Spark core 总结
Spark
RDD五大特性
1、RDD由一组partition组成
2、每一个分区由一个task来处理
3、RDD之间有一些列依赖关系
4、分区类算子必须作用在kv格式得RDD上
5、spark为task执行提供了最佳计算位置,尽量将task发送到数据所在节点执行
spark 快的原因
1、spark 尽量将数据放在内存
spark容易出现OOM
2、粗粒度资源申请
在应用程序启动的时候就会申请所有资源
3、DAG有向无环图
优化转换过程
Driver
spark 程序的主程序
1、负责申请资源
new SparkContext
2、负责任务调度
发送task到Excutor中执行
Excutor
spark应用程序执行器
standalone
worker所在节点启动
yarn
NodeManager所在节点启动
执行task任务,向Driver汇报task执行情况
环境搭建
local
本地测试
需要本地安装hadoop
standalone
使用spark自带资源管理框架
Driver向Master申请资源
节点组成
master
管理资源和分配资源
存在单点问题
client
在本地打印运行日志
一般用于上线前测试
Driver在本地(提交任务的节点)启动
Driver即负责资源申请也负责任务调度
cluster
日志不再本地打印
Driver在集群中启动
随便选择一个Worker中启动Driver
一般用于上线运行
yarn
使用hadoop的yarn作为资源管理框架
提交任务 Driver去ResourceManasger中申请资源
通过实现applicationMaster接口往yarn里面提交任务
