【语义分割专栏】4:deeplab系列原理篇
前言
本篇文章收录于语义分割专栏,如果对语义分割领域感兴趣的,可以去看看专栏,会对经典的模型以及代码进行详细的讲解哦!其中会包含可复现的代码!带大家深入语义分割的领域,将从原理,代码深入讲解,希望大家能从中有所收获,其中很多内容都包含着自己的一些想法以及理解,如果有错误的地方欢迎大家批评指正。
欢迎继续来到语义分割专栏系列的第四篇了,本文将带大家来学习语义分割领域的经典模型:Deeplab系列模型。

背景介绍
首先我们介绍一下Deeplab系列出现的历史背景,其实就是Deeplabv1出现的背景,在当时的语义分割领域,FCN开创了语义分割的新局面,但是不得否认的是,FCN也还是有着很多的问题的,首先我们的语义分割即为图像中每个像素分配一个语义类别标签,其对精度与上下文理解要求是极高的。
FCN通过使用大步的长卷积就会导致分辨率严重下降,尽管其使用反卷积,通过可学习的上采样方式来恢复分辨率,但是当其分辨率下降的过小之后,采取可学习的上采样方式,其上采样质量也难免会比较差,所以就会导致边界模糊的现象。
Deeplab系列讲解
是的,你遇到这些问题你怎么办?希望大家都能够设身处地去思考,我们才能够明白每一项工作的创新意义,同时进行深入思考,很多时候你可能也会有自己的想法,每个创新性的想法都是不经意间的,希望大家都能够有思维的碰撞。好了,话说回来,我们来看看Deeplab的作者时怎么做的,看看人家如何进行解决的。其实如果你有看过Deeplab系列的论文的话你就会发现,其使用了一个非常重要的卷积方式,整个Deeplab系列都离不开它--Atrous convolution(空洞卷积,也有称为dilation convolution)。
Deeplabv1
论文名称:Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
论文地址:Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs

在论文中作者指出了深度卷积神经网络(DCNN,Deep Convolutional Neural Networks)虽然能够比较好的解决分类问题,但是却不能够处理好像素级分割任务。通过分析,因为DCNN具备着很好的平移不变性,所以其在分类任务中表现优异,但是在DCNN中会进行多次的池化和下采样的操作,这些操作就会导致位置信息的丢失,同时空间的不变性特征也会导致细节信息的丢失。这就与我们的语义分割任务不匹配了。
所以在论文中提出两个需要去解决的问题:
多次池化与下采样引发的位置信息丢失问题;
空间不变性导致的细节信息缺失问题。
去池化和全连接层
Deeplabv1的骨干是基于VGG网络的,首先是去掉全连接层,这就没什么好说的了,从FCN出现后,去全连接层在语义分割任务中成了大势,因其跟语义分割任务的不匹配。
其次去pooling层?为什么要去pooling层呢?首先我们来看pooling层具体起到什么作用。pooling能够解决了训练的硬件问题,通过缩小feature map的尺寸,降低对计算资源的需求。pooling还有另一个重要作用,快速扩大感受野。为什么要扩大感受野呢?为了利用更多的上下文信息进行分析。
然后为什么去掉呢?首先,我们要知道最初的DCNN主要用来解决图片的分类问题的,比如说如果我们需要去对一张有着小轿车的图片进行语义分割任务,传统模型只需要指出图片中有没有小轿车,至于小轿车在哪儿,是其不关心的问题。这就需要网络网络具有平移不变性。我们都知道,卷积本身就具有平移不变性,而pooling可以进一步增强网络的这一特性,因为pooling本身就是一个模糊位置的过程。所以pooling对于传统DCNN可以说非常的实用了。
再来说语义分割。语义分割是一个像素级的问题,需要对每个像素进行精确的分类,对像素的位置很敏感,是个精细活儿。这就很尴尬了,pooling是一个不断丢失位置信息的过程,而语义分割又需要这些信息,矛盾就产生了。没办法,就只好去掉pooling了。全去掉行不行,理论上是可行的,实际使用嘛,一来显卡没那么大的内存,二来费时间。所以只去掉了两层。
空洞卷积(Atrous Convolution)
空洞卷积:通过引入空洞结构在不降低特征图分辨率的前提下扩大感受野,从而保留更多位置信息;在不增加参数的情况下扩大感受野;
捕获上下文信息:空洞卷积让网络看到更大的区域;
首先我们先来通过下图来直观的感受一下普通卷积和空洞卷积的区别。其实从图中大家也就能够很直观的看出来并且理解空洞卷积的含义了。其实就是在普通卷积的各个元素之间加上空洞(即填充0)来进行卷积操作。

那么我们的空洞卷积有什么作用呢?最简单也是最直接的作用就是扩大感受野了。关于什么是感受野?我有在我讲述VGG的那篇博客中有涉及到,如果不是很了解的可以去看看。话说回来了,我们为什么需要去扩大感受野呢?
