Java集合容器面试题
Java常用集合类有哪些?
Collection接口的子接口包括:Set接口和List接口
Map接口的实现类主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap以及Properties等
Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
HashMap与HashTable的区别?
HashMap没有考虑同步,是线程不安全的;HashTable使用了synchronized关键字,是线程安全的;
HashMap允许K/V都为null;后者K/V都不允许为null;
HashMap继承自AbstractMap类;而Hashtable继承自Dictionary类;
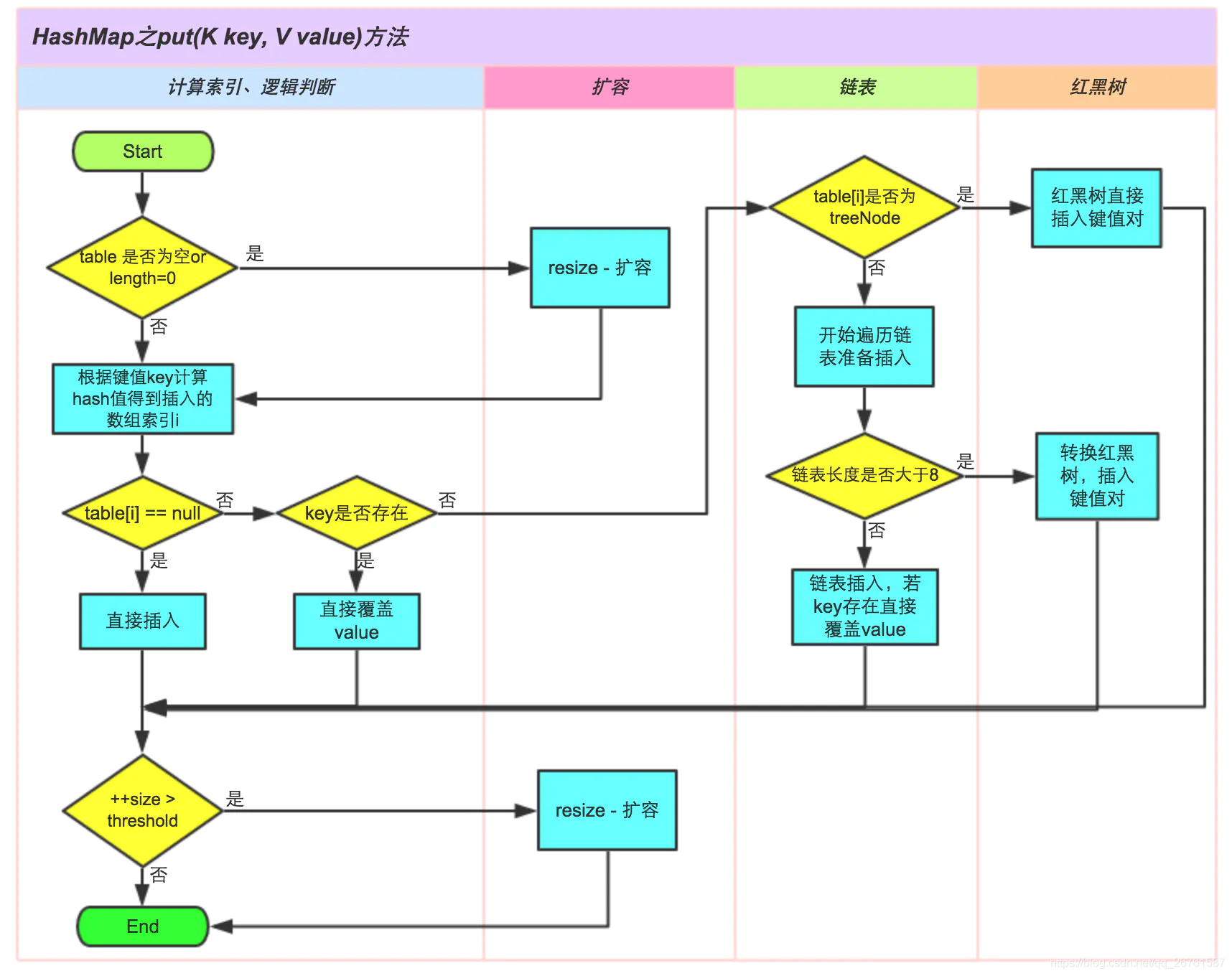
JDK1.8以后HashMap的put方法的具体流程?