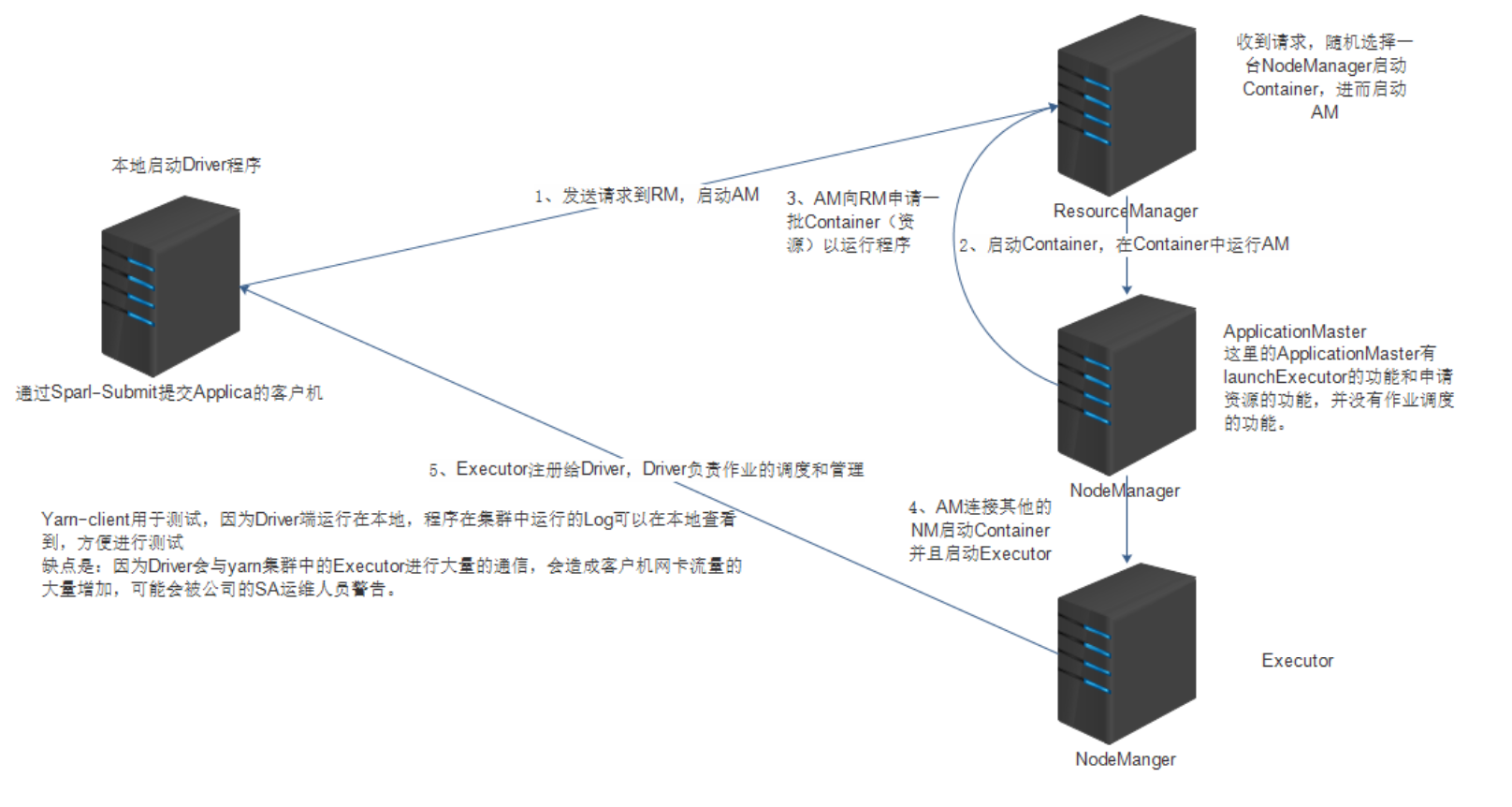
yarn-client
在本地打印运行日志
一般用于上线前测试
Driver在本地(提交任务的节点)启动
Driver只负责任务调度
启动ApplicationMaster 为spark应用程序申请资源
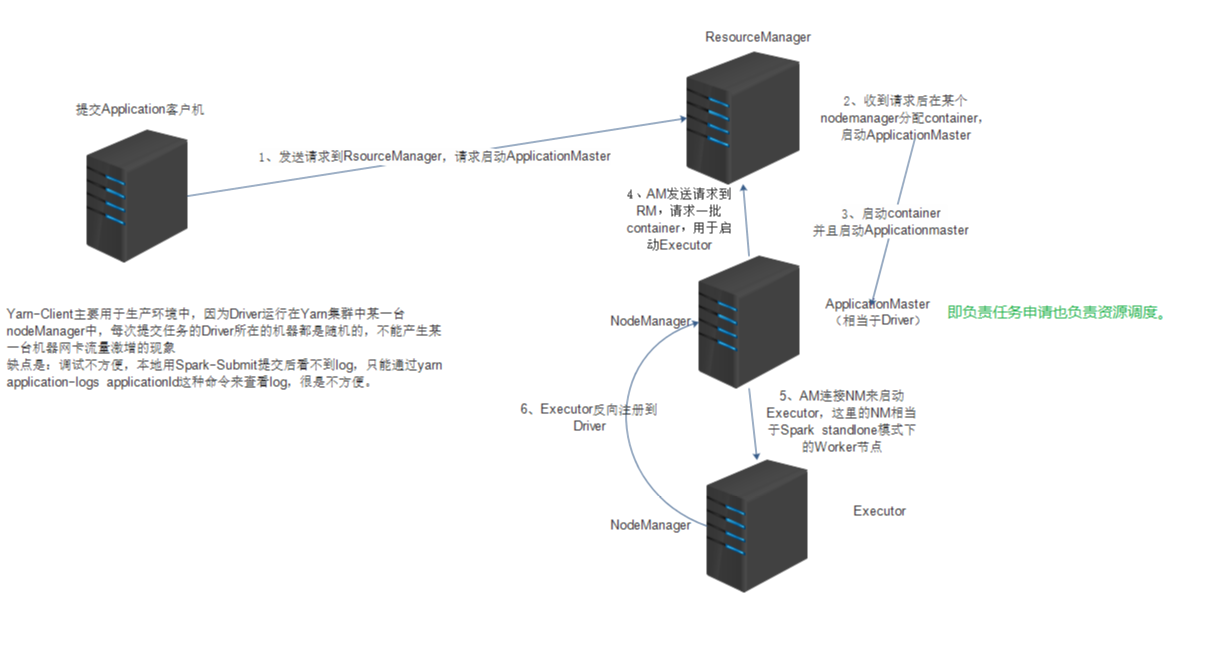
yarn-cluster
日志不再本地打印
一般用于上线运行
Driver(ApplicationMaster)在集群启动
Driver即负责资源申请也负责任务调度
常用算子
transformations算子
map
传入一个对象返回一个对象
flatMap
Filter
返回true保留数据,返回false过滤数据
groupByKey,groupBy
reduceBykey
reduceByKey在map端进行预聚合
union
join
sample
sortBy, sortByKey
rePartition ,partitionBy(自定义分区器)
重新分区,会产生shuffle
mapValues
action算子
foreach
reduce
在map预聚合
save
collect collectAsMap
分区
1、第一个RDD分区数有block数量决定(和mr一样), inputformat
2、后续rdd分区数量
1、默认数去数量等于前一个rdd分区数量
2、在使用shuffle类算子得时候可以执行分区数量
缓存
1、RDD默认不保存数据 2,懒执行
cache
是一个转换算子,不会触发job,需要接收
将数据放Excutor内存中, persist(StorageLevel.MEMORY_ONLY)