如果从专栏系列看过的我们都知道,无论是语义分割的开山之作FCN还是奠定语义分割baseline地位的U-Net,网络结构中都会存在大量的池化层来进行下采样,大量使用池化层的结果就是损失掉了一些信息,在解码上采样重建分辨率的时候肯定会有影响。特别是对于多目标、小物体的语义分割问题,以U-Net为代表的分割模型一直存在着精度瓶颈的问题。
所以我们希望能不能有什么方法增大感受野呢?当然最简单最直接的就是使用大核卷积,但是其会带来巨大的计算负担,所以这个时候基于增大感受野的动机背景下就提出了重大创新意义的空洞卷积。Deeplabv1通过引入空洞结构在不降低特征图分辨率的前提下扩大感受野,从而保留更多位置信息,并且不增加额外的参数,捕获上下文信息。
全连接条件随机场(Fully - connected Conditional Random Field,CRF)
关于公式推导的一大堆部分就不去细说了,也比较难懂,通俗的讲下CRF到底做了啥。
首先为什么用CRF?因为我们在进行语义分割任务时,上采样难免会损失边界信息的,所以其边界分类就不会很准确。可能在对猫进行语义分割时,其身体被分成了好几块,而CRF就是通过像素和其周围像素的关系来进行微调的。通过下列步骤来进行微调的操作的。
- 看邻居: 如果一个点被猜成“猫”,那它旁边的点也很可能还是“猫”吧?CRF就会加强这种可能性,让相邻的点倾向于有相同的标签。反之,如果旁边有个点被猜成“桌子”,它可能会觉得这个“猫”的标签是不是猜错了,需要调整一下。
- 看整体: 它还会考虑更远一点的联系,比如“通常猫是蹲在桌子上的,不太可能桌子的一部分跑到猫的身体里去”,来帮助修正那些明显不合理的地方。
- 结合细节: 它甚至可以看看这个点的颜色、形状等原始信息,来判断当前标签是不是更合理。比如,如果某个点被猜成“猫”,但颜色是深棕色的木纹,周围又是木纹,DenseCRF可能会觉得这里更可能是“桌子”的一部分。
所以Deeplabv1通过CRF利用其对像素间空间关系的建模能力,补充恢复图像细节信息,提升分割精度。
Deeplabv2
论文名称:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs

在Deeplabv1提出后,在多个数据集上都取得了不错的效果,但是作者发现当存在多尺度的物体时,模型的表现往往不会很好。所以Deeplabv2出来了,通过提出ASPP(Atrous Spatial Pyramid Pooling)来融合多尺度信息,增强对全文语义的理解。
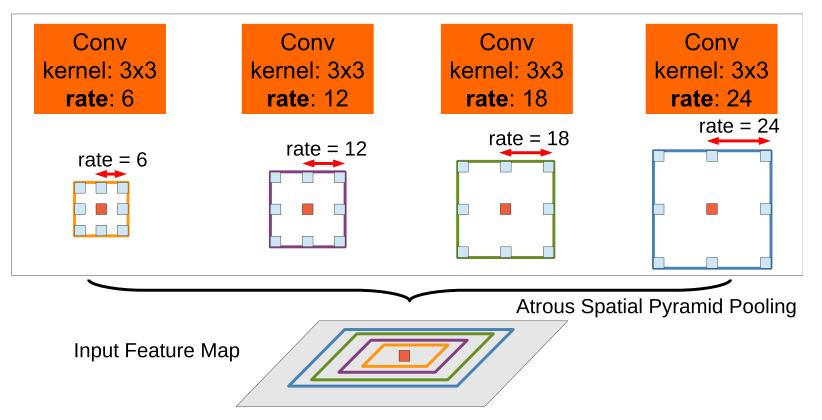
ASPP(Atrous Spatial Pyramid Pooling)
ASPP其实就是在一层上并行使用多个空洞率的并行卷积,获取不同感受野的上下文信息,以提升不同尺度的物体分割效果。简单点说就是,让模型能同时看清楚大的物体和小的物体。
- 多尺度感知:ASPP 提供多个尺度的信息融合,对尺度变化鲁棒;
- 上下文增强:增强了对全局语义的理解能力。
Deeplabv3
论文名称:Rethinking Atrous Convolution for Semantic Image Segmentation
论文地址:Rethinking Atrous Convolution for Semantic Image Segmentation

注意注意Rethingking,其实我们做研究中也要多多的Rethingking,作者在Rethingking中Deeplabv3也来了。
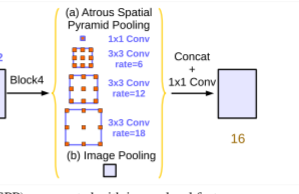
具体做了什么呢?首先就是改进了ASPP,加入了图像级全局平均池化,进一步增强上下文;其次去掉了CRF,可能是对于模型没有增益效果了吧,所以去掉了,这样能够实现端到端的训练了,整体架构会更加简洁。
- 端到端训练:去掉 CRF 后整体更简单;
- 上下文全面感知:增强 ASPP 表达力,提升分割性能。
改进的ASPP
对于ASPP,作者在V3中做了两点改进。首先就是在空洞卷积之后使用batch normalization,据说是因为BN对训练很有帮助。
其次就是增加了1x1卷积分支和image pooling分支。增加这两个分支是为了解决使用空洞卷积带来的问题,随着rate的增大,一次空洞卷积覆盖到的有效像素(特征层本身的像素,相应的补零像素为非有效像素)会逐渐减小到1(这里没有图全靠脑补)。这就与作者的初衷(获取更大范围的特征)相背离了。所以为了解决这个问题,一是使用1x1的卷积,也就是当rate增大以后3x3卷积的退化形式,替代3x3卷积,减少参数个数;另一点就是增加image pooling,可以叫做全局池化,来补充全局特征。具体做法是对每一个通道的像素取平均,之后再上采样到原来的分辨率。
Deeplabv3+
论文名称:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
论文地址:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
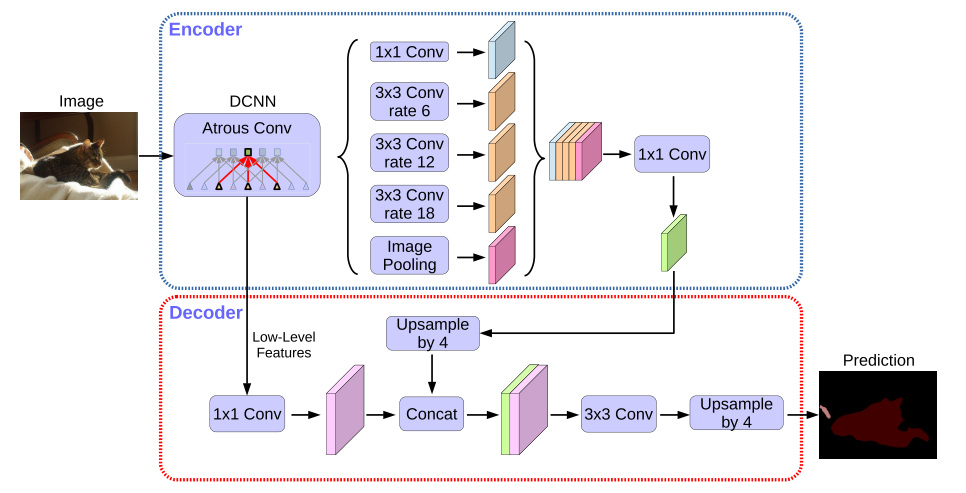
其实Deeplabv3+的改动就不是很多了,首先就是最重要的编码器解码器架构怎么能没有呢?编码器继续使用 DeepLabV3的编码结构,加入了简单的解码器负责边界细化(利用低层的语义特征)。其次将骨干网络升级到了Xception,通过使用深度可分离卷积来精简网络参数,加快推理速度。
编码器解码器结构
具体的编码器结构还是沿用着之前的Deeplabv3的编码结构,解码器也还是很简单的,首先,选取block2中的第二个卷积输出,使用1x1卷积调整通道数到48(减小通道数是为了降低其在最终结果中的比重),然后resize到指定的尺寸,也就是output stride。然后,将ASPP的输出resize到output stride。最后将两部分进行concat操作,在做卷积操作,然后上采样到原来的分辨率,当然还是熟悉的双线性采样,得到最终的分类结果。

Xception
除了编码器解码器结构,Deeplabv3+还探索了将Xception作为主干特征提取网络。通过将空洞卷积与深度可分离卷积进行融合。