当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。
针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题。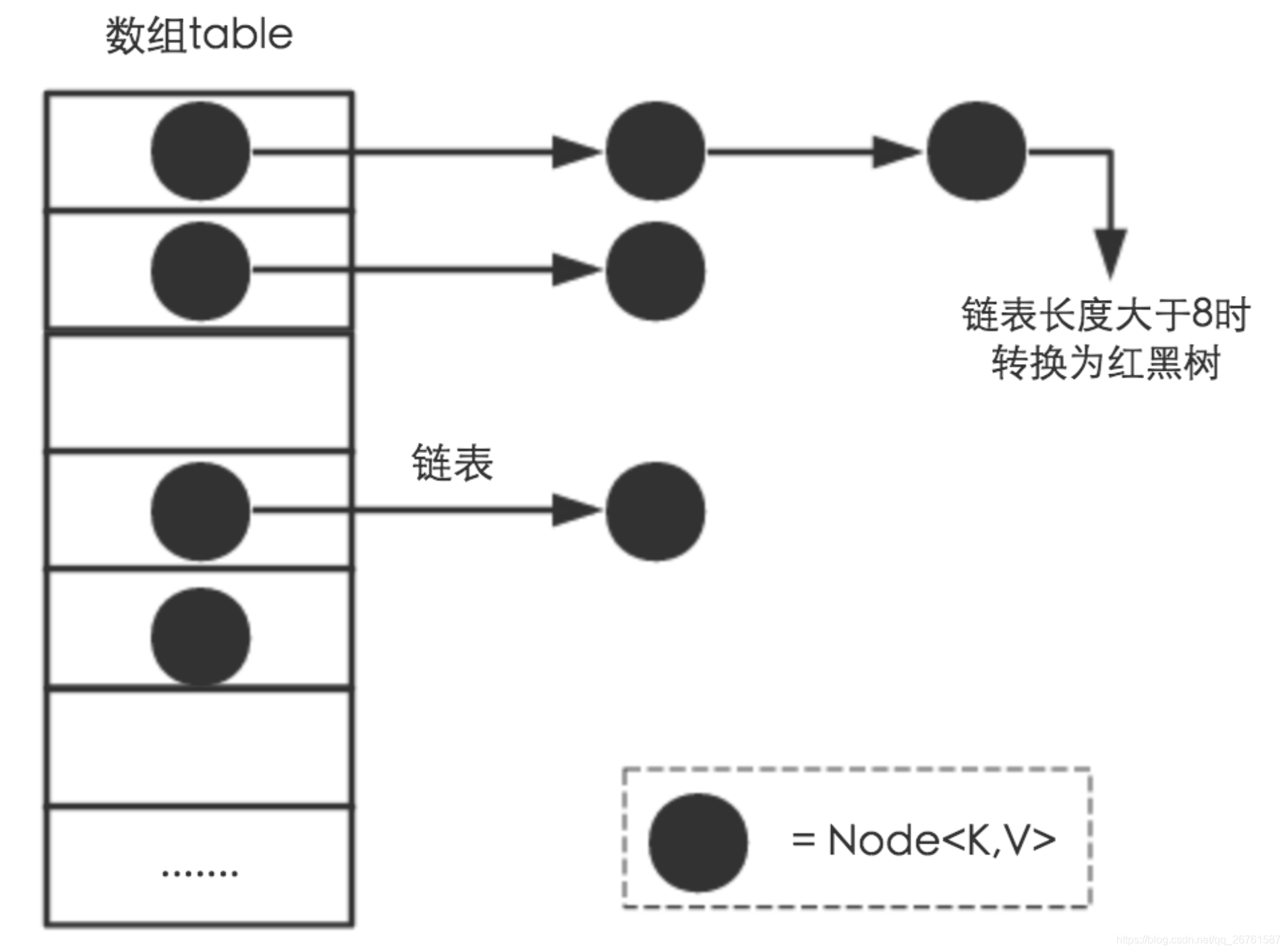
ArrayList、LinkList、Vetor的区别?
List主要有ArrayList、LinkedList与Vector几种实现。
ArrayList
是一个可改变大小的数组.其大小可以动态地增长.内部的元素可以直接通过get与set方法进行访问,因为ArrayList本质上就是一个数组.