persist
可以指定缓存级别
1、是否放内存
2、是否放磁盘
3、是否放堆外内存
4、是否序列化
压缩
1、好处:数据量变小,占用空间更小
2、缺点:序列化和反序列化需要浪费cpu执行时间
5、副本数
选择缓存级别
1、内存充足
MEMORY_ONLY
2、内存不是很多
MEMORY_AND_DISK_SER
尽量将数据压缩之后i放内存
3、内存不足
DISK_ONLY
既然已经放磁盘了,就不必要压缩了
checkpoint
1、将RDD得数据写入hdfs
2,checkpoing会切断RDD依赖关系
3、从最后一个RDD向前回溯,对checkpoint的RDD进行标记,另启动一个job重新计算rdd的数据,并rdd数据写入hdfs(也就是遇到actions算子后启动一个job进行回溯,遇到checkpoint再次启动一个job)
优化:在checkpoint之前先进行cache(避免重读计算)

pagerank
网页排名
计算过程
1、每个网页一个初始值
2、通过不断迭代计算新的pr值
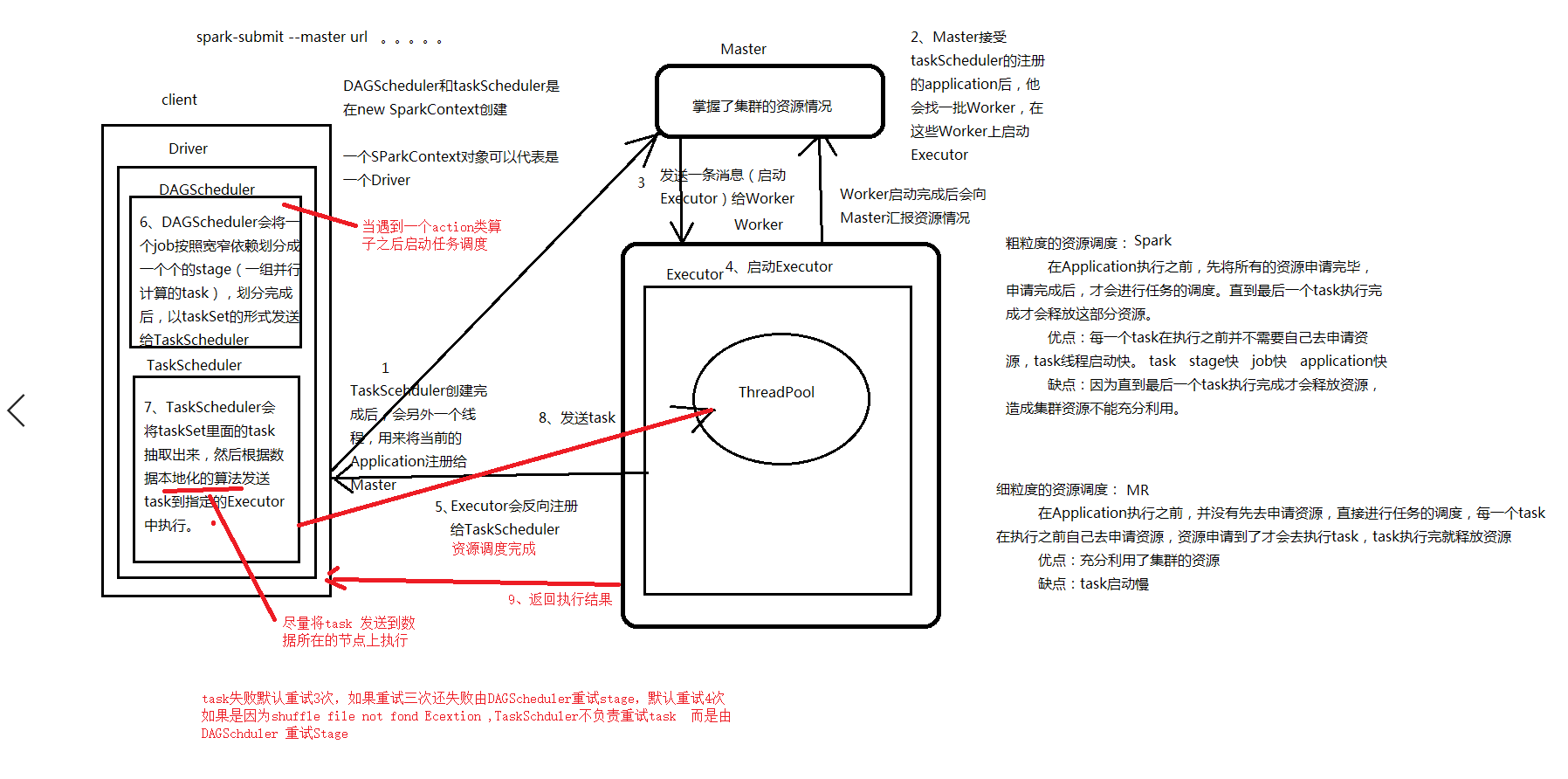
资源调度和任务调度
资源调度
1、细粒度资源调度
MapReduce
每一个task都需要单独申请资源
task启动速度较慢
资源充分利用
2、粗粒度资源调度
spark
在应用程序启动的时候就会将所有需要的资源全部申请下来,后面task执行变快
资源浪费(资源没有充分的利用,在执行的过程中无法进行释放,只有当作业全部进行完毕后才释放)
3、spark资源调度流程 yarn-cluster
1、通过spark-submit提交任务
