SynchronousQueue底层实现原理剖
一、SynchronousQueue底层实现原理剖
SynchronousQueue(同步移交队列),队列长度为0。作用就是一个线程往队列放数据的时候,必须等待另一个线程从队列中取走数据。同样,从队列中取数据的时候,必须等待另一个线程往队列中放数据
二、SynchronousQueue用法
先看一个SynchronousQueue的简单用例:
public class SynchronousQueueDemo {
public static void main(String[] args) throws InterruptedException {
// 1. 创建SynchronousQueue队列
BlockingQueue<Integer> synchronousQueue = new SynchronousQueue<>();
// 2. 启动一个线程,往队列中放3个元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 入队列 1");
synchronousQueue.put(1);
Thread.sleep(1);
System.out.println(Thread.currentThread().getName() + " 入队列 2");
synchronousQueue.put(2);
Thread.sleep(1);
System.out.println(Thread.currentThread().getName() + " 入队列 3");
synchronousQueue.put(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 3. 等待1000毫秒
Thread.sleep(1000L);
// 4. 再启动一个线程,从队列中取出3个元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 出队列 " + synchronousQueue.take());
Thread.sleep(1);
System.out.println(Thread.currentThread().getName() + " 出队列 " + synchronousQueue.take());
Thread.sleep(1);
System.out.println(Thread.currentThread().getName() + " 出队列 " + synchronousQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