LinkedList
是一个双链表,在添加和删除元素时具有比ArrayList更好的性能.但在get与set方面弱于ArrayList.这些都是指数据量很大或者操作很频繁的情况下的对比
Vector
和ArrayList类似,但属于强同步类。如果你的程序本身是线程安全的(thread-safe,没有在多个线程之间共享同一个集合/对象),那么使用ArrayList是更好的选择。
Vector和ArrayList在更多元素添加进来时会请求更大的空间。Vector每次请求其大小的双倍空间,而ArrayList每次对size增长50%.而 LinkedList 还实现了 Queue 接口,该接口比List提供了更多的方法,包offer(),peek(),poll()等. 注意:默认情况下ArrayList的初始容量非常小,所以如果可以预估数据量的话,分配一个较大的初始值属于最佳实践,这样可以减少调整大小的开销。
HashMap、HashTable的区别?
线程安全: HashTable 中的方法是同步的,而HashMap中的方法在默认情况下是非同步的。在多线程并发的环境下,可以直接使用HashTable,但是要使用HashMap的话就要自己增加同步处理了。
继承关系: HashTable是基于陈旧的Dictionary类继承来的。HashMap继承的抽象类AbstractMap实现了Map接口。
允不允许null值:HashTable中,key和value都不允许出现null值,否则会抛出NullPointerException异常。HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。
默认初始容量和扩容机制: HashTable中的hash数组初始大小是11,增加的方式是old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
哈希值的使用不同 : HashTable直接使用对象的hashCode。 HashMap重新计算hash值。
遍历方式的内部实现上不同 : Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。 HashMap 实现Iterator,支持fast-fail,Hashtable的 Iterator 遍历支持fast-fail,用 Enumeration不支持 fast-fail
HashMap 和 ConcurrentHashMap 的区别?
ConcurrentHashMap和HashMap的实现方式不一样,虽然都是使用桶数组实现的,但是还是有区别,ConcurrentHashMap对桶数组进行了分段,而HashMap并没有。
ConcurrentHashMap在每一个分段上都用锁进行了保护。HashMap没有锁机制。所以,前者线程安全的,后者不是线程安全的。
PS:以上区别基于jdk1.8以前的版本。
不同版本JDK的HashMap的实现的区别以及原因
(1)链表元素的插入方式不一样
JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法
因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。
在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
(2)扩容后数据存储位置的计算方式不一样
在JDK1.7的时候是直接用hash值和需要扩容的二进制数进行&(这里就是为什么扩容的时候为啥一定必须是2的多少次幂的原因所在,因为如果只有2的n次幂的情况时最后一位二进制数才一定是1,这样能最大程度减少hash碰撞)(hash值 & length-1)
在JDK1.8的时候直接用了JDK1.7的时候计算的规律,也就是扩容前的原始位置+扩容的大小值=JDK1.8的计算方式,而不再是JDK1.7的那种异或的方法。但是这种方式就相当于只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式。
(3)数据结构不一样
JDK1.7的时候使用的是数组+ 单链表的数据结构。
在JDK1.8及之后时,使用的是数组+链表+红黑树的数据结构(当链表的深度达到8的时候,也就是默认阈值,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(n)变成O(logN)提高了效率)
(4)为什么在JDK1.8中HashMap把链表转化为红黑树的阈值是8?
由于treenodes的大小大约是常规节点的两倍,因此我们仅在容器包含足够的节点以保证使用时才使用它们,当它们变得太小(由于移除或调整大小)时,它们会被转换回普通的node节点,容器中节点分布在hash桶中的频率遵循泊松分布,桶的长度超过8的概率非常非常小。所以作者应该是根据概率统计而选择了8作为阀值(Java注释中的解释)
Hashmap的结构,1.7和1.8有哪些区别
Collection和Collections的区别
Collection:是集合类的上层接口。本身是一个Interface,里面包含了一些集合的基本操作。Collection接口是Set接口和List接口的父接口
Collections:Collections是一个集合框架的帮助类,里面包含一些对集合的排序,搜索以及序列化的操作。
Arrays.asList获得的List使用时需要注意什么
Arrays.asList得到的List它的长度是不能改变的。当你向这个List添加或删除一个元素时(例如 list.add(“d”);)程序就会抛出异常(java.lang.UnsupportedOperationException)。
public static List asList(T… a) {
return new ArrayList<>(a);
}
当你看到这段代码时可能觉得没啥问题啊,不就是返回了一个ArrayList对象吗?问题就出在这里。这个ArrayList不是java.util包下的,而是java.util.Arrays.ArrayList,显然它是Arrays类自己定义的一个内部类!这个内部类没有实现add()、remove()方法,而是直接使用它的父类AbstractList的相应方法。而AbstractList中的add()和remove()是直接抛出java.lang.UnsupportedOperationException异常的!
