Facebook内部都在用的存储引擎,LSM凭什么能硬扛亿级写入流量?
RocksDB LSM树
RocksDB是Meta (Facebook) 开源的高性能持久化键值存储库,源于Google的LevelDB,并针对SSD和服务器工作负载进行了深度优化。它广泛应用于需要处理海量数据(亿级甚至更高)并要求高写入吞吐的场景。
RocksDB 以 kv 对集合的形式存储数据, key 和 value 是任意长度的字节数组(byte array)。RocksDB 提供了几个用于操作 kv 集合的函数底层接口:
// 插入新的键值对或更新已有键值对
put(key, value)
// 将新值与给定键的原值进行合并
merge(key, value)
// 从集合中删除键值对
delete(key)
// 通过点查来获取 key 所关联的 value
get(key)
// 通过迭代器进行范围扫描——找到特定的key,并按顺序访问该key后续的键值对
iterator.seek(key_prefix); iterator.value(); iterator.next()
LSM树
RocksDB 的核心数据结构被称为日志结构合并树 (Log Structured Merge Tree,LSM Tree)。LSM树是一种专为写密集型工作负载设计的数据结构,其思想最早由O'Neil等人在1996年的同名论文提出被大家所知。
在2000年左右,谷歌发布了大名鼎鼎的"三驾马车"的论文,分别是Google File System(2003年),MapReduce(2004年),BigTable(2006年)。其中在 “BigTable” 的论文中很多很酷的方面之一就是它所使用的文件组织方式,这个方法的名字叫 LSM树 。
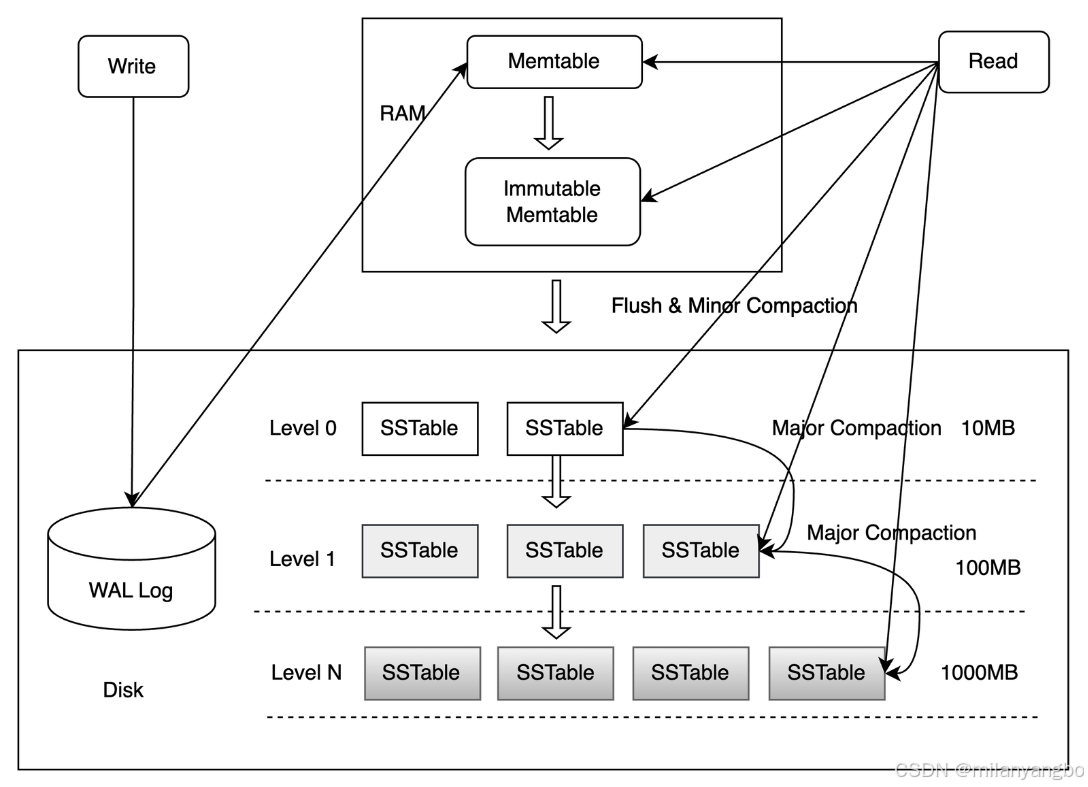
如上图所示,LSM树有以下四个重要组成部分。
1)MemTable(内存表):MemTable是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据,LSM树未明确定义有序组织的数据结构,例如RocksDB使用平衡二叉树来保证内存中key的有序。
2)Immutable MemTable(不可变内存表):Immutable MemTable是将转MemTable变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。
3)WAL:因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过预写式日志(Write-ahead logging,WAL)的方式来保证数据的可靠性。
WAL是一个只允许追加(Append Only)的文件,包含一组更改记录序列。每个记录包含键值对、记录类型(Put / Merge / Delete)和校验和(checksum)。与 MemTable 不同,在 WAL 中,记录不按 key 有序,而是按照请求到来的顺序被追加到 WAL 中。
WAL是顺序写的,速度很快。若系统崩溃,可通过WAL恢复MemTable中的数据。
4)SSTable(Sorted String Table,有序字符串表):SSTable是一种拥有持久化,有序且不可变的的键值存储结构,它的key和value都是任意的字节数组,并且了提供了按指定key查找和指定范围的key区间迭代遍历的功能。