Xception最核心的就是用了深度可分离卷积。其思想其实是来自Inception结构,你可以把它看成是Inception的一种特别极端的情况。
Inception认为卷积层里,不同通道之间的关系,还有像素在空间上的关系,这两件事其实是分开的,可以独立处理的。要是把它们分开弄,效果会更好。Inception里面是怎么做的呢?先来个1x1的卷积,把输入处理一下,然后把这些通道分成好几组,对每一组都用不同的3x3卷积去提取特征,最后再把各组的结果拼在一起,就是输出啦。
那深度可分离卷积呢,就是把这种分组取极端。它将每个通道单独算一组!先对输入的每个通道,都用3x3的卷积去处理。等所有通道都处理完了,再将结果concat起来,最后再来个1x1的卷积,调整一下通道的数量,变成我们所需的目标通道数。
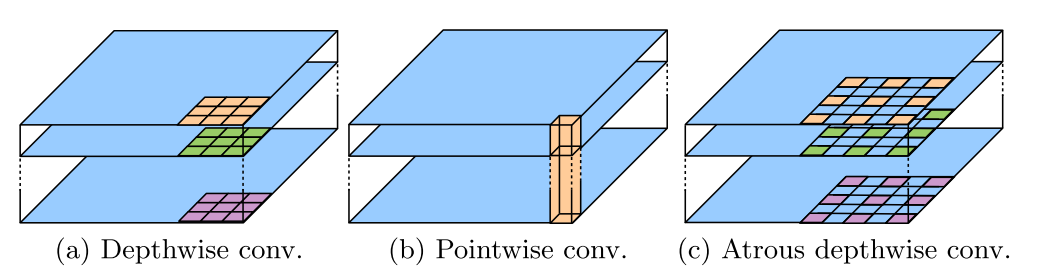
说了这么多,好像还没说到使用depthwise separable convolution的好处。好处也很简单,大幅缩减参数个数。幅度有多大呢?举个简单的栗子,假设输入输出都是128通道,卷积核采用3x3,那么传统卷积的参数个数为:
$3 * 3 * 128 * 128 = 147456 $
而Depthwise separable convolution为:
$3 * 3 * 128 + 1 * 1 * 128 * 128 = 17536 $
相信这样大家就能很直观的理解了吧。
总结对比(按版本)
| 模型 | 主要贡献 | 是否使用 CRF | 是否多尺度 | 是否编码器解码器 |
|---|---|---|---|---|
| V1 | 引入空洞卷积以增大感受野,并结合CRF优化边界 | √ | × | × |
| V2 | 采用ASPP模块进行多尺度特征融合,并使用CRF | √ | √ | × |
| V3 | 对ASPP模块进行改进,提升特征提取能力 | × | √ | × |
| V3+ | 增加了Encoder-Decoder结构,并融合改进的ASPP | × | √ | √ |
模型复现
backbone的搭建
全部的deeplab系列我都将使用resnet进行搭建,resnet的整个搭建过程我写过一篇博客专门讲过,在resnet实战篇那里,如果不了解的我建议先去看看我的那篇博客。我这里就讲不同的地方。
其实就是在搭建resnet的过程中引入了一个参数replace_stride_with_dilation。其类型是布尔型。我们在resnet最后的两个layer中使用空洞卷积。注意这里的一个细节,我们在conv3x3卷积的建立过程,我们令padding也是等于dilation,只有这样,我们最终输出的feature map的shape就不会改变,所以这个大家要知道。
然后再构建layer的过程中,如果dilate是真,即我们需要使用空洞卷积的时候,我们会同时也会令stride为1,这都是为了避免图像分辨率下降。
这基本上与pytroch的resnet源码差不太多了,不过pytorch的resnet源码中resnet18和34是没有加入空洞卷积的,我这里稍微改了下,加入了空洞卷积。
import torch
import torch.nn as nn
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152']
def conv3x3(in_channels, out_channels, stride=1,dilation=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=3,stride=stride,padding=dilation,dilation=dilation,bias=False)
def conv1x1(in_channels, out_channels, stride=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=1,stride=stride,bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self,in_channels,out_channels,stride=1,downsample=None,dilation=1):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(in_channels,out_channels,stride,dilation=dilation)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels,out_channels,dilation=dilation)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
self.stride = stride
def forward(self,x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self,in_channels,out_channels,stride=1,downsample=None,dilation=1):
super(Bottleneck, self).__init__()
self.conv1 = conv1x1(in_channels,out_channels)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = conv3x3(out_channels,out_channels,stride,dilation=dilation)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = conv1x1(out_channels,out_channels*self.expansion)
