深度学习模型在C++平台的部署
一、概述
深度学习模型能够在各种生产场景中发挥重要的作用,而深度学习模型往往在Python环境下完成训练,因而训练好的模型如何在生产环境下实现稳定可靠的部署,便是一个重要内容。C++开发平台广泛存在于各种复杂的生产环境,随着业务效能需求的不断提高,充分运用深度学习技术的优势显得尤为重要。本文介绍如何实现将深度学习模型部署在C++平台上。
二、步骤
s1. Python环境中安装深度学习框架(如PyTorch、TensorFlow等);
s2. P ython环境中设计并训练深度学习模型;
s3. 将训练好的模型保存为.onnx格式的模型文件;
s4. C++环境中安装Microsoft.ML.OnnxRuntime程序包;
(Visual Studio 2022中可通过项目->管理NuGet程序包完成快捷安装)
s5. C++环境中加载模型文件,完成功能开发。
三、示例
在Python环境下设计并训练一个关于手写数字识别的卷积神经网络(CNN)模型,将模型导出为ONNX格式的文件,然后在C++环境下完成对模型的部署和推理。
1. Python训练和导出
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.functional import F
# 定义简单的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 32 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载训练数据
train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 初始化模型、损失函数和优化器
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
def train(model, train_loader, criterion, optimizer, epochs=5):
model.train()
for epoch in range(epochs):
running_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch+1}, Loss: {running_loss/len(train_loader)}')
# 训练模型
train(model, train_loader, criterion, optimizer)
# 导出为ONNX格式
dummy_input = torch.randn(1, 1, 28, 28)
torch.onnx.export(
model,
dummy_input,
"mnist_model.onnx",
export_params=True,
opset_version=11,
do_constant_folding=True,
input_names=['input'],
output_names=['output'],
dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}
)
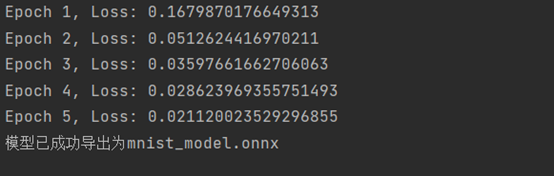
print("模型已成功导出为mnist_model.onnx")
2. C++ 部署和推理
#include <iostream>
#include <vector>
#include <opencv2/opencv.hpp>
#include <onnxruntime_cxx_api.h>
int main() {
// 初始化环境
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "MNIST");
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(1);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
// 加载模型
std::wstring model_path = L"mnist_model.onnx";
Ort::Session session(env, model_path.c_str(), session_options);
// 准备输入
std::vector<int64_t> input_shape = { 1, 1, 28, 28 };
size_t input_tensor_size = 28 * 28;
std::vector<float> input_tensor_values(input_tensor_size);
// 读取测试图片
cv::Mat test_image = cv::imread("test.jpg", cv::IMREAD_GRAYSCALE);
// 将Mat数据复制到vector中
for (int i = 0; i < test_image.rows; ++i) {
for (int j = 0; j < test_image.cols; ++j) {
input_tensor_values[i * test_image.cols + j] = static_cast<float>(test_image.at<uchar>(i, j)); // 注意:uchar是unsigned char的缩写,表示无符号字符,通常用于存储灰度值
}
}
// 创建输入张量
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(
memory_info, input_tensor_values.data(), input_tensor_size, input_shape.data(), 4);
// 设置输入输出名称
std::vector<const char*> input_names;
std::vector<const char*> output_names;
input_names.push_back(session.GetInputNameAllocated(0, Ort::AllocatorWithDefaultOptions()).get());
output_names.push_back(session.GetOutputNameAllocated(0, Ort::AllocatorWithDefaultOptions()).get());
// 运行推理
auto output_tensors = session.Run(
Ort::RunOptions{ nullptr },
input_names.data(),
&input_tensor,
1,
output_names.data(),
1);
// 获取输出结果
float* output = output_tensors[0].GetTensorMutableData<float>();
std::vector<float> results(output, output + 10);
// 找到预测的数字
int predicted_digit = 0;
float max_probability = results[0];
for (int i = 1; i < 10; i++) {
if (results[i] > max_probability) {
max_probability = results[i];
predicted_digit = i;
}
}
std::cout << "预测结果: " << predicted_digit << std::endl;
std::cout << "置信度分布:" << std::endl;
for (int i = 0; i < 10; i++) {
std::cout << "数字 " << i << ": " << results[i] << std::endl;
}
return 0;
}
测试图片:
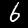
程序运行:

End.
