既要寻址,还要写 Log ,造成锁表时间太长,影响并发。
那么将这些非重复记录先取出来,放入新表,整理完毕后,丢弃原表,重命名新表为原表名即可;
如果非重复记录很多,将他们取出来就又要花很长时间了,设想 1 亿的数据量导出来,不现实了吧。那么只有保留他们,而将重复记录删掉即可。
这里假设数据表数据量很大,已经达到千万级别甚至过亿数量级别情况下的做法(将重复数据取出,整理后导回源表):
1:将重复数据取出
SELECT
DISTINCT id,NAME
INTO #TEMP
FROM
(
SELECT
id,NAME,
ROW_NUMBER()OVER(PARTITION BY id ORDER BY NAME ASC) AS RNK
FROM Test WITH(NOLOCK)
) TMP
WHERE RNK>1
2:删除源表中所有重复记录(暂时不保留)
WHILE (EXISTS(SELECT TOP 1 1 FROM Test ts INNER JOIN #TEMP TP ON TP.id = ts.id ))
BEGIN
DELETE TOP (10000) Test
FROM Test
INNER JOIN #TEMP TP ON Test.id = TP.id
END
3:将临时表中存储的备份数据,插回源表(单行数据)
INSERT INTO Test(id,NAME)
最后彻底删除临时中间表
DROP TABLE #TEMP
其中需要注意的是:
a:具体操作中尽量使用实体表,这里中间表只是方便演示;
b:使用while和delete top 的目的是为了保证一个事务足够小,不至于日志爆表;
SQL 中如何删除重复(每列数据都重复)的记录,只保留一行?的更多相关文章
- SQL中删除重复的行(重复数据),只保留一行 转
方法一:使用在T-SQL的编程中 分配一个列号码,以COL1,COL2组合来分区排序,删除DATABASE重复的行(重复数据),只保留一行 // COL1,COL2是数据库DATABASE的栏位 de ...
- SQL中批量删除被注入的恶意代码的方法
下文将为您介绍SQL中批量删除被注入的恶意代码的方法,供您参考,如果您也遇到了这样的问题,不妨一看,相信对您会有所帮助. 1,如果你的数据表很少的话,那么写几条简单的sql就搞定了 对于表中的nvch ...
- 如何在EXCEL中找出第一列中不包含的第二列数据
1.找出第一列中不包含的第二列数据:=IFERROR(VLOOKUP(A:A,B:B,1,0),"无") 2.A列相同,B列相加:=SUMIF(G:G,G1,J:J)
- mysql 去除重复 Select中DISTINCT关键字的用法 在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供 有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值。其原因是 distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰了很久,用distinct不能解决的话,
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供 有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记 ...
- MSSQL sql server 2005/2008 row_number()函数应用之–删除表中重复记录,只保留一条不重复数据
转自:http://www.maomao365.com/?p=4942 下文主要讲述:重复数据只获取一条的方法 row_number函数在数据库中的功能是为每一行 按照一定的规则生成一个编号,我们常常 ...
- 【转】SQL删除重复记录,只保留其中一条
SQL:删除重复数据,只保留一条用SQL语句,删除掉重复项只保留一条在几千条记录里,存在着些相同的记录,如何能用SQL语句,删除掉重复的呢 1.查找表中多余的重复记录,重复记录是根据单个字段(peop ...
- SQL删除重复的记录(只保留一条)
首先新建表: --创建示例表 CREATE TABLE t ( id ,) PRIMARY KEY, a ), b ) ) --插入数据 INSERT INTO t SELECT 'aa','bb' ...
- SQL中一次插入多条数据
SQL中insert一次可以插入一条数据,我们有三种方法可以一次性插入多条数据. 1. 语法:select 字段列表 into 新表 from 源表 注意事项:此种方法新表是系统自动创建,语句执行前不 ...
- SQL SERVER 实现分组合并实现列数据拼接
需求场景: SQL SERVER 中组织的数据结构是一个层级关系,现在需要抓出每个组织节点以上的全部组织信息,数据示例如下: ADOrg_ID--------------ParentID------- ...
随机推荐
- VueJs(8)---组件(注册组件)
组件(注册组件) 一.介绍 组件系统是Vue.js其中一个重要的概念,它提供了一种抽象,让我们可以使用独立可复用的小组件来构建大型应用,任意类型的应用界面都可以抽象为一个组件树 那么什么是组件呢? 组 ...
- contentType,charset和pageEncoding的区别
简单点总结就是jsp页面头上这样写 <%@ page contentType="text/html;charset=GBK" %> 页面用GBK编码 pageEnco ...
- Oracle的网络监听配置
listener.ora.tnsnames.ora和sqlnet.ora这3个文件是关系oracle网络配置的3个主要文件,都是放在$ORACLE_HOME\network\admin目录下.其中li ...
- DIV与SPAN之间有什么区别
DIV与SPAN之间有什么区别 DIV 和 SPAN 元素最大的特点是默认都没有对元素内的对象进行任何格式化渲染.主要用于应用样式表(共同点). 两者最明显的区别在于DIV是块元素,而SPAN是行内元 ...
- Oracle数据库date类型与Java中Date的联系与转化
以下是对Java中的日期对象与Oracle中的日期之间的区别与联系做点说明,以期对大家有所帮助.new Date():分配 Date 对象并初始化此对象,以表示分配它的时间(精确到毫秒),就是系统当前 ...
- jvm性能优化及内存分区
jvm性能优化及内存分区 2012-09-17 15:51:37 分类: Java Some of the default values for Sun JVMs are listed below. ...
- The note of Developing Innovative Ideas for New Companies Course
This course is free on the Coursera Site,But it only has English version Threee pieces of the course ...
- Servlet总结二(文件路径)
Servlet总结二(文件路径) 前言 前面我们说过ServletContext表示的是web容器中的上下文,下面我们也是用到ServletContext中的方法读取文件 读取WebRoot文件下的文 ...
- java之jsp实现动态网页
动态页面,说白了,就是根据一定的信息(条件)去改变呈现给用户的内容. 而这里所提到的一定的信息,通常就是指,在一个表单中用户所输入的信息. 先来看一个我们常见的用户登录界面吧. 在这里我们可以看到一共 ...
- AUTOSAR - 标准文档下载
官网 https://www.autosar.org/ 文档分类 按功能分 按类型分 CLASSIC PLATFORM The AUTOSAR Classic Platform architectur ...