self.bn3 = nn.BatchNorm2d(out_channels*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self,x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,block,layers,num_classes=1000,zero_init_residual=False,norm_layer=nn.BatchNorm2d,replace_stride_with_dilation=None):
super(ResNet, self).__init__()
self.in_channels = 64
self.dilation = 1
self.conv1 = nn.Conv2d(3,self.in_channels,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1 = norm_layer(self.in_channels)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.layer1 = self._make_layer(block,64,layers[0])
self.layer2 = self._make_layer(block,128,layers[1],stride=2,norm_layer=norm_layer,dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block,256,layers[2],stride=2,norm_layer=norm_layer,dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block,512,layers[3],stride=2,norm_layer=norm_layer,dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(512*block.expansion,num_classes)
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu')
if isinstance(m,nn.BatchNorm2d):
nn.init.constant_(m.weight,1)
nn.init.constant_(m.bias,0)
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight,0)
if isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight,0)
def _make_layer(self,block,in_channels,num_block,stride=1,norm_layer=nn.BatchNorm2d,dilate=False):
pre_dilation = self.dilation
downsample = None
if dilate:
self.dilation*= stride
stride = 1
if stride != 1 or in_channels*block.expansion != self.in_channels :
downsample = nn.Sequential(
conv1x1(self.in_channels,in_channels*block.expansion,stride),
norm_layer(in_channels*block.expansion),
)
layers = []
layers.append(block(self.in_channels,in_channels,stride,downsample,dilation=pre_dilation))
self.in_channels = in_channels*block.expansion
for i in range(1,num_block):
layers.append(block(self.in_channels,in_channels,dilation=self.dilation))
return nn.Sequential(*layers)
def forward(self,x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x1 = self.layer1(x)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
#不需要用到全连接层
# x = self.avgpool(x)
# x = x.view(x.size(0),-1)
# x = self.fc(x)
return x1,x2,x3,x4
def resnet18(**kwargs):
model = ResNet(BasicBlock,[2,2,2,2],replace_stride_with_dilation=[False,True,True],**kwargs)
return model
def resnet34(**kwargs):
model = ResNet(BasicBlock,[3,4,6,4],replace_stride_with_dilation=[False,True,True],**kwargs)
return model
def resnet50(**kwargs):
model = ResNet(Bottleneck,[3,4,6,3],replace_stride_with_dilation=[False,True,True],**kwargs)
return model
def resnet101(**kwargs):
model = ResNet(Bottleneck,[3,4,23,3],replace_stride_with_dilation=[False,True,True],**kwargs)
return model
def resnet152(**kwargs):
model = ResNet(Bottleneck,[3,8,36,3],replace_stride_with_dilation=[False,True,True],**kwargs)