2、在本地启动Driver val sc = new SparkContext(conf)
3、Driver发请求给RM 启动AM
4、RM分配资源启动AM
5、AM向RM申请资源启动Excutor
6、AM分配资源启动Excutor
7、Excutor反向注册给Driver
8、开始任务调度(action算子触发)
任务调度
1、当遇到一个action算子,启动job,开始任务调度
2、构建DAG有向无环图
3、DAGScheduler 根据宽窄依赖切分Stage (stage是一个可以并行计算的task)
4、DAGScheduler 将stage以taskSet的形式发送给TaskScheduler
5、TaskScheduler 根据本地化算法将task发送到数据所在节点去执行
6、TaskScheduler收集tasK执行情况
如果task失败TaskScheduler默认重试3次
如果重试3次之后还失败,由DAGScheduler重试stage 默认重试4次
如果是因为shuffle过程中拉去文件失败发生的异常,TaskScheduler不负责重试task,而是由DAGScheduler重试上一个stage
TaskScheduler 推测执行
如果有一个task执行很慢,TaskScheduler会在启动一个task去竞争,谁先执行完,以谁的为准
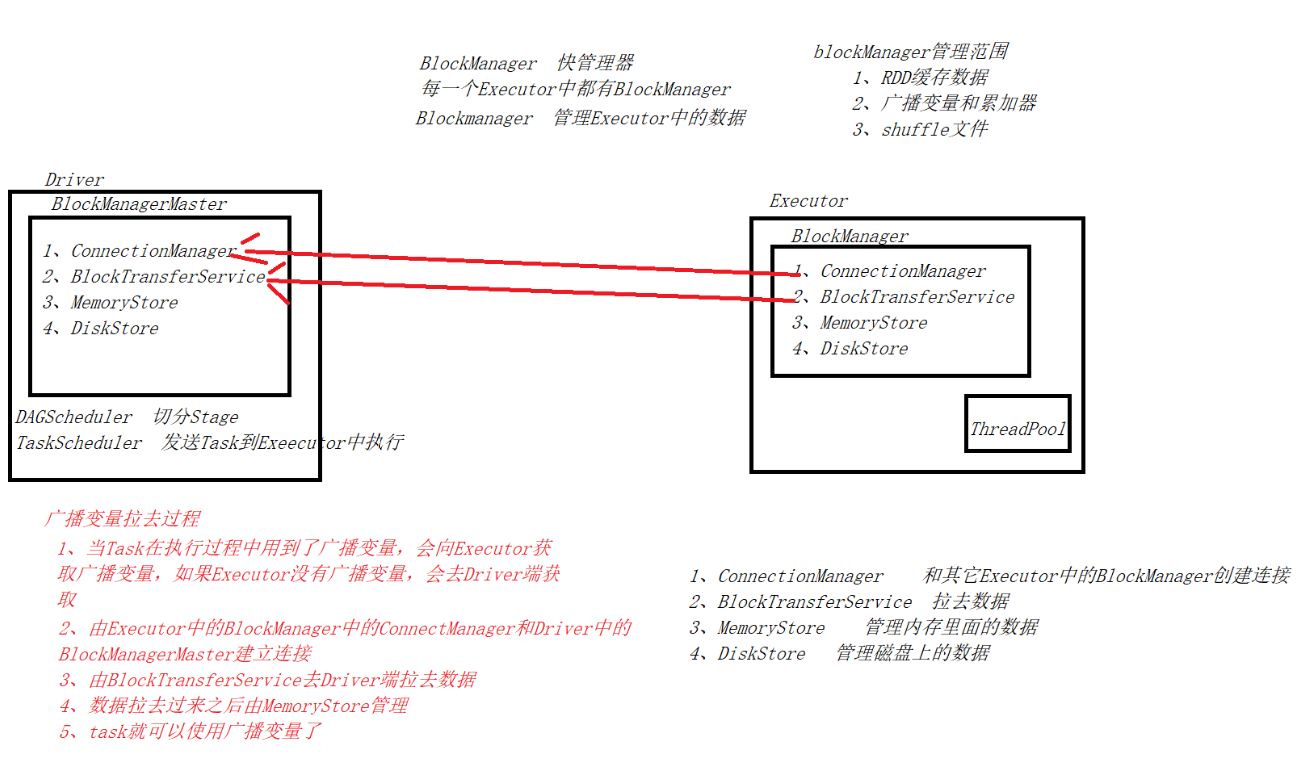
广播变量
如果不使用广播变量变量副本等于task数量
如果使用广播变量变量副本等于Executor数量
广播变量只能在Driver定义,在Executor端读取
rdd 算子里面不能使用其它rdd

累加器
全局累加变量
1、只能在Driver端定义
2、只能Executor端累加
3、只能在Driver读取
spark shuffle
hash shuffle
产生小文件的数量:m*r
hash shuffle manager
产生小文件的数量:c*r
sort shuffle 默认
产生小文件的数量:2*m
sort shuffle bypass机制
产生小文件的数量:2*m
数据在map端不会排序
当 reduce数量小于 spark.shuffle.sort.bypassMergeThreshold=200触发bypass机制
快的原因
尽量将数据放到内存里面进行计算
粗粒度资源调度
DAG有向无环图
切分Stoge
RDD五大特性
1、RDD由一组partition组成
2、函数操作实际是作用在每个partition上
3、RDD之间由一系列依赖关系
4、分区类算子必须作用在kv格式的rdd上
reducebeykey,groupbykey
5、spark为task执行提供了最佳计算位置
BlockManager
每个Executor中都有一个
管理数据
1、RDD缓存数据
2、shuffle数据
3、广播变量和累加器

Spark core 总结的更多相关文章
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9a7c0a1 转换为 spark.core.IViewport。
1.错误描述 TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9aa90a1 转换为 spark.core.IViewport. ...
