NLP︱词向量经验总结(功能作用、高维可视化、R语言实现、大规模语料、延伸拓展)
R语言由于效率问题,实现自然语言处理的分析会受到一定的影响,如何提高效率以及提升词向量的精度是在当前软件环境下,比较需要解决的问题。
笔者认为还存在的问题有:
1、如何在R语言环境下,大规模语料提高运行效率?
2、如何提高词向量的精度,或者说如何衡量词向量优劣程度?
3、词向量的功能性作用还有哪些值得开发?
4、关于语义中的歧义问题如何消除?
5、词向量从”词“往”短语“的跨越?
转载请注明出处以及作者(Matt),欢迎喜欢自然语言处理一起讨论~
————————————————————————————————————————————————
一、大规模语料提高运行效率
从训练参数、优化训练速度入手。
1、训练参数
训练参数的选择是提高效率的关键之处,一些经验参数训练的经验(一部分来源小桥流水博客):
- window在5~8,我用的8,感觉还不错,CBOW一般在5,SKIP在10左右比较适合;
- 其他的可以参考:
· 架构:skip-gram(慢、对罕见字有利)vs CBOW(快)
· 训练算法:分层softmax(对罕见字有利)vs 负采样(对常见词和低纬向量有利)
· 欠采样频繁词:可以提高结果的准确性和速度(适用范围1e-3到1e-5)
· 文本(window)大小:skip-gram通常在10附近,CBOW通常在5附近
词嵌入的质量也非常依赖于上下文窗口大小的选择。通常大的上下文窗口学到的词嵌入更反映主题信息,而小的上下文窗口学到的词嵌入更反映词的功能和上下文语义信息。
1、维数,一般来说,维数越多越好(300维比较优秀),当然也有例外;
2、训练数据集大小与质量。训练数据集越大越好,覆盖面广,质量也要尽量好。
3、参数设置,一般如windows,iter、架构选择比较相关。
2、优化训练速度
(一部分来源小桥流水博客)
选择cbow模型,根据经验cbow模型比skip-gram模型快很多,并且效果并不比skip-gram差,感觉还好一点;
线程数设置成跟cpu核的个数一致;
迭代次数5次差不多就已经可以了;
3、使用Glove训练词向量(text2vec包)
参考博客:text2vec(参考博客:重磅︱R+NLP:text2vec包——New 文本分析生态系统 No.1(一,简介))
————————————————————————————————————————————————
二、词向量表示精度
不同的词向量表达方式也有着不同的优劣势,
1、NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
2、NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
3、NLP︱高级词向量表达(三)——WordRank(简述)
现在比较多见的词向量表示方式:GloVe、fasttext、wordRank、tfidf-BOW、word2vec
根据Ranking算法得到的wordRank,与 word2vec、fastText三者对比

相似词的寻找方面极佳,词类比方面不同数据集有不同精度。

不过,上述都是实验数据,从实际效果来看,TFIDF-BOW的效果,在很多情况下比这些高阶词向量表示的方式还要好,而且操作简单,值得推广!