深度学习模型在C++平台的部署的更多相关文章
- flask部署深度学习模型
flask部署深度学习模型 作为著名Python web框架之一的Flask,具有简单轻量.灵活.扩展丰富且上手难度低的特点,因此成为了机器学习和深度学习模型上线跑定时任务,提供API的首选框架. 众 ...
- PyTorch如何构建深度学习模型?
简介 每过一段时间,就会有一个深度学习库被开发,这些深度学习库往往可以改变深度学习领域的景观.Pytorch就是这样一个库. 在过去的一段时间里,我研究了Pytorch,我惊叹于它的操作简易.Pyto ...
- 用 Java 训练深度学习模型,原来可以这么简单!
本文适合有 Java 基础的人群 作者:DJL-Keerthan&Lanking HelloGitHub 推出的<讲解开源项目> 系列.这一期是由亚马逊工程师:Keerthan V ...
- CUDA上深度学习模型量化的自动化优化
CUDA上深度学习模型量化的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参数 ...
- CUDA上的量化深度学习模型的自动化优化
CUDA上的量化深度学习模型的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参 ...
- TVM将深度学习模型编译为WebGL
使用TVM将深度学习模型编译为WebGL TVM带有全新的OpenGL / WebGL后端! OpenGL / WebGL后端 TVM已经瞄准了涵盖各种平台的大量后端:CPU,GPU,移动设备等.这次 ...
- 『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析 在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等 ...
- Roofline Model与深度学习模型的性能分析
原文链接: https://zhuanlan.zhihu.com/p/34204282 最近在不同的计算平台上验证几种经典深度学习模型的训练和预测性能时,经常遇到模型的实际测试性能表现和自己计算出的复 ...
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
随机推荐
- Greenplum优化总结
Greenplum优化总结 GP优化需要了解清理缓存.性能监控.执行计划分析等知识.优化主要包含以下四方面: 表.字段,SQL,GP配置.服务器配置,硬件及节点资源. 一. 清理缓存: #!/usr/ ...
- C# 多项目打包时如何将项目引用转为包依赖
项目背景 最近开发一组类库,大约会有五六个项目.一个Core,加上若干面向不同产品的实现库,A/B/C/D...它们都依赖Core. 首先,我想统一版本号,这个容易,通过Directory.Build ...
- Spring RestTemplate使用方法总结
1. 引入依赖 首先,需要确认项目中是否直接或者间接引入过spring-web依赖,如果没有引入过,需要在pom.xml中添加以下代码引入依赖: <dependency> <grou ...
- 使用JSR303进行校验
4.JSR303 1).给Bean添加校验注解:javax.validation.constraints,并定义自己的message提示 2).开启校验功能@Valid 效果:校验错误以后会有默认的响 ...
- 🎀B站-网页优化插件BewlyBewly
简介 一个开源的B站网页优化浏览器插件,对B站网页进行了调整和优化,页面更具视觉吸引力和用户友好性. 源码 https://github.com/BewlyBewly/BewlyBewly 支持 插件 ...
- Spring Bean的声明方式
一.环境说明 项目结构 StudentService package com.cookie.service; /** * @author cxq * @version 1.0 * @date 2020 ...
- 康谋分享 | AD/ADAS的性能概览:在AD/ADAS的开发与验证中“大海捞针”!
如果您希望从数百万小时的驾驶数据中查找特定的相关驾驶事件和未遂事故,以确保您的所需功能正确运行,最好的方法就是创建一个系统性能的概览分析,实现在数据日志中快速检索关注点.为此,康谋在本文将为您详细介绍 ...
- 从源码看 QT 的事件系统及自定义事件
事件是程序内部或外部触发的动作或状态变化的信号.在 Qt 中,所有事件都是 QEvent 派生类的对象,事件由 QObject 派生类的对象接收和处理.每一个事件都有对应的 QEvent 派生类,当事 ...
- 2025dsfz集训Day5:最短路与最小生成树
DAY5 I : 最小生成树 \[Designed\ By\ FrankWkd\ -\ Luogu@Lwj54joy,uid=845400 \] 特别感谢 此次课的主讲 - Kwling 生成树及最小 ...
- Sentinel——流控规则
目录 流控规则 QPS 设置流控规则 api设置流控规则 资源实体指定流控规则 并发线程数 Sentinel 隔离方案 流控模式-关联 流控模式-链路 控制效果 快速失败 Warm Up 排队等待 三 ...