Fail-fast和Fail-safe
线程不安全的类,并发情况下可能会出现快速失败;线程安全的类,可能会出现安全失败
一个线程在遍历,另一个线程在添加、删除或修改,就会出现并发修改的问题
当遍历时检测到并发修改,就会抛出异常:concurrentmodificationException,这就是快速失败
ArrayList.iterator()返回一个迭代器对象,其中使用一个int类型的expectedModCount记录状态,当发生添加、删除、修改操作时会更改这个值,当遍历时调用next()会检查这个值跟开始遍历时是否一致,发现expectedModCount发生了变化,就意味着有并发修改,这时候就抛出异常iterator.remove()方法没有进行modCount值的检查,并且手动把expectedModCount值修改成了modCount值,这又保证了下一次迭代的正确。
fail-safe是一个概念,并发容器的并发修改不会抛出异常,这和其实现有关。并发容器的iterate方法返回的iterator对象,内部都是保存了该集合对象的一个快照副本,并且没有modCount等数值做检查。这也造成了并发容器的iterator读取的数据是某个时间点的快照版本。你可以并发读取,不会抛出异常,但是不保证你遍历读取的值和当前集合对象的状态是一致的!这就是安全失败的含义。
CopyOnWriteArrayList、ConcurrentSkipListMap
ConcurrentSkipListMap和ConcurrentSkipListSet是TreeMap和TreeSet的有序容器的并发版本
ConcurrentSkipListMap的底层是通过跳表来实现的。跳表(Skiplist)是一个链表,但是通过使用“跳跃式”查找的方式使得插入、读取数据时复杂度变成了O(logn),跳表以空间换时间,是基于链表实现的一种类似“二分”的算法。
CopyOnWriteArrayList使用了一种叫写时复制的方法,当有新元素添加到CopyOnWriteArrayList时,先从原有的数组中拷贝一份出来,然后在新的数组做写操作,写完之后,再将原来的数组引用指向到新数组,合适读多写少的场景
ConcurrentSkipListMap与CopyOnWriteArrayList
Hashmap 什么时候进行扩容呢?
默认大小为16、负载因子为0.75,即超过12就扩容,容量扩大一倍
新建hashmap时设置初始大小,假如有1000个元素,不能设置1000,因为元素数量为750时就会自动扩容,要避免自动扩容,要让元素数量不超过初始容量的0.75