输出结果:
Thread-0 入队列 1
Thread-1 出队列 1
Thread-0 入队列 2
Thread-1 出队列 2
Thread-0 入队列 3
Thread-1 出队列 3
从输出结果中可以看到,第一个线程Thread-0往队列放入一个元素1后,就被阻塞了。直到第二个线程Thread-1从队列中取走元素1后,Thread-0才能继续放入第二个元素2
三、SynchronousQueue应用场景
SynchronousQueue的特点:
- 队列长度是0,一个线程往队列放数据,必须等待另一个线程取走数据。同样,一个线程从队列中取数据,必须等待另一个线程往队列中放数据。
这种特殊的实现逻辑有什么应用场景呢 ?
我的理解就是,如果你希望你的任务需要被快速处理,就可以使用这种队列。
Java线程池中的 newCachedThreadPool(带缓存的线程池)底层就是使用SynchronousQueue实现的。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newCachedThreadPool线程池的核心线程数是0,最大线程数是Integer的最大值,线程存活时间是60秒。
如果你使用 newCachedThreadPool 线程池,你提交的任务会被更快速的处理,因为你每次提交任务,都会有一个空闲的线程等着处理任务。如果没有空闲的线程,也会立即创建一个线程处理你的任务。
当然也有弊端,如果你提交了太多的任务,导致创建了大量的线程,这些线程都在竞争CPU时间片,等待CPU调度,处理任务速度也会变慢,所以在使用过程中也要综合考虑。
四、SynchronousQueue源码解析
1、SynchronousQueue类属性
public class SynchronousQueue<E> extends AbstractQueue<E> implements BlockingQueue<E> {
// 转换器,取数据和放数据的核心逻辑都在这个类里面
private transient volatile Transferer<E> transferer;
// 默认的构造方法(使用非公平队列)
public SynchronousQueue() {
this(false);
}
// 有参构造方法,可以指定是否使用公平队列
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
// 转换器实现类
abstract static class Transferer<E> {