——————————————————————————————————————————————————————
三、词向量的功能、作用
1、词向量的可加性
词向量有一个潜力非常大的性质,就是向量之间的可加性,比如两个案例:
Vector(巴黎)-Vector(法国)+Vector(意大利)≈Vector(罗马)
Vector(king)-Vector(man)+Vector(woman)≈Vector(queen)
大致的流程就是king的woman约等于queen,当然为什么要减去man,这里man会干扰king词,所以减去。
差即是投影,就是一个单词在不同上下文中的相对出现。平均两个向量更好,而不是取其总和。
2、消除歧义
上面king-man就是消除歧义的一种方式,这里要用到线性代数的方式,king-man之后就把man这层意思消除掉了。
不过,得先大规模识别歧义词,有待后续研究。
也许你寄希望于一个词向量能捕获所有的语义信息(例如run即是动车也是名词),但是什么样的词向量都不能很好地进行凸显。
这篇论文有一些利用词向量的办法:Improving Word Representations Via Global Context And Multiple Word Prototypes(Huang et al. 2012)
解决思路:对词窗口进行聚类,并对每个单词词保留聚类标签,例如bank1, bank2等
来源博客:NLP︱Glove词向量表达(理论、相关测评结果、R&python实现提及)
3、词聚类
通过聚类,可以去挖掘一些关于某词的派生词;或者寻找相同主题时,可以使用。
4、词向量的短语组合word2phrase
通过词向量构造一些短语组合,要分成两步来探索:
(1)词语如何链接起来?(参考论文)
(2)链接起来,用什么方法来记录组合短语?——平均数
比如”中国河“要变成一个专用短语,那么可以用”中国“+”河“向量的平均数来表示,然后以此词向量来找一些近邻词。
5、sense2vec
利用spacy把句子打散变成一些实体短语(名词短语提取),然后利用word2vec变成sense向量,这样的向量就可以用来求近似。譬如输入nlp,出现的是ml,cv。

关于spacy这个python模块的介绍,可以看自然语言处理工具包spaCy介绍
关于Sense2vec可以参考博客:https://explosion.ai/blog/sense2vec-with-spacy
sense2vec的demo网站
6、近义词属性
词向量通过求近似,可以获得很好的一个性质,除了可加性,就是近似性。可以将附近的近义词进行聚合,当然词向量的质量取决于训练语料的好坏。同时,近义词之中,反义词是否能够识别出来,也还是一个值得研究的话题。
7、词的类比和线性空间
如果我们想要进行单词比较(由a得到b,是因为由A得到B),可以认为对于每个词w,我们有条件概率比的等式
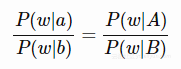
以下就是一个案例:
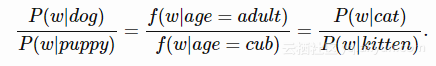
类比是可以找到单词之间对等关系。条件概率比的等式如何转换为单词向量?
我们可以使用类比来表示单词意思(如用向量改变性别),语法(如改变时态)或其他类比(如城市与其邮政编码)。 似乎类比不仅是单方面的技巧 - 我们可能可以一直使用它们来考虑问题,详见:
George Lakoff, Mark Johnson, Metaphors We Live By (1980)
8、高维可视化
一些工具可以实现,譬如Embedding Projector
我们可以load自己的数据上去。官网在可视化高维数据的工具 - 谷歌研究博客

——————————————————————————————————————————————————————
R语言中Word2vec的包有哪些?
R语言中的词向量的包还是比较少的,而且大多数的应用都还不够完善,笔者之前发现有李舰老师写的tm.word2vec包
重磅︱文本挖掘深度学习之word2vec的R语言实现
tm.word2vec包里面的内容太少了,只有一个调用函数比较有效,于是李舰老师又在github上自己写了一个word2vec的函数,但是这个函数调用起来还不是特别方便。
于是国外有一神人,在李舰老师基础上,借鉴李舰老师word2vec函数,开发了自己的包,wordVectors包(1000W单词,4线程,20min左右),这个包相当优秀,不仅全部集成了李舰老师函数的优势(可以多线程操作、自定义维度、自定义模型),还解决了如何读取输出文件、消除歧义、词云图、词相似性等问题。
近日发现了其他两个:一个是text2vec,一个是rword2vec。其中text2vec是现在主要的研究方向:
重磅︱R+NLP:text2vec包简介(GloVe词向量、LDA主题模型、各类距离计算等)
——————————————————————————————————————————————————————
延伸一:大规模语料训练方式
在大量语料下,进行训练R语言效率超级低,而python相对较快。
一般来说用python的gensim和spark的mlib比较好。
但是笔者在使用过程中出现的情况是:
python的gensim好像只有cbow版本,
R语言,word2vec和glove好像都不能输出txt格式,只有bin文件。
同时大规模语料下,fasttext支持ngram向量化,用来搞文本分类还是很棒的。
NLP︱词向量经验总结(功能作用、高维可视化、R语言实现、大规模语料、延伸拓展)的更多相关文章
- Deep Learning In NLP 神经网络与词向量
0. 词向量是什么 自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化. NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representati ...