扩容时会重新计算元素在数组中的位置,尽量避免扩容
Hash的公式—> index = HashCode(Key) & (Length - 1)
因为resize的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。会形成环形列表。
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
HashMap的默认初始化长度是多少?为什么?
默认是16,可以是其他2的幂
hash函数可以将任意长度的输入经过变化以后得到固定长度的输出,如果两个元素不相同,但是hash函数的值相同,这两个元素就是一个碰撞
为了减少hash值的碰撞,需要实现一个尽量均匀分布的hash函数,在HashMap中index = key的hashcode值 & length-1
长度16或者其他2的幂时,length - 1的值是所有二进制位全为1,这种情况下index的结果等同于hashcode后几位的值,只要输入的hashcode本身分布均匀,hash算法的结果就是均匀的
所以HashMap的默认长度为16,是为了降低hash碰撞的几率
哈希表如何解决Hash冲突?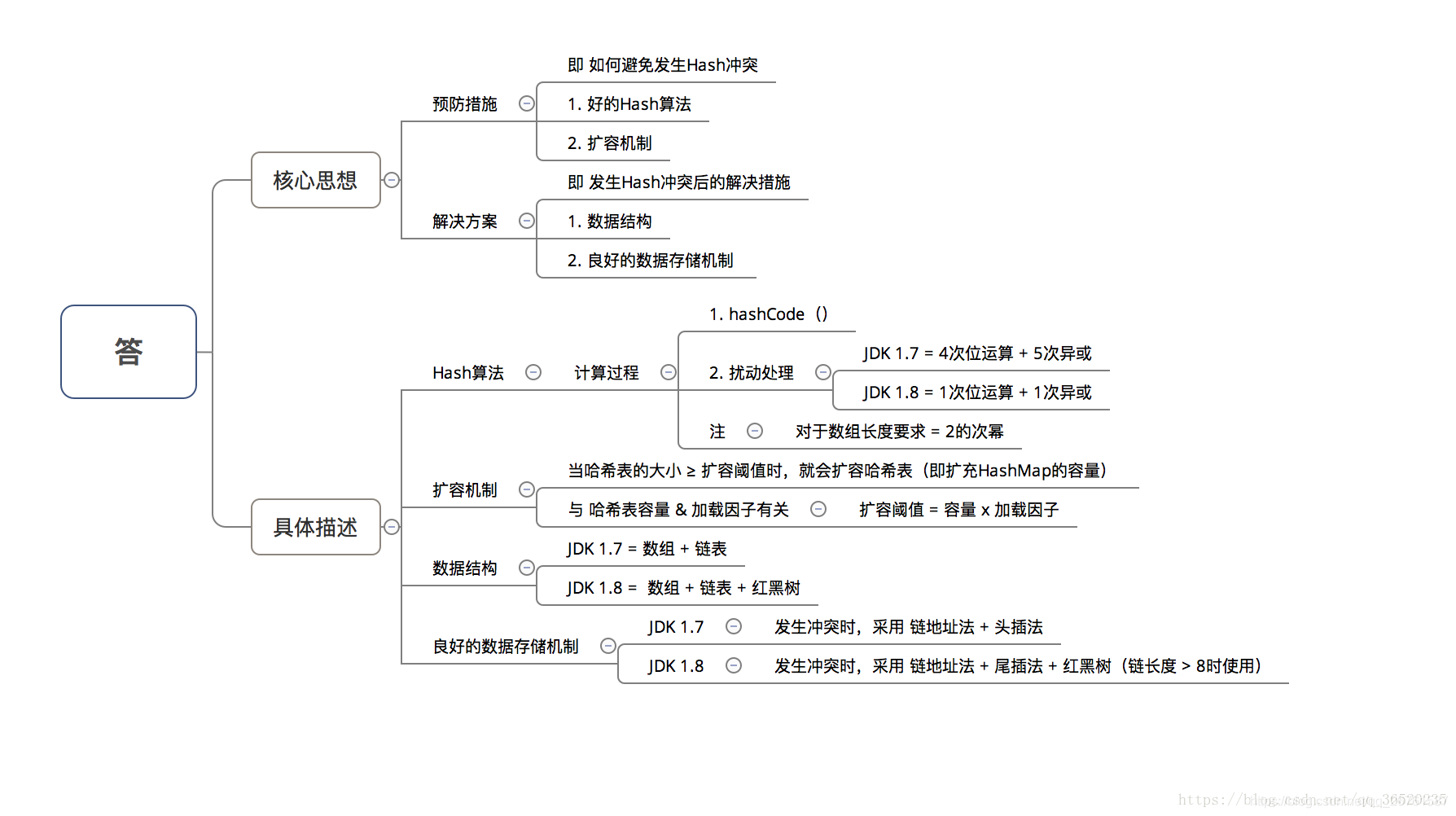
Java集合容器面试题的更多相关文章
- Java集合容器简介
Java集合容器主要有以下几类: 1,内置容器:数组 2,list容器:Vetor,Stack,ArrayList,LinkedList, CopyOnWriteArrayList(1.5),Attr ...
- [转载]Java集合容器简介
Java集合容器主要有以下几类: 1,内置容器:数组 2,list容器:Vetor,Stack,ArrayList,LinkedList, CopyOnWriteArrayList(1.5),Attr ...
- 面霸篇:Java 集合容器大满贯(卷二)
面霸篇,从面试角度作为切入点提升大家的 Java 内功,所谓根基不牢,地动山摇. 码哥在 <Redis 系列>的开篇 Redis 为什么这么快中说过:学习一个技术,通常只接触了零散的技术点 ...
- 50道Java集合经典面试题(收藏版)
前言 来了来了,50道Java集合面试题也来啦~ 已经上传github: https://github.com/whx123/JavaHome 1. Arraylist与LinkedList区别 可以 ...