abstract E transfer(E e, boolean timed, long nanos);
}
// 基于栈实现的非公平队列
static final class TransferStack<E> extends Transferer<E> {
}
// 基于队列实现的公平队列
static final class TransferQueue<E> extends Transferer<E> {
}
}
可以看到SynchronousQueue默认的无参构造方法,内部使用的是基于栈实现的非公平队列,当然也可以调用有参构造方法,传参是true,使用基于队列实现的公平队列。
// 使用非公平队列(基于栈实现)
BlockingQueue<Integer> synchronousQueue = new SynchronousQueue<>();
// 使用公平队列(基于队列实现)
BlockingQueue<Integer> synchronousQueue = new SynchronousQueue<>(true);
五、常用的栈实现来剖析SynchronousQueue的底层实现原理
1、栈底层结构
栈结构,是非公平的,遵循先进后出。
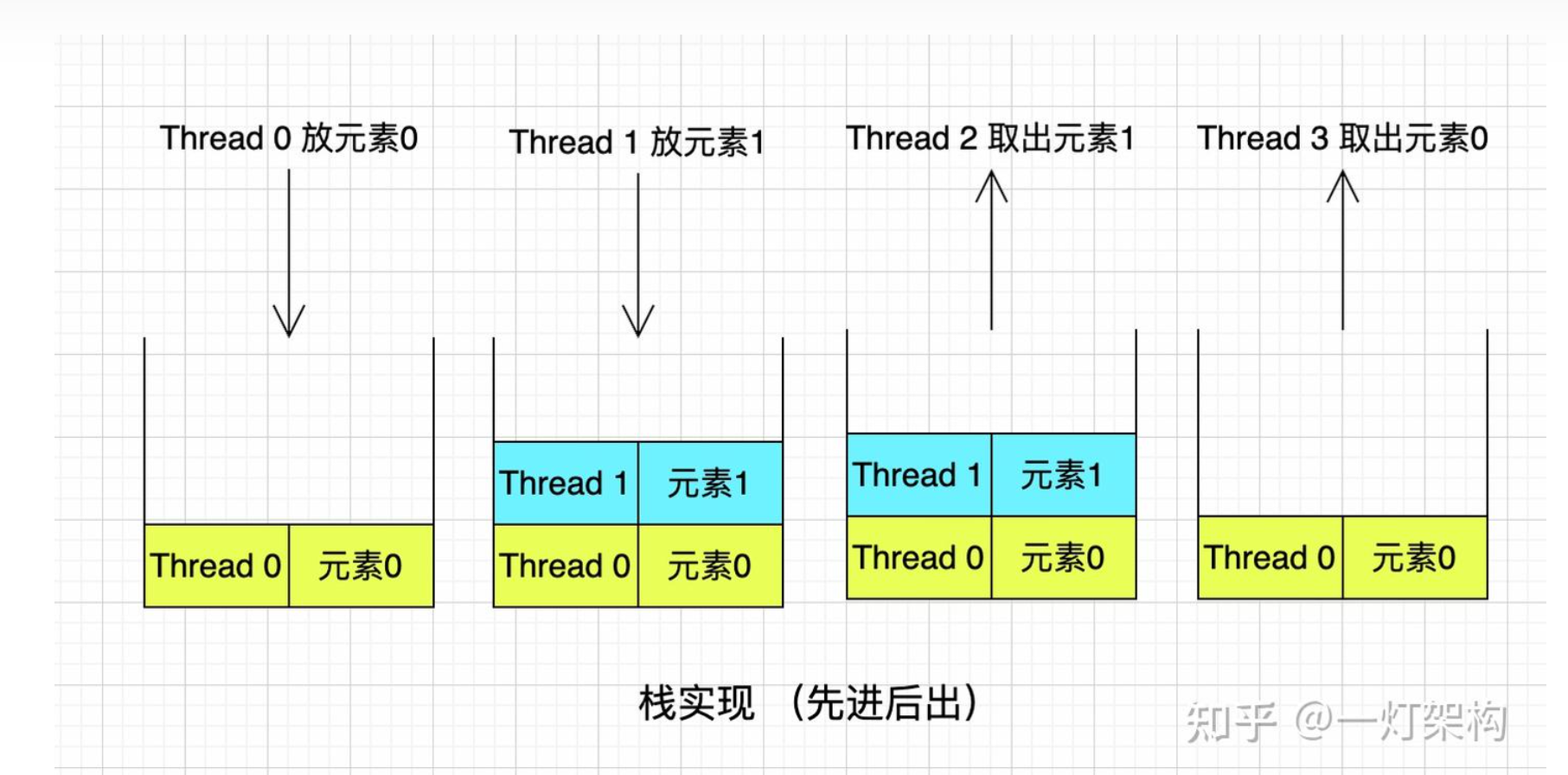
使用个case测试一下
public class SynchronousQueueDemo {
public static void main(String[] args) throws InterruptedException {
// 1. 创建SynchronousQueue队列
SynchronousQueue<Integer> synchronousQueue = new SynchronousQueue<>();
// 2. 启动一个线程,往队列中放1个元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 入队列 0");
synchronousQueue.put(0);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 3. 等待1000毫秒
Thread.sleep(1000L);
// 4. 启动一个线程,往队列中放1个元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 入队列 1");
synchronousQueue.put(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 5. 等待1000毫秒
Thread.sleep(1000L);