SSTable内部包含了一系列可配置大小的Block块,典型的大小是64KB。与 WAL 的记录类似,每个数据块中都包含用于检测数据是否损坏的校验和。每次从硬盘读取数据时,LSM树都会使用这些校验和进行校验。
当一个SSTable被打开的时候,存储在SSTable尾部的index会被加载到内存,然后根据key在内存index里面进行一个二分查找,查到该key对应的硬盘的offset之后,然后去硬盘把相应的块数据读取出来。

数据写入
写入一个<Key, Value>时,LSM树的写入顺序是:
1)写操作记录到WAL(顺序写)。
2)写操作插入到内存中的MemTable(有序插入)。
3)当MemTable写满,转换为Immutable MemTable,同时创建新的MemTable和WAL文件接收新写入。
4)后台线程将Immutable MemTable的数据顺序写入磁盘,生成一个新的SSTable文件,通常放在Level-0层。
5)刷盘完成后,对应的WAL文件可以被安全删除。 所有磁盘写入(WAL和SSTable)都是顺序的,极大地提高了写入吞吐。
MemTable 的默认大小为 64 MB。 LSM树定期把内存写满的MemTable转变为Immutable MemTable ,并从内存持久化到硬盘。一旦刷盘(flush)完成,Immutable MemTable 和相应的 WAL就会被丢弃。LSM树写入新的 WAL、MemTable。
每次刷盘都会在 Level 0 层上产生一个新的SSTable文件。该文件一旦写入硬盘后,就不再会修改。有序性使得 MemTable 刷盘时更高效,因为可以直接按顺序迭代键值对顺序写入硬盘。将随机写变为顺序写是 LSM树的核心设计之一。
数据删除
对于需要删除的数据,LSM 树采用一个特殊的标志位,称为墓碑(tombstone),删除一条数据就是把它的值置为墓碑。如果查询当前数据,返回的是空值。因此,删除操作的本质是覆盖写,而不是清除一条数据,墓碑会在合并机制中被清理掉,于是置为墓碑的数据在新的 SSTable 中将不复存在。

合并机制
由于SSTable不可修改,更新和删除操作实际上是写入新的记录(更新是新版本,删除是打上“墓碑”标记Tombstone)。这样的设计虽然大大提高了写性能,但同时也会带来一些问题。
1)空间放大 (Space Amplification):磁盘上可能存在同一Key的多个版本或已删除的“墓碑”,占用额外空间。
2)读放大 (Read Amplification):查询一个Key时,可能需要从MemTable查起,然后逐层(从新到旧)查找多个SSTable,直到找到该Key或确认不存在。
3)写放大 (Write Amplification):实际写入磁盘的数据量远大于用户写入的数据量,因为数据在合并过程中会被多次重写。
合并 (Compaction)机制是LSM树维持性能和控制放大的关键:后台线程定期将不同层级(Level)的SSTable进行合并。合并过程会读取多个旧SSTable,将它们的有序键值对归并排序,丢弃被覆盖的旧值和已删除的墓碑,然后将结果写入新的SSTable(通常到下一层)。通过这种方式,减少SSTable数量(降低读放大)、回收无效数据占用的空间(降低空间放大)。然而合并本身是I/O密集型操作,会产生写放大,消耗处理器和磁盘带宽。