return model
if __name__ == '__main__':
model = resnet18()
print(model)
img = torch.randn(1, 3, 224, 224)
output = model(img)
# print(output.size())
Deeplabv1
Deeplabv1就是比较简单了,原论文是空洞卷积加CRF。我这里没有实现CRF的部分,只有加入空洞卷积的resnet使用进行训练,大家理解原理就好了,因为CRF在v3和v3+中也没有被使用了,所以这里也就没有复现了。
因为加入了resnet18和34,所以其最后输出的通道数是不同的,这里就加入了一个判定,大家可以根据自己电脑情况选择不同的backbone。
from .backbone import *
import torch
import torch.nn as nn
import torch.nn.functional as F
class Deeplabv1(nn.Module):
def __init__(self,backbone='resnet18',num_classes=12):
super(Deeplabv1,self).__init__()
if backbone == 'resnet18' or backbone == 'resnet34':
self.cf_inchannels1 = 512
else:
self.cf_inchannels1 = 2048
self.backbone = get_backbone(backbone)
self.num_classes = num_classes
self.classifier = nn.Conv2d(self.cf_inchannels1, num_classes, kernel_size=1)
def forward(self, x):
_,_,_,x4 = self.backbone(x)
h = self.classifier(x4)
output = F.interpolate(h, size=x.shape[2:], mode='bilinear')
return output
if __name__ == "__main__":
model = Deeplabv1(backbone='resnet101')
model.eval()
image = torch.randn(1, 3, 512, 512)
print(model)
print("input:", image.shape)
print("output:", model(image).shape)
Deeplabv2
Deeplabv2加入了ASPP模块,由一层的feature map上并行多个不同dilation的空洞卷积,所有空洞卷积同步进行,用来获得不同尺度上的感受野,以提升不同尺度的物体分割效果。
注意有个细节获得多个尺度信息后,我们使用的add操作,对应加起来,而不是concat操作哦。
其他的就与Deeplabv1差不多了,同样的,这里我们也没有实现CRF。与原始Deeplabv2并不相同。但是原理是一样的。我们使用resnet做backbone部分。
from .backbone import *
import torch
import torch.nn as nn
import torch.nn.functional as F
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels, dilation=[6,12,18,24]):
super(ASPP, self).__init__()
self.dilation = dilation
self.in_channels = in_channels
self.out_channels = out_channels
self.ASPP = nn.Sequential()
for dilate in dilation:
self.ASPP.append(
nn.Sequential(
nn.Conv2d(in_channels=self.in_channels,out_channels=self.out_channels,padding=dilate,kernel_size=3,stride=1,dilation=dilate),
nn.BatchNorm2d(self.out_channels),
nn.ReLU(inplace=True),
)
)
def forward(self, x):
output = []
for block in self.ASPP:
h = block(x)
output.append(h)
return sum(output)
class Deeplabv2(nn.Module):
def __init__(self,backbone='resnet18', num_classes=12):
super(Deeplabv2, self).__init__()
if backbone == 'resnet18' or backbone == 'resnet34':
self.cf_inchannels = 512
else:
self.cf_inchannels = 2048
self.num_classes = num_classes
self.backbone = get_backbone(backbone)
self.ASPP = ASPP(in_channels=self.cf_inchannels,out_channels=512)
self.classifier = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=self.num_classes, kernel_size=1),
)
def forward(self, x):
_,_,_,x4 = self.backbone(x)
h = self.ASPP(x4)
h = self.classifier(h)