// 6. 再启动一个线程,从队列中取出1个元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 出队列 " + synchronousQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 7. 等待1000毫秒
Thread.sleep(1000L);
// 8. 再启动一个线程,从队列中取出1个元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 出队列 " + synchronousQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
输出结果:
Thread-0 入队列 0
Thread-1 入队列 1
Thread-2 出队列 1
Thread-3 出队列 0
从输出结果中可以看出,符合栈结构先进后出的顺序。
2、栈节点源码
栈中的数据都是由一个个的节点组成的,先看一下节点类的源码:
// 节点
static final class SNode {
// 节点值(取数据的时候,该字段为null)
Object item;
// 存取数据的线程
volatile Thread waiter;
// 节点模式
int mode;
// 匹配到的节点
volatile SNode match;
// 后继节点
volatile SNode next;
}
item:节点值,只在存数据的时候用。取数据的时候,这个值是null。
waiter:存取数据的线程,如果没有对应的接收线程,这个线程会被阻塞。
mode:节点模式,共有3种类型:
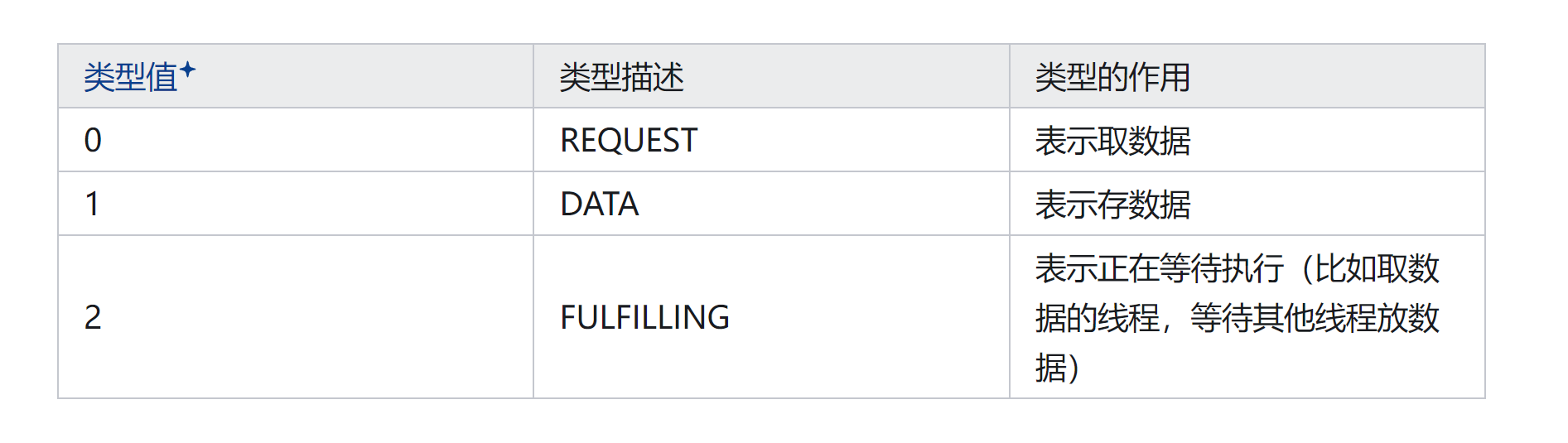
3、put/take流程
放数据和取数据的逻辑,在底层复用的是同一个方法,以put/take方法为例,另外两个放数据的方法,add和offer方法底层实现是一样的
还是以上面的case为例:
1、Thread0先往SynchronousQueue队列中放入元素 0
2、Thread1再往SynchronousQueue队列中放入元素 1
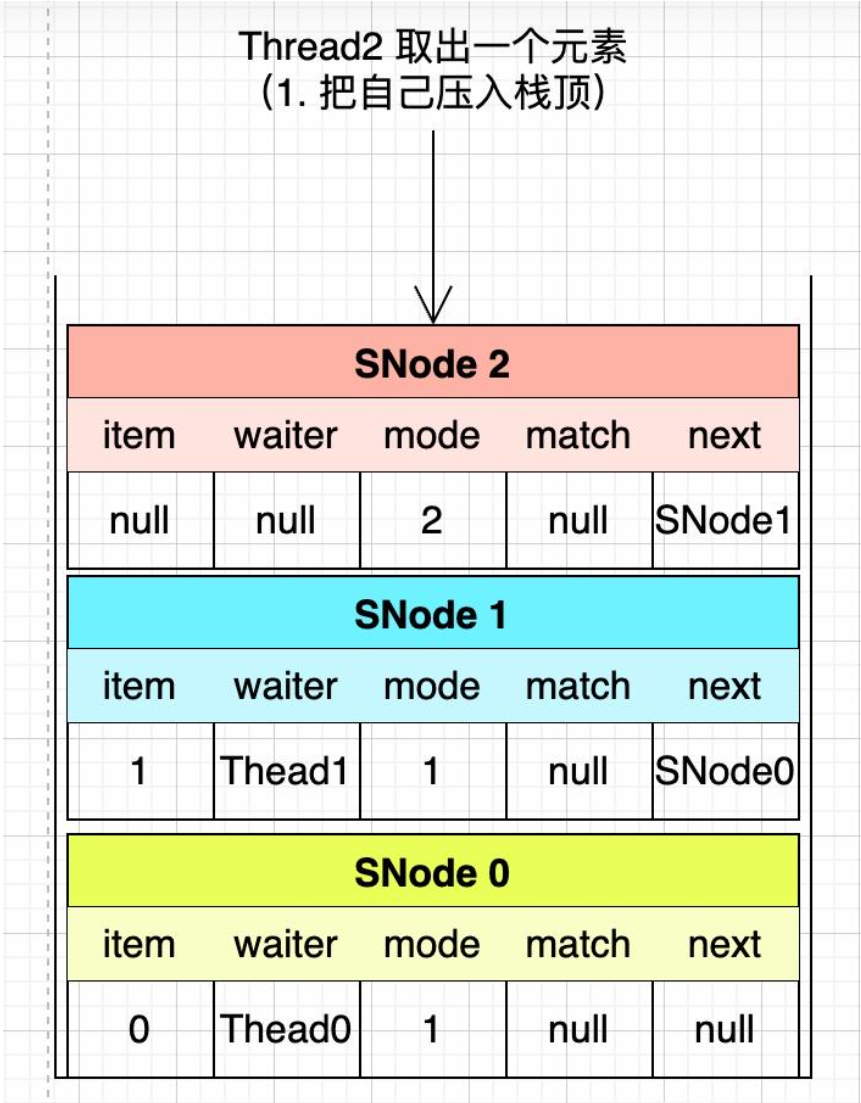
3、Thread2从SynchronousQueue队列中取出一个元素
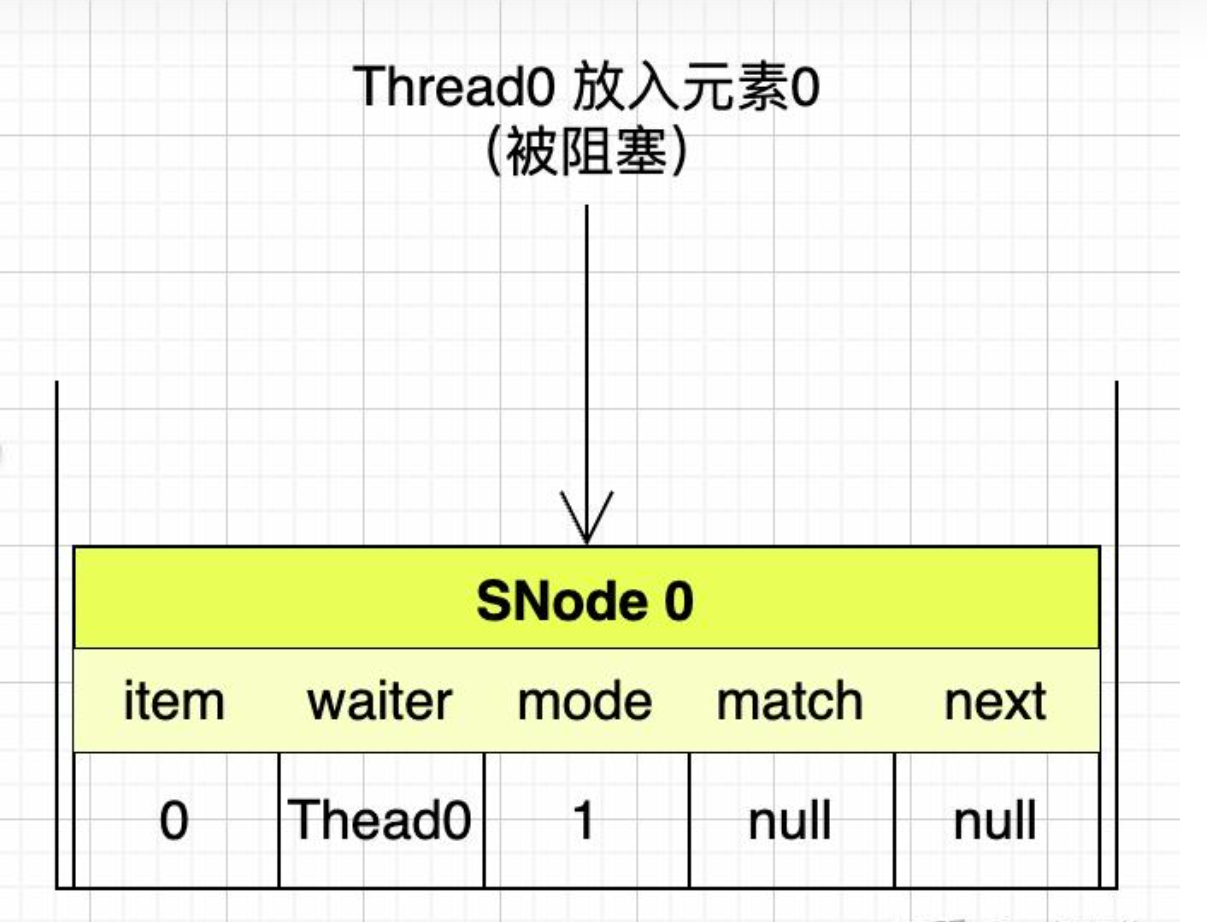
第一步:Thread0先往SynchronousQueue队列中放入元素 0
把本次操作组装成SNode压入栈顶,item是元素0,waiter是当前线程Thread0,mode是1表示放入数据。