- Spark Core
Spark Core DAG概念 有向无环图 Spark会根据用户提交的计算逻辑中的RDD的转换(变换方法)和动作(action方法)来生成RDD之间的依赖关系,同时 ...
- spark core (二)
一.Spark-Shell交互式工具 1.Spark-Shell交互式工具 Spark-Shell提供了一种学习API的简单方式, 以及一个能够交互式分析数据的强大工具. 在Scala语言环境下或Py ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- SparkSQL 与 Spark Core的关系
不多说,直接上干货! SparkSQL 与 Spark Core的关系 Spark SQL构建在Spark Core之上,专门用来处理结构化数据(不仅仅是SQL). Spark SQL在Spark C ...
- Spark Core知识点复习-1
Day1111 Spark任务调度 Spark几个重要组件 Spark Core RDD的概念和特性 生成RDD的两种类型 RDD算子的两种类型 算子练习 分区 RDD的依赖关系 DAG:有向无环图 ...
- Spark Core知识点复习-2
day1112 1.spark core复习 任务提交 缓存 checkPoint 自定义排序 自定义分区器 自定义累加器 广播变量 Spark Shuffle过程 SparkSQL 一. Spark ...
随机推荐
- R数据分析:国产新冠口服药比辉瑞好的文章的统计做法分享
元旦前在人民日报中央厨房上看到一篇文章,叫做"比肩辉瑞的国产新冠药物VV116,是这样研制和临床试验的",想来就把文献原文找来读了读,写下本文分享给大家,本文主要关注文章的正文中主 ...
- 尝试新的 System.Text.Json 源生成器
尝试新的 System.Text.Json 源生成器 在 .NET 6.0 的预览版中,我们使用 System.Text.Json 发布了一个新的 C# source generator 来帮助改进应 ...
- Linux NAS存储、文件共享
Linux NAS存储之CIFS CIFS是Windows和Unix系统之间共享文件的一种协议,客户端通常是Windwos等.支持多节点同时挂载以及并发写入 1.服务器端操作(存储端) 1.1.服务器 ...
- ThreeJs-09精通粒子特效
一.初识points与点材质 什么叫做点材质,之前说过所有物体都是有定点的比如一个球体,并且将材质设置为线框模式,这个之前就说过所有mesh物体都是由三角形构成,都是有顶点的 我们也可以创建点物体,电 ...
- 基于开源IM即时通讯框架MobileIMSDK:RainbowChat-iOS端v9.1版已发布
关于MobileIMSDK MobileIMSDK 是一套专门为移动端开发的开源IM即时通讯框架,超轻量级.高度提炼,一套API优雅支持 UDP .TCP .WebSocket 三种协议,支持 iOS ...
- 基于Netty,徒手撸IM(一):IM系统设计篇
本文收作者"大白菜"分享,有改动.注意:本系列是给IM初学者的文章,IM老油条们还望海涵,勿喷! 1.引言 这又是一篇基于Netty的IM编码实践文章,因为合成一篇内容太长,读起来 ...
- 让我看看有多少人不知道Vue3中也能实现高阶组件HOC
前言 高阶组件HOC在React社区是非常常见的概念,但是在Vue社区中却是很少人使用.主要原因有两个:1.Vue中一般都是使用SFC,实现HOC比较困难.2.HOC能够实现的东西,在Vue2时代mi ...
- 使用Vue+ElementUI实现前端分页
背景 项目中要做一个公共的附件展示列表,针对某个模块某条记录展示,因此附件不会是大数据量,采用前端分页,使用Vue.JS+ElementUI布局展示,axios请求数据. 步骤 一.Html页面中引入 ...
- CDS标准视图:会计员 I_AccountingClerk
视图名称:会计员 I_AccountingClerk 视图类型:基础 视图代码: 点击查看代码 @AbapCatalog: { sqlViewName: 'IFIACCCLERK', // compi ...
- C# WinForm 托盘程序
实现步骤 创建 NotifyIcon 控件并设置属性: 编写 NotifyIcon 响应控制事件: 在主窗体的Load事件中将 NotifyIcon 添加到系统托盘: 程序退出时,移除系统托盘的 No ...