output = F.interpolate(h, size=x.shape[2:], mode='bilinear')
return output
if __name__ == "__main__":
model = Deeplabv2(backbone='resnet50')
model.eval()
image = torch.randn(1, 3, 512, 512)
print(model)
print("input:", image.shape)
print("output:", model(image).shape)
Deeplabv3
除了ASPP外,还加入了image_pooling部分。并且ASPP最后我们将多个feature map是 concat起来的,不是v2的add操作了。
from .backbone import *
import torch
import torch.nn as nn
import torch.nn.functional as F
class image_pooling(nn.Module):
def __init__(self,in_channel,out_channel):
super(image_pooling, self).__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1),
nn.ReLU(inplace=True),
)
def forward(self, x):
h = self.pool(x)
h = self.conv(h)
output = F.interpolate(h, size=x.shape[2:], mode='bilinear')
return output
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels, dilation=[6,12,18]):
super(ASPP, self).__init__()
self.dilation = dilation
self.in_channels = in_channels
self.out_channels = out_channels
self.image_pool = image_pooling(self.in_channels, self.out_channels)
self.ASPP = nn.Sequential()
for dilate in dilation:
self.ASPP.append(
nn.Sequential(
nn.Conv2d(in_channels=self.in_channels,out_channels=self.out_channels,padding=dilate,kernel_size=3,stride=1,dilation=dilate),
nn.BatchNorm2d(self.out_channels),
nn.ReLU(inplace=True),
)
)
def forward(self, x):
output = []
for block in self.ASPP:
h = block(x)
output.append(h)
output.append(self.image_pool(x))
return torch.cat(output, 1)
class Deeplabv3(nn.Module):
def __init__(self,backbone='resnet18', num_classes=12):
super(Deeplabv3, self).__init__()
if backbone == 'resnet18' or backbone == 'resnet34':
self.cf_inchannels = 512
else:
self.cf_inchannels = 2048
self.num_classes = num_classes
self.backbone = get_backbone(backbone)
self.ASPP = ASPP(in_channels=self.cf_inchannels,out_channels=256)
self.classifier = nn.Sequential(
nn.Conv2d(in_channels=256*4, out_channels=self.num_classes, kernel_size=1),
)
def forward(self, x):
_,_,_,x4 = self.backbone(x)
h = self.ASPP(x4)
h = self.classifier(h)
output = F.interpolate(h, size=x.shape[2:], mode='bilinear')
return output
if __name__ == "__main__":
model = Deeplabv3(backbone='resnet50')
model.eval()
image = torch.randn(1, 3, 512, 512)
print(model)
print("input:", image.shape)
print("output:", model(image).shape)
Deeplabv3+
加入了解码器结构,从低层特征获取额外的语义信息。我们使用的是layer2的feature map
from .backbone import *
import torch
import torch.nn as nn
import torch.nn.functional as F
class image_pooling(nn.Module):
def __init__(self, in_channel, out_channel):
super(image_pooling, self).__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1),
nn.ReLU(inplace=True),
)
def forward(self, x):
h = self.pool(x)
h = self.conv(h)