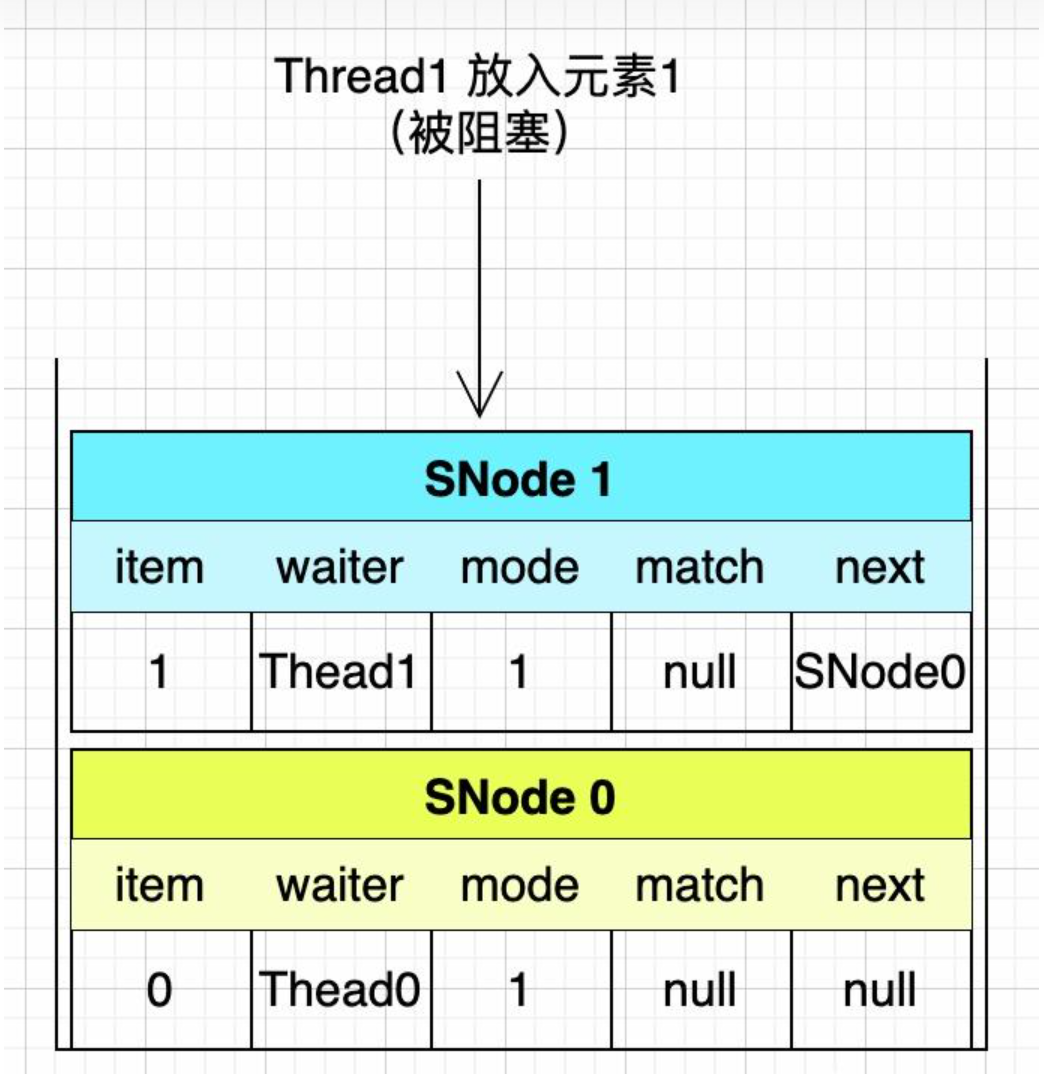
第二步:Thread1再往SynchronousQueue队列放入元素 1
把本次操作组装成SNode压入栈顶,item是元素1,waiter是当前线程Thread1,mode是1表示放入数据,next是SNode0。
第三步:Thread2从SynchronousQueue队列中取出一个元素
这次的操作比较复杂,也是先把本次的操作包装成SNode压入栈顶。
item是null(取数据的时候,这个字段没有值),waiter是null(当前线程Thread2正在操作,所以不用赋值了),mode是2表示正在操作(即将跟后继节点进行匹配),next是SNode1。
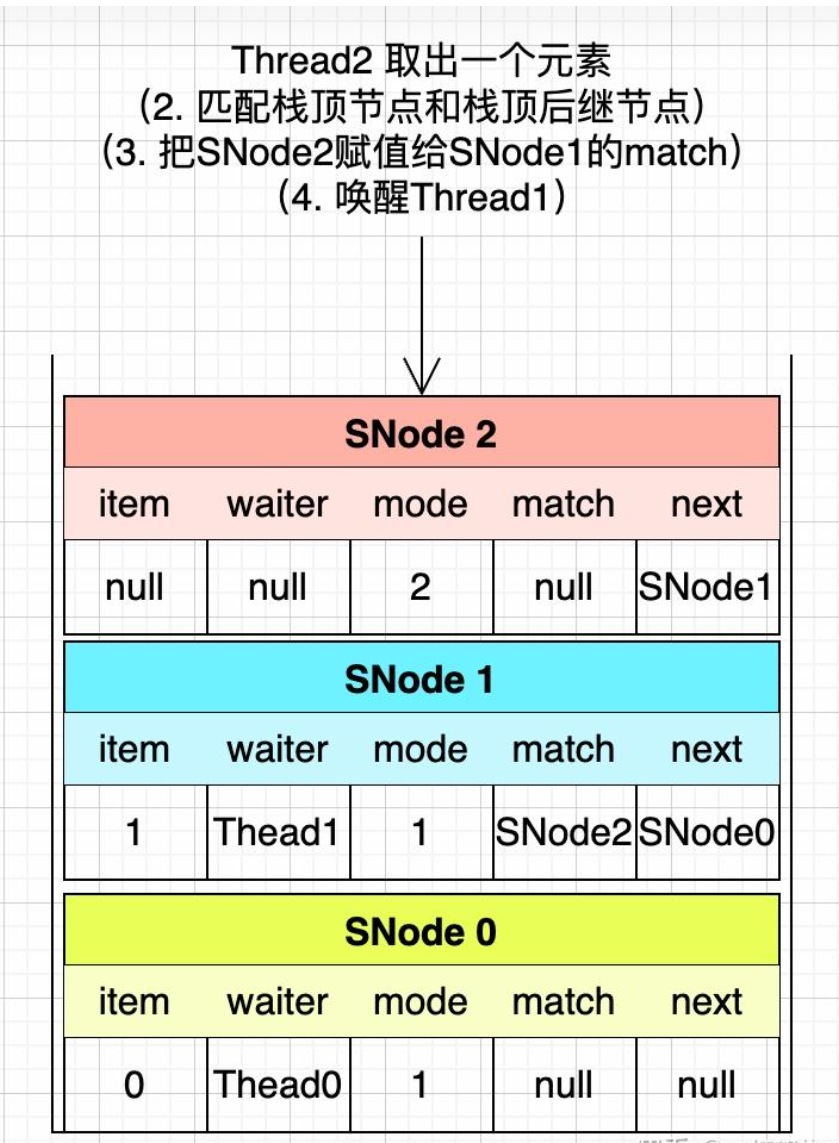
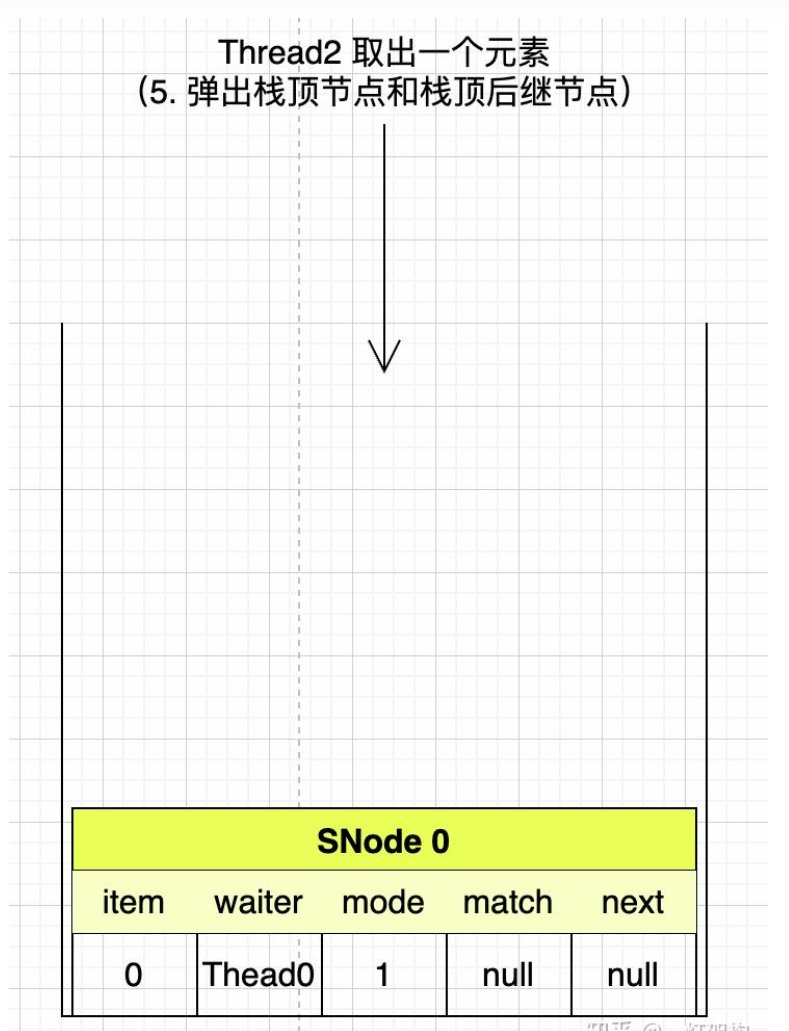
然后,Thread2开始把栈顶的两个节点进行匹配,匹配成功后,就把SNode2赋值给SNode1的match属性,唤醒SNode1中的Thread1线程,然后弹出SNode2节点和SNode1节点。
4、put/take源码实现
看完 了put/take流程,再来看源码就简单多了
先看一下put方法源码:
// 放数据
public void put(E e) throws InterruptedException {
// 不允许放null元素
if (e == null)
throw new NullPointerException();
// 调用转换器实现类,放元素
if (transferer.transfer(e, false, 0) == null) {
// 如果放数据失败,就中断当前线程,并抛出异常
Thread.interrupted();
throw new InterruptedException();
}
}
核心逻辑都在transfer方法中,代码很长,理清逻辑后,也很容易理解。
// 取数据和放数据操作,共用一个方法
E transfer(E e, boolean timed, long nanos) {
SNode s = null;
// e为空,说明是取数据,否则是放数据
int mode = (e == null) ? REQUEST : DATA;
for (; ; ) {
SNode h = head;
// 1. 如果栈顶节点为空,或者栈顶节点类型跟本次操作相同(都是取数据,或者都是放数据)
if (h == null || h.mode == mode) {
// 2. 判断节点是否已经超时