- 第一节——词向量与ELmo(转)
最近在家听贪心学院的NLP直播课.都是比较基础的内容.放到博客上作为NLP 课程的简单的梳理. 本节课程主要讲解的是词向量和Elmo.核心是Elmo,词向量是基础知识点. Elmo 是2018年提出的 ...
- NLP教程(2) | GloVe及词向量的训练与评估
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,不过这个项目其实是有两部分组成的,一部分是这篇文章介绍的 fastText 文本分类(paper: ...
- NLP之词向量
1.对词用独热编码进行表示的缺点 向量的维度会随着句子中词的类型的增大而增大,最后可能会造成维度灾难2.任意两个词之间都是孤立的,仅仅将词符号化,不包含任何语义信息,根本无法表示出在语义层面上词与词之 ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- NLP︱高级词向量表达(三)——WordRank(简述)
如果说FastText的词向量在表达句子时候很在行的话,GloVe在多义词方面表现出色,那么wordRank在相似词寻找方面表现地不错. 其是通过Robust Ranking来进行词向量定义. 相关p ...
随机推荐
- java基础(六) switch语句的深入解析
引言 switch 语句是非常的基础的知识,掌握起来也不难掌握,语法比较简单.但大部分人基本是知其然,不知其所以然.譬如 早期JDK只允许switch的表达式的值 int及int类型以下的基本类型 ...
- Tensorflow简单CNN实现
觉得有用的话,欢迎一起讨论相互学习~Follow Me 少说废话多写代码~ """转换图像数据格式时需要将它们的颜色空间变为灰度空间,将图像尺寸修改为同一尺寸,并将标签依 ...
- 填坑:在 SegmentFault 开发单页应用之图片引用的问题探索
前言 前段时间,SegmentFault 低调上线了 技术号 模块,方便用户对数据进行集中管理.在开发过程中,第一次引入了 MV* 框架. SF 的基本架构还是后端路由,这也使得页面频繁地整体请求,体 ...
- HBase 数据库检索性能优化策略--转
https://www.ibm.com/developerworks/cn/java/j-lo-HBase/index.html HBase 数据表介绍 HBase 数据库是一个基于分布式的.面向列的 ...
- dubbo中Listener的实现
这里继续dubbo的源码旅程,在过程中学习它的设计和技巧,看优秀的代码,我想对我们日程编码必然有帮助的.而那些开源的代码正是千锤百炼的东西,希望和各位共勉. 拿ProtocolListenerWrap ...
- 《Thinking in Java》学习笔记(五)
1. Java异常补充 a.使用try/catch捕获了异常之后,catch之后的代码是会正常运行的,认为即使进行了异常捕获,出现了异常就不往下执行,这是很多新手会犯的错误. public class ...
- [Lucas定理]【学习笔记】
Lucas定理 [原文]2017-02-14 [update]2017-03-28 Lucas定理 计算组合数取模,适用于n很大p较小的时候,可以将计算简化到小于p $ \binom{n}{m} \m ...
- CodeChef Cards, bags and coins [DP 泛型背包]
https://www.codechef.com/problems/ANUCBC n个数字,选出其一个子集.求有多少子集满足其中数字之和是m的倍数.n $\le$ 100000,m $\le$ 100 ...
- java实现二叉树的前中后遍历(递归和非递归)
这里使用下图的二叉树作为例子: 首先建立树这个类: public class Node { private int data; private Node leftNode; private Node ...
- python requests库学习笔记(下)
1.请求异常处理 请求异常类型: 请求超时处理(timeout): 实现代码: import requestsfrom requests import exceptions #引入exc ...