output = F.interpolate(h, size=x.shape[2:], mode='bilinear')
return output
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels, dilation=[6, 12, 18]):
super(ASPP, self).__init__()
self.dilation = dilation
self.in_channels = in_channels
self.out_channels = out_channels
self.image_pool = image_pooling(self.in_channels, self.out_channels)
self.ASPP = nn.Sequential()
for dilate in dilation:
self.ASPP.append(
nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=self.out_channels, padding=dilate,
kernel_size=3, stride=1, dilation=dilate),
nn.BatchNorm2d(self.out_channels),
nn.ReLU(inplace=True),
)
)
def forward(self, x):
output = []
for block in self.ASPP:
h = block(x)
output.append(h)
output.append(self.image_pool(x))
return torch.cat(output, 1)
class Deeplabv3plus(nn.Module):
def __init__(self, backbone='resnet18', num_classes=12):
super(Deeplabv3plus, self).__init__()
if backbone == 'resnet18' or backbone == 'resnet34':
self.cf_inchannels1 = 512
self.cf_inchannels2 = 128
else:
self.cf_inchannels1 = 2048
self.cf_inchannels2 = 512
self.num_classes = num_classes
self.backbone = get_backbone(backbone)
self.ASPP = ASPP(in_channels=self.cf_inchannels1, out_channels=256)
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=256 * 4, out_channels=self.num_classes, kernel_size=1),
nn.BatchNorm2d(self.num_classes),
nn.ReLU(inplace=True)
)
self.classifier = nn.Sequential(
nn.Conv2d(in_channels=self.num_classes+self.cf_inchannels2, out_channels=self.num_classes, kernel_size=1),
nn.BatchNorm2d(self.num_classes),
nn.ReLU(inplace=True)
)
def forward(self, x):
_, x2, _, x4 = self.backbone(x)
h = self.ASPP(x4)
h = self.conv1(h)
h =F.interpolate(h, size=x2.shape[2:], mode='bilinear')
h = self.classifier(torch.cat((h, x2), 1))
output = F.interpolate(h, size=x.shape[2:], mode='bilinear')
return output
if __name__ == "__main__":
model = Deeplabv3plus(backbone='resnet18')
model.eval()
image = torch.randn(1, 3, 512, 512)
print(model)
print("input:", image.shape)
print("output:", model(image).shape)
结语
希望上列所述内容对你有所帮助,如果有错误的地方欢迎大家批评指正!
并且如果可以的话希望大家能够三连鼓励一下,谢谢大家!
如果你觉得讲的还不错想转载,可以直接转载,不过麻烦指出本文来源出处即可,谢谢!
参考资料
本文参考了下列的文章内容,集百家之长汇聚于此,同时包含自己的思考想法
语义分割系列-4 DeepLabV1-V3+(pytorch实现)_deeplabv3家族-CSDN博客
【语义分割专栏】4:deeplab系列原理篇的更多相关文章
- java并发编程系列原理篇--JDK中的通信工具类Semaphore
前言 java多线程之间进行通信时,JDK主要提供了以下几种通信工具类.主要有Semaphore.CountDownLatch.CyclicBarrier.exchanger.Phaser这几个通讯类 ...
- tensorflow语义分割api使用(deeplab训练cityscapes)
安装教程:https://github.com/tensorflow/models/blob/master/research/deeplab/g3doc/installation.md citysca ...
- 语义分割丨DeepLab系列总结「v1、v2、v3、v3+」
花了点时间梳理了一下DeepLab系列的工作,主要关注每篇工作的背景和贡献,理清它们之间的联系,而实验和部分细节并没有过多介绍,请见谅. DeepLabv1 Semantic image segmen ...
