深入LinkedBlockingQueue实现原理
学习BlockingQueue之LinkedBlockingQueue实现原理
一:概念
LinkedBlockingQueue是一个用链表实现的有界阻塞队列。此队列的默认和最大长度为 Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。
与ArrayBlockingQueue的异同:
ArrayBlockingQueue: 必须设置长度容量 底层数组结构 单锁控制
LinkedBlockingQueue:默认Integer最大值 底层链表结构 双锁
二:LinkedBlockingQueue源码实现
不设置容量,默认为Integer的最大值

也支持设置容量

也支持预先将集合设置入队列

两把锁,一个take锁,控制消费者并发,一个put锁,控制生产者并发:


内部维护单向链表结构:

来看一下主要方法:offer与poll
offer方法:
如果e为null或者对列已满,返回false, 然后加锁,其他的生产者会被阻塞,再次判断如果对列里面元素数量小于容量,那么入队,对列的数量也自加,
如果这时对列仍然有空间,会唤醒正在等待的其他生产者,向对列里面放数据。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public boolean offer(E e) { if (e == null) throw new NullPointerException(); final AtomicInteger count = this.count; if (count.get() == capacity) return false; int c = -1; Node<E> node = new Node<E>(e); final ReentrantLock putLock = this.putLock; putLock.lock(); try { if (count.get() < capacity) { enqueue(node); c = count.getAndIncrement(); if (c + 1 < capacity) notFull.signal(); } } finally { putLock.unlock(); } if (c == 0) signalNotEmpty(); return c >= 0; } |
入队方法:
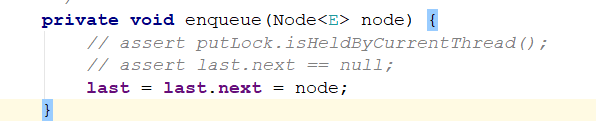
如果是第一次放入数据,效果图:

主要是建立两个连接,让最后一个元素last指向新来的元素,然后将last指针指向新来的。
再来看一下poll方法:取数据
如果对列为空,返回null ,然后加锁,其他想取数据的消费者线程会被阻塞, 如果没有数据释放锁,返回null,对列有数据,则出队,对列自减,
如果出队后对列中还有数据,那么会唤醒正在等待的其他消费者线程来取数据。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public E poll() { final AtomicInteger count = this.count; if (count.get() == 0) return null; E x = null; int c = -1; final ReentrantLock takeLock = this.takeLock; takeLock.lock(); try { if (count.get() > 0) { x = dequeue(); c = count.getAndDecrement(); if (c > 1) notEmpty.signal(); } } finally { takeLock.unlock(); } if (c == capacity) signalNotFull(); return x; } |
出队方法:
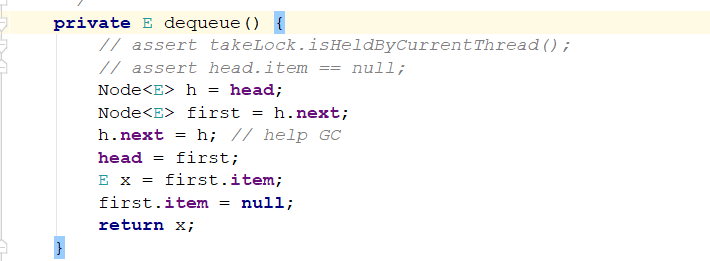
返回first的item元素,这个链表的头结点维护的都是空节点,效果图如下:
出队前:

出队后:

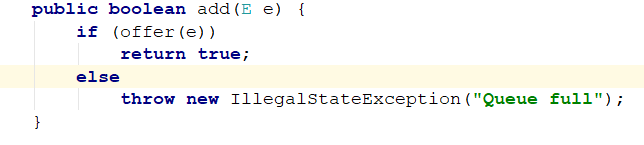
add 和remove:
add方法: 直接使用父类AbstractQueue的方法:
在offer的基础上进行了保证,成功返回true,false的时候返回异常。
remove方法:
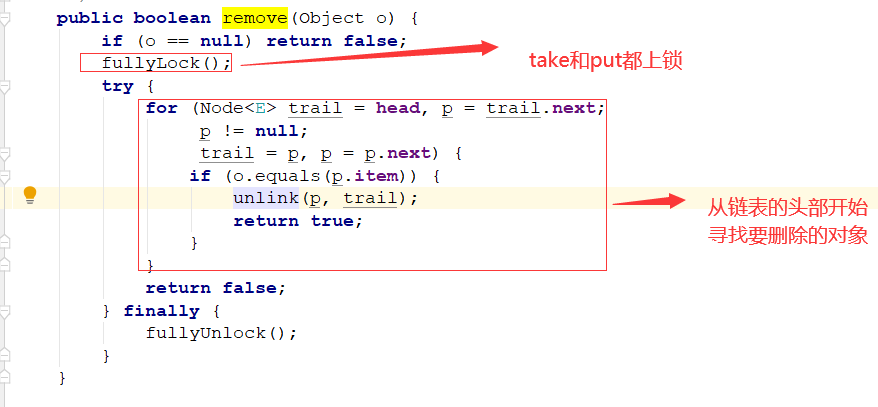
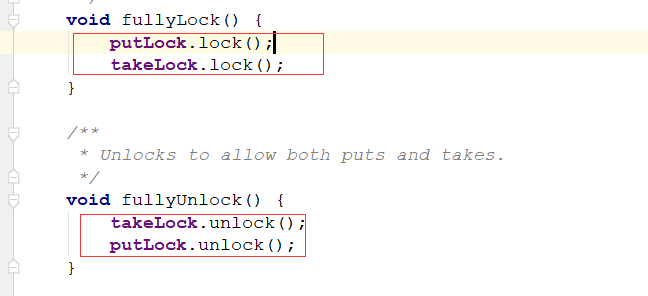
两把锁同时上锁,两把锁同时解锁:
来看一下删除元素的动作:因为数据结构是链表,所以只需要把指向该节点的上一个节点的next变量不指向该节点即可,然后
gc的时候就会把该节点回收掉:
trial.next = p.next 的作用就是让p节点的前一个元素直接指向p的后一个元素,而数组结构就是把该下标置为null object[takeIndex] == null