if (timed && nanos <= 0) {
// 3. 如果栈顶节点已经被取消,就删除栈顶节点
if (h != null && h.isCancelled())
casHead(h, h.next);
else
return null;
// 4. 把本次操作包装成SNode,压入栈顶
} else if (casHead(h, s = snode(s, e, h, mode))) {
// 5. 挂起当前线程,等待被唤醒
SNode m = awaitFulfill(s, timed, nanos);
// 6. 如果这个节点已经被取消,就删除这个节点
if (m == s) {
clean(s);
return null;
}
// 7. 把s.next设置成head
if ((h = head) != null && h.next == s)
casHead(h, s.next);
return (E) ((mode == REQUEST) ? m.item : s.item);
}
// 8. 如果栈顶节点类型跟本次操作不同,并且不是FULFILLING类型
} else if (!isFulfilling(h.mode)) {
// 9. 再次判断如果栈顶节点已经被取消,就删除栈顶节点
if (h.isCancelled())
casHead(h, h.next);
// 10. 把本次操作包装成SNode(类型是FULFILLING),压入栈顶
else if (casHead(h, s = snode(s, e, h, FULFILLING | mode))) {
// 11. 使用死循环,直到匹配到对应的节点
for (; ; ) {
// 12. 遍历下个节点
SNode m = s.next;
// 13. 如果节点是null,表示遍历到末尾,设置栈顶节点是null,结束。
if (m == null) {
casHead(s, null);
s = null;
break;
}
SNode mn = m.next;
// 14. 如果栈顶的后继节点跟栈顶节点匹配成功,就删除这两个节点,结束。
if (m.tryMatch(s)) {
casHead(s, mn);
return (E) ((mode == REQUEST) ? m.item : s.item);
} else
// 15. 如果没有匹配成功,就删除栈顶的后继节点,继续匹配
s.casNext(m, mn);
}
}
} else {
// 16. 如果栈顶节点类型跟本次操作不同,并且是FULFILLING类型,
// 就再执行一遍上面第11步for循环中的逻辑(很少概率出现)