- Java——(二)Java集合容器
------Java培训.Android培训.iOS培训..Net培训.期待与您交流! ------- 一.基本概念 1)Collection:一个独立元素的序列,这些元素都服从一条或多条规则.Lis ...
- 【面试题】Java集合部分面试题
集合与数组? 数组:(可以存储基本数据类型)是用来存储对象的一种容器,但是数组的长度固定,不适合在对象数量未知的情况下使用 集合:(只能存储对象,对象类型可以不一样)集合的长度可变,可在多数情况下使用 ...
- 编程体系结构(03):Java集合容器
本文源码:GitHub·点这里 || GitEE·点这里 一.集合容器简介 集合容器是Java开发中最基础API模块,通常用来存储运行时动态创建的元素,基本特点如下: 泛型特点,存储任意类型对象: 动 ...
- java 集合 + 常见面试题
1.1. 集合概述 1.1.1. Java 集合概览 从下图可以看出,在 Java 中除了以 Map 结尾的类之外, 其他类都实现了 Collection 接口. 并且,以 Map 结尾的类都实现了 ...
- Java集合容器的深度理解
Java容器里有很多写好的容器API,这使我们很方便的可以存储.操作我们的数据. 下面是我写的容器的特点,一些容器的不同之处,从底层源码解析一下容器实现原理 一.常用的容器目录 上图可以看出,java ...
- Java集合框架面试题
www.cnblogs.com/zhxxcq/archive/2012/03/11/2389611.html 这里的两个图很形象,由于放进图片链接,图片显示不了,所以只能给出该链接. Java集合框架 ...
随机推荐
- Android Hybird架构之整合XwalkView,让你的App内置chromium内核
使用XwalkView的目的无非是为了提升Android4.4以下版本(非chromium内核)的Html5渲染性能,并且能够使得H5页面在众多定制化的ROM上拥有一致的体验. 当然了,App内置Ch ...
- Qml 中的那些坑(七)---ComboBox嵌入Popup时,滚动内容超过其可见区域不会关闭ComboBox弹窗
[写在前面] 最近在写信息提交 ( 表单 ) 的窗口时发现一个奇怪的 BUG: 其代码如下: import QtQuick 2.15 import QtQuick.Controls 2.15 impo ...
- GObject学习笔记(一)类和实例
前言 最近阅读Aravis源码,其中大量运用了GObject,于是打算学习一下. 此系列笔记仅主要面向初学者,不会很深入探讨源码的细节,专注于介绍GObject的基本用法. 此系列笔记参考GObjec ...
- 国密SSL证书,为政务数据安全保驾护航
随着数字化转型的加速,政务信息化建设已成为提升政府服务效率和质量的关键.近期,国家相关部门发布了<互联网政务应用安全管理规定>,为政务应用的安全管理提供了明确的规范和要求.该规定自2024 ...
- P5987 [PA2019] Terytoria / 2023NOIP A层联测13 T3 全球覆盖
P5987 [PA2019] Terytoria / 2023NOIP A层联测13 T3 全球覆盖 题面及数据范围 对于一个点对,可以降维为线段,转化为 1 维的问题. 如图: 我们可以在横着的方向 ...
- C# 开发的数据采集及云端监控系统
前言 推荐C#语言开发的堤坝渗透地质数据采集及云端监控系统.希望本文能够为大家提供有价值的信息和参考. 项目介绍 使用数十个 .NET 客户端控制硬件设备进行工作,采集数据并进行处理. 管理人员通过 ...
- ubuntu安装fish
换新电脑后需要安装fish命令行工具,发现总是apt install不成功,后来挂了代理才成功. 然后我想让这个fish的命令能自动导入我以前写的alias命令(点击这里),可是发现网上人家都说fis ...
- Django3.0
Django3.0 简介 Django 最初被设计用于具有快速开发需求的新闻类站点,目的是要实现简单快捷的网站开发.以下内容简要介绍了如何使用 Django 实现一个数据库驱动的 Web 应用. Dj ...
- Yii2 中配置方法汇总
1.默认框架接收的是x-www-format-unencode格式的数据,如果想要接收text/json格式的数据,会为空,这个时候需要在配置文件中添加对应的配置项 config > main. ...
- navicat之常用操作
日常开发经常使用Navicat进行数据库的管理 快捷键: 快捷键 说明 F6 打开一个命令行界面 Ctrl + q 快速开启一个查询 ctrl + r 运行当前SQL ...