- 多篇开源CVPR 2020 语义分割论文
多篇开源CVPR 2020 语义分割论文 前言 1. DynamicRouting:针对语义分割的动态路径选择网络 Learning Dynamic Routing for Semantic Segm ...
- 比较语义分割的几种结构:FCN,UNET,SegNet,PSPNet和Deeplab
简介 语义分割:给图像的每个像素点标注类别.通常认为这个类别与邻近像素类别有关,同时也和这个像素点归属的整体类别有关.利用图像分类的网络结构,可以利用不同层次的特征向量来满足判定需求.现有算法的主要区 ...
- Android 性能监控系列一(原理篇)
欢迎关注微信公众号:BaronTalk,获取更多精彩好文! 一. 前言 性能问题是导致 App 用户流失的罪魁祸首之一,如果用户在使用我们 App 的时候遇到诸如页面卡顿.响应速度慢.发热严重.流量电 ...
- 几篇关于RGBD语义分割文章的总结
最近在调研3D算法方面的工作,整理了几篇多视角学习的文章.还没调研完,先写个大概. 基于RGBD的语义分割的工作重点主要集中在如何将RGB信息和Depth信息融合,主要分为三类:省略. 目录 ...
- DeepLab系列
论文: (DeepLabV1)Semantic image segmentation with deep convolutional nets and fully connected CRFs (De ...
- 语义分割--全卷积网络FCN详解
语义分割--全卷积网络FCN详解 1.FCN概述 CNN做图像分类甚至做目标检测的效果已经被证明并广泛应用,图像语义分割本质上也可以认为是稠密的目标识别(需要预测每个像素点的类别). 传统的基于C ...
- 自动网络搜索(NAS)在语义分割上的应用(二)
前言: 本文将介绍如何基于ProxylessNAS搜索semantic segmentation模型,最终搜索得到的模型结构可在CPU上达到36 fps的测试结果,展示自动网络搜索(NAS)在语义分割 ...
随机推荐
- Python 加上颜色进行输出
博客地址:https://www.cnblogs.com/zylyehuo/ print(f"\033[42m文本内容\033[0m")
- 可视化|MapBoxGL
注册Proton Mail 用户名 密码 人机验证 昵称 设置恢复方法-选择稍后再说-确定 注册MapBoxGL 填写后 Finish creating your account 一开始之前记得选择U ...
- DVWA靶场实战(八)——SQL Injection(Blind)
DVWA靶场实战(八) 八.SQL Injection(Blind): 1.漏洞原理: SQL Injection(Blind)全称为SQL注入之盲注,其实与正常的SQL大同小异,区别在于一般的注入攻 ...
- 【JDBC第5章】批量插入
第5章:批量插入 5.1 批量执行SQL语句 当需要成批插入或者更新记录时,可以采用Java的批量更新机制,这一机制允许多条语句一次性提交给数据库批量处理.通常情况下比单独提交处理更有效率 JDBC的 ...
- 【前端JSP思考】JSP中#{},${}和%{}的区别
JSP中#{},${}和%{}的区别: #{} #{}:对语句进行预编译,此语句解析的是占位符?,可以防止SQL注入, 比如打印出来的语句 select * from table where id=? ...
- 【SpringCloud】SpringCloud Sleuth分布式链路跟踪
SpringCloud Sleuth分布式链路跟踪 概述 为什么会出现这个技术?需要解决哪些问题? 问题:在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后 ...
- STM32F4_HAL_CAN总线注意事项
如果CAN总线没有连接其他设备,即HL是悬空状态,则发送会失败,下图的Error_Handler需要屏蔽,否则会造成系统卡顿,或影响其他功能模块的使用 /* ********************* ...
- unity prefab
1.修改prefab原始资源某组件为enabled或disabled,实例如果起初和原始资源是一样的状态那么修改原始资源会作用到实例上,如果发现不一样那么原始资源的修改不会作用到实例上,而且以后都不会 ...
- Go单元测试与报告
1.编写代码 1)打卡GoLand,新建项目命名为gotest 2)在gotest目录下新建两个go file,如下图所示: 其中CircleArea.go为计算圆面积的待测go程序,代码如下: pa ...
- 聊聊一体机与AI知识库
提供AI咨询+AI项目陪跑服务,有需要回复1 之前写了一篇关于一体机的文章: DeepSeek一体机是个什么鬼 一体机产生的原因是春节期间DeepSeek的火爆带动了一些公司的AI需求,但很多公司如医 ...