SNode m = h.next;
if (m == null)
casHead(h, null);
else {
SNode mn = m.next;
if (m.tryMatch(h))
casHead(h, mn);
else
h.casNext(m, mn);
}
}
}
}
transfer方法逻辑也很简单,就是判断本次操作类型是否跟栈顶节点相同,如果相同,就把本次操作压入栈顶。否则就跟栈顶节点匹配,唤醒栈顶节点线程,弹出栈顶节点。
transfer方法中调用了awaitFulfill方法,作用是挂起当前线程。
// 等待被唤醒
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
// 1. 计算超时时间
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
// 2. 计算自旋次数
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
s.tryCancel();
// 3. 如果已经匹配到其他节点,直接返回
SNode m = s.match;
if (m != null)
return m;
if (timed) {
// 4. 超时时间递减
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
// 5. 自旋次数减一
if (spins > 0)
spins = shouldSpin(s) ? (spins-1) : 0;
else if (s.waiter == null)
s.waiter = w;
// 6. 开始挂起当前线程
else if (!timed)
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
awaitFulfill方法的逻辑也很简单,就是挂起当前线程。
SynchronousQueue底层实现原理剖的更多相关文章
- Java阻塞队列中的异类,SynchronousQueue底层实现原理剖析
上篇文章谈到BlockingQueue的使用场景,并重点分析了ArrayBlockingQueue的实现原理,了解到ArrayBlockingQueue底层是基于数组实现的阻塞队列. 但是Blocki ...
- PHP底层工作原理
最近搭建服务器,突然感觉lamp之间到底是怎么工作的,或者是怎么联系起来?平时只是写程序,重来没有思考过他们之间的工作原理: PHP底层工作原理 图1 php结构 从图上可以看出,php从下到上是一个 ...