RocksDB提供不同的合并策略,如:Leveled Compaction (分层合并):将数据组织成多个层(L0, L1, L2...)。L0的SSTable可能有重叠的Key范围,L1及以上层SSTable的Key范围通常不重叠。合并时,从Ln层选择一个SSTable,与Ln+1层中Key范围重叠的SSTable进行合并。这种策略读放大较小,但写放大可能较高。
Tiered Compaction (分级合并,也称Universal Compaction):将SSTable按大小或时间分组,组内合并,或将多个小SSTable合并成一个大SSTable。写放大较低,但读放大可能较高。 RocksDB允许用户根据应用特性选择和配置合并策略,以在读、写、空间放大之间取得平衡。


数据查询
查询一个Key时,LSM树的查找顺序是:
1)Active MemTable。
2)Immutable MemTable。
3)SSTables on Level-0 (可能有多个,Key范围可能重叠,需逐个查)。
4)SSTables on Level-1, Level-2, ..., Level-N(每层内Key范围不重叠或部分不重叠,可快速定位)。
LSM树在内存中对每个SSTable维护一个稀疏索引(Sparse index)。稀疏索引是指将有序数据切分成(固定大小的)块,仅对各个块开头的一条数据做索引。与之相对的是全量索引(Dense index),即对全部数据编制索引,比如MySQL采用B+树作为索引结构。
有稀疏索引之后,可以先在索引表中使用二分查找快速定位某个 key 位于SSTable哪一小块数据中,这样仅从硬盘中读取这一块数据即可获得最终查询结果,此时加载的数据量仅仅是整个 SSTable 的一小部分,因此 I/O 代价较小。
然而当要查询的结果在 SSTable 中不存在时,将不得不依次扫描完所有的层级SSTable,这是最差的一种情况。因此,为加速查询,特别是查询不存在的Key,每个SSTable通常会关联一个布隆过滤器(Bloom Filter)。查询时先查布隆过滤器,若告知Key“肯定不存在”,则可直接跳过该SSTable的实际读取,显著减少不必要的I/O。布隆过滤器有一定假阳性率(可能误报“存在”),但绝无假阴性(不会漏报)。

未完待续
很高兴与你相遇!如果你喜欢本文内容,记得关注哦!!!
Facebook内部都在用的存储引擎,LSM凭什么能硬扛亿级写入流量?的更多相关文章
- Python全栈-数据库存储引擎
一.存储引擎概述 在个人PC机中,不同的文件类型有不同的处理机制进从存取,例如文本用txt打开.保存:表格用excel读.写等.在数据库中,同时也存在多种类型的表,因此数据库操作系统中也应拥有对各种表 ...
- mysql 数据表操作 存储引擎介绍
一 什么是存储引擎? 存储引擎就是表的类型. mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制 ...
- SQL学习笔记三(补充-1)之MySQL存储引擎
阅读目录 一 什么是存储引擎 二 mysql支持的存储引擎 三 使用存储引擎 一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的 ...
- mysql三-1:存储引擎
一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型 ...