put和take方法:
put方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public void put(E e) throws InterruptedException { if (e == null) throw new NullPointerException(); // Note: convention in all put/take/etc is to preset local var // holding count negative to indicate failure unless set. int c = -1; Node<E> node = new Node<E>(e); final ReentrantLock putLock = this.putLock; final AtomicInteger count = this.count; putLock.lockInterruptibly(); try { /* * Note that count is used in wait guard even though it is * not protected by lock. This works because count can * only decrease at this point (all other puts are shut * out by lock), and we (or some other waiting put) are * signalled if it ever changes from capacity. Similarly * for all other uses of count in other wait guards. */ while (count.get() == capacity) { notFull.await(); } enqueue(node); c = count.getAndIncrement(); if (c + 1 < capacity) notFull.signal(); } finally { putLock.unlock(); } if (c == 0) signalNotEmpty(); } |
take方法:
take方法的判断逻辑与poll基本相同,唯一区别是,如果对列没有元素,take为阻塞消费者线程,而poll会返回false。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public E take() throws InterruptedException { E x; int c = -1; final AtomicInteger count = this.count; final ReentrantLock takeLock = this.takeLock; takeLock.lockInterruptibly(); try { while (count.get() == 0) { notEmpty.await(); } x = dequeue(); c = count.getAndDecrement(); if (c > 1) notEmpty.signal(); } finally { takeLock.unlock(); } if (c == capacity) signalNotFull(); return x; } |
深入LinkedBlockingQueue实现原理的更多相关文章
- 20.并发容器之ArrayBlockingQueue和LinkedBlockingQueue实现原理详解
1. ArrayBlockingQueue简介 在多线程编程过程中,为了业务解耦和架构设计,经常会使用并发容器用于存储多线程间的共享数据,这样不仅可以保证线程安全,还可以简化各个线程操作.例如在“生产 ...
- 理解线程池到走进dubbo源码
引言 合理利用线程池能够带来三个好处. 第一:降低资源消耗.通过重复利用已创建的线程降低线程创建和销毁造成的消耗. 第二:提高响应速度.当任务到达时,任务可以不需要等到线程创建就能立即执行. ...
- 学习笔记 07 --- JUC集合
学习笔记 07 --- JUC集合 在讲JUC集合之前我们先总结一下Java的集合框架,主要包含Collection集合和Map类.Collection集合又能够划分为LIst和Set. 1. Lis ...
- BlockingQueue 解析
阻塞队列与普通队列的区别在于,当队列是空的时,从队列中获取元素的操作将会被阻塞,或者当队列是满时,往队列里添加元素的操作会被阻塞.试图从空的阻塞队列中获取元素的线程将会被阻塞,直到其他的线程往空的队列 ...
- BlockingQueue深入解析-BlockingQueue看这一篇就够了
本篇将详细介绍BlockingQueue,以下是涉及的主要内容: BlockingQueue的核心方法 阻塞队列的成员的概要介绍 详细介绍DelayQueue.ArrayBlockingQueue.L ...
- 008 BlockingQueue理解
原文https://www.cnblogs.com/WangHaiMing/p/8798709.html 本篇将详细介绍BlockingQueue,以下是涉及的主要内容: BlockingQueue的 ...
- 生产者消费者模型Java实现
生产者消费者模型 生产者消费者模型可以描述为: ①生产者持续生产,直到仓库放满产品,则停止生产进入等待状态:仓库不满后继续生产: ②消费者持续消费,直到仓库空,则停止消费进入等待状态:仓库不空后,继续 ...
- LinkedBlockingQueue出入队实现原理
类图概述 由类图可以看出,L是单向链表实现的,有两个ReentrantLock实例用来控制元素入队和出队的原子性,takeLock用来控制只有一个线程可以从队头获取元素,putLock控制只有一个线程 ...
- 分布式开放消息系统(RocketMQ)的原理与实践
分布式消息系统作为实现分布式系统可扩展.可伸缩性的关键组件,需要具有高吞吐量.高可用等特点.而谈到消息系统的设计,就回避不了两个问题: 消息的顺序问题 消息的重复问题 RocketMQ作为阿里开源的一 ...
- Java并发集合的实现原理
本文简要介绍Java并发编程方面常用的类和集合,并介绍下其实现原理. AtomicInteger 可以用原子方式更新int值.类 AtomicBoolean.AtomicInteger.AtomicL ...
随机推荐
- 4. jenkins的配置
Maven安装和配置 在Jenkins集成服务器上,我们需要安装Maven来编译和打包项目. 安装Maven 先上传Maven软件到192.168.66.101 tar -xzf apache-m ...
- 数据库研发人员必看的MySQL 8.0新特性
本文汇总了MySQL8.0 面向开发的新特性,总共有12个新特性,有想快速了解8.0新特性的朋友,可以看一下哈文章目录:1.公用表达式支持-CTE2.窗口函数3.表达式作为默认值:4.CHECK支持5 ...
- 项目监控之sentry
github: https://github.com/getsentry/sentry 1.什么是sentry? 当我们完成一个业务系统的上线时,总是要观察线上的运行情况,对于每一个项目,我们都没办法 ...
- 2022 Hangzhou Normal U Summer Trials
Subarrays 给定一个长度为n的由正整数组成的序列,请你输出该序列中子段和能被\(k\)整除的所有符合要求的子段数量 题解:组合计数 + 前缀和 + 思维 \[sum[l,r]\ \ mod\ ...
- 开源 - Ideal库 - Excel帮助类,ExcelHelper实现(四)
书接上回,前面章节已经实现Excel帮助类的第一步TableHeper的对象集合与DataTable相互转换功能,今天实现进入其第二步的核心功能ExcelHelper实现. 01.接口设计 下面我们根 ...
- vue表格轮播插件
1.前言 需求:制作大屏看板时,经常要展示表格数据,通常一页时放不下的,表格需要自动滚动,并维持表头固定 为何自己封装:网上的滚动组件有2类,一种传入json数据进行滚动(DataV),优点是可以做到 ...
- Vue 模版解析
1.大括号表达式 (1)在MVVM()中接收并保存配置对象 (2)调用Compile编译函数,将el和vm传入 function MVVM (option) { this.$option = opti ...
- HTML5 新的语义标签
1.常用的语义标签 意义:语义标签便于阅读代码,也便于搜索引擎解析文档结构与内容 标签 含义 article 定义页面独立的内容区域 aside 定义侧边栏内容 header 定义了文档的头部区域 s ...
- 反编译wx小程序遇到的问题
怎么反编译就不说了,有很多文章,推荐两个 http://t.csdnimg.cn/DrvBZ http://t.csdnimg.cn/NOEys 下面开始说问题 _typeof3 is not a f ...
- GraphQL Part I: hello, world.
GraphQL with ASP.NET Core (Part- I : Hello World) 厌倦了 REST? 让我们谈一下 GraphQL, GraphQL 提供声明式的方式从服务器获取数据 ...