- Java并发之底层实现原理学习笔记
本篇博文将介绍java并发底层的实现原理,我们知道java实现的并发操作最后肯定是由我们的CPU完成的,中间经历了将java源码编译成.class文件,然后进行加载,然后虚拟机执行引擎进行执行,解释为 ...
- spirng底层实现原理
什么是框架?框架解决的是什么问题? 编程有一个准则,Don't Repeat Yourself(不要重复你的代码),所以我们会将重复的代码抽取出来,封装到方法中:如果封装的方法过多,将将这些方法封装成 ...
- iOS weak底层实现原理
今年年底做了很多决定,离开工作三年的深圳,来到了上海,发现深圳和上海在苹果这方面还是差距有点大的,上海的市场8成使用swift编程,而深圳8成的使用OC,这点还是比较让准备来上海打拼的苹果工程师有点小 ...
- 《Java并发编程的艺术》Java并发机制的底层实现原理(二)
Java并发机制的底层实现原理 1.volatile volatile相当于轻量级的synchronized,在并发编程中保证数据的可见性,使用 valotile 修饰的变量,其内存模型会增加一个 L ...
- Spring(二)IOC底层实现原理
IOC原理 将对象创建交给Spring去管理. 实现IOC的两种方式 IOC配置文件的方式 IOC注解的方式 IOC底层实现原理 底层实现使用的技术 1.1 xml配置文件 1.2 dom4j解析xm ...
- iOS分类底层实现原理小记
摘要:iOS分类底层是怎么实现的?本文将分如下四个模块进行探究分类的结构体编译时的分类分类的加载总结本文使用的runtime源码版本是objc4-680文中类与分类代码如下//类@interfaceP ...
- java并发编程系列七:volatile和sinchronized底层实现原理
一.线程安全 1. 怎样让多线程下的类安全起来 无状态.加锁.让类不可变.栈封闭.安全的发布对象 2. 死锁 2.1 死锁概念及解决死锁的原则 一定发生在多个线程争夺多个资源里的情况下,发生的原因是 ...
- 那些年读过的书《Java并发编程的艺术》一、并发编程的挑战和并发机制的底层实现原理
一.并发编程的挑战 1.上下文切换 (1)上下文切换的问题 在处理器上提供了强大的并行性就使得程序的并发成为了可能.处理器通过给不同的线程分配不同的时间片以实现线程执行的自动调度和切换,实现了程序并行 ...
随机推荐
- HERS: Homomorphically Encrypted Representation Search-2020:学习
阅读"HERS: Homomorphically Encrypted Representation Search-2020",记录笔记. 摘要 本文介绍了一种针对加密图像的搜索方法 ...
- Nginx防盗链设置
原文:https://blog.liuzijian.com/post/e2c56cc3-1002-4f41-aec8-9a69f57e3c3f.html 1.防止盗链 要防止特定路径下的图片被盗链,可 ...
- el-table当前行的获取和设置,用于表格行操作
1.在vue的data区声明当前行变量对象,如果当前行的信息用于了按钮的状态则需要赋予默认值,否则会报找不到属性的错误,比如下面会用到当前记录的status属性值控制按钮是否可用. //表格选中的行 ...
- Jenkins使用maven打包项目
Jenkins使用maven打包项目 作为一名软件测试工程师,在日常工作中,我们经常需要使用Jenkins进行持续集成和持续部署(CI/CD).而Maven作为Java项目的构建工具,更是不可或缺.今 ...
- 在IDEA如何使用JProfiler性能分析
一.下载地址 https://www.ej-technologies.com/download/jprofiler/files 版本:11 激活码:L-J11-Everyone#speedzodiac ...
- NLLB 与 ChatGPT 双向优化:探索翻译模型与语言模型在小语种应用的融合策略
作者:来自 vivo 互联网算法团队- Huang Minghui 本文探讨了 NLLB 翻译模型与 ChatGPT 在小语种应用中的双向优化策略.首先介绍了 NLLB-200 的背景.数据.分词器和 ...
- [JSOI2008]火星人 题解
原题链接:\(luogu\)$\ \ $ \(BZOJ\)$\ \ $ \(LOJ\) 题目大意:有一个可以支持插入和修改的字符串,定义函数 \(\operatorname{LCQ(x,y)}\) 表 ...
- 库卡KUKA机器人KRC2示教器维修常见方法
库卡KUKA机器人以稳定性而备受赞誉.作为其重要组成部分,KRC2示教器在机器人的编程.监控和调试过程中发挥着至关重要的作用.然而,就像其他任何电子设备一样,KRC2示教器在长期使用过程中也可能会遇到 ...
- Ansible - [05] 配置文件详解
主配置文件 ansible.cfg 修改sudo相关配置,在实际工作中,可能使用ansible时,所使用的用户并不是root用户,而是管理员给的一个普通用户,所以需要考虑ansible相关配置文件需要 ...
- C# TCP/IP通信,Socket通信例子
1.服务端建立监听,等待客户端连接 class Program { static void Main(string[] args) { TcpListener listener = new TcpLi ...