- mysql数据库从删库到跑路之mysql存储引擎
一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件应该有不同的类型:比如存文本用txt类型,存表格用excel,存图片用pn ...
- MySQL数据库篇之存储引擎
主要内容: 一.数据引擎 二.MySQL支持的存储引擎 三.使用存储引擎 1️⃣ 什么是存储引擎? MySQL中建立的库----> 文件夹,库中建立的表----->文件. 现实生活中我们用 ...
- mysql 库操作、存储引擎、表操作
阅读目录 库操作 存储引擎 什么是存储引擎 mysql支持的存储引擎 如何使用存储引擎 表操作 创建表 查看表结构 修改表ALTER TABLE 复制表 删除表 数据类型 表完整性约束 回到顶部 一. ...
- mysql三-1:理解存储引擎
一.什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型,处 ...
- DAY10-MYSQL存储引擎
一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型 ...
- MySQL三:存储引擎
阅读目录 一 什么是存储引擎 二 mysql支持的存储引擎 三 使用存储引擎 一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的 ...
随机推荐
- CSharp中的文件操作
在C#中,可以使用System.IO命名空间中的类来进行Windows文件操作.这些类提供了丰富的方法来处理文件和目录,包括创建.复制.删除.移动文件和目录,以及读取和写入文件等功能. 常用文件操作方 ...
- Chester1011的疑问
题目背景 一天,\(\texttt{Chester}\)和\(\texttt{hsh}\)在写数据结构题. 他们开始刷起了羊毛地毯.在羊毛地毯的落地点,有一个漏斗.漏斗下面会经过漏斗矿车,每次只能吸走 ...
- [译]MIT6.824_1.1分布式系统介绍——驱动力与挑战
这是6.824分布式系统课程,我会开始用简明的介绍我所认为的分布式系统. 分布式系统的核心是通过网络以完成一致任务的一组协作计算机. 因此我们将在本课程中重点介绍各种实例,例如大型网站的存储或MapR ...
- 团队如何限制合适的在制品(WIP)数量
看板之父David Anderson曾说过" 看板的本质是一个很朴素的思想:在制品必须被限制."但对于团队来说,确定一个合适的在制品限制可能是件棘手的事. 在 <看板快速启动 ...
- 超实用!10 个 Excel 数据验证技巧,轻松解决数据录入难题
[Excel基础系列之十二] 嗨,宝子们,我是社会牛马"表哥"--EETools. 在数据管理与日常办公中,Excel 数据验证如同一位 "数据质检员",从源头 ...
- [书籍精读]《JavaScript异步编程》精读笔记分享
写在前面 书籍介绍:本书讲述基本的异步处理技巧,包括PubSub.事件模式.Promises等,通过这些技巧,可以更好的应对大型Web应用程序的复杂性,交互快速响应的代码.理解了JavaScript的 ...
- Iceberg在袋鼠云的探索及实践
"数据湖"."湖仓一体"及"流批一体"等概念,是近年来大数据领域热度最高的词汇,在各大互联网公司掀起了一波波的热潮,各家公司纷纷推出了自己的 ...
- 开源项目丨Taier1.2版本发布,新增工作流、租户绑定简化等多项功能
2022年7月26日,Taier1.2版本正式发布! 本次版本发布更新功能: 新增工作流 新增OceanBase SQL 新增Flink jar任务 数据同步.实时采集支持脏数据管理 Hive UDF ...
- cuda安装失败解决方法
cuda安装失败解决方法 1.问题 安装cuda11.3版本时,一直出现安装失败的情况,多次安装依然失败 之前安装的时候都是默认选择推荐的安装,如下图所示: 失败的图片如下: 2.解决方法 解决方法如 ...
- Elastic学习之旅 (12) .NET 6应用集成ES - 下
大家好,我是Edison. 上一篇:.NET集成ES进行CRUD 写在开头 在.NET应用中集成ES一般涉及两个方面: (1)将ES当存储用,类似于MongoDB,做文档的增删查改,这一类操作偏CRU ...