Flink-cdc同步mysql到iceberg丢失数据排查
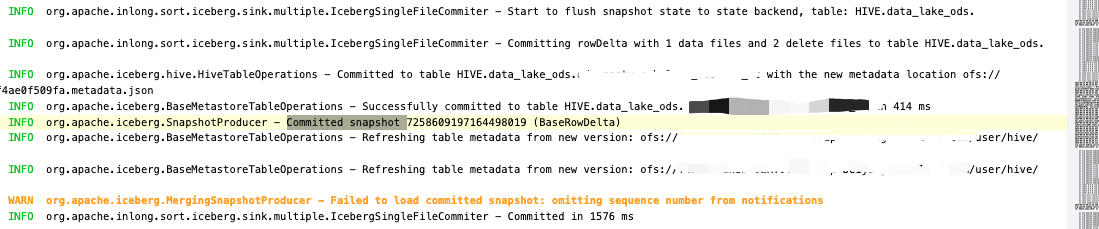
Emit iceberg write result dataFiles: [
GenericDataFile{content=data, file_path=ofs://sss/test1235/data/00000-0-8a53aa17-c767-47bd-b865-32e13d54bd8e-02520.parquet, file_format=PARQUET, spec_id=0, partition=PartitionData{}, record_count=592, file_size_in_bytes=1067447, column_sizes={1=2113, 2=2077, 3=2393, 4=3018, 5=1667, 6=166, 7=95, 8=1412, 9=1121, 10=163, 11=1409}, value_counts={1=592, 2=592, 3=592, 4=592, 5=592, 6=592, 7=592, 8=592, 9=592, 10=592, 11=592}, null_value_counts={1=0, 2=0, 3=0, 4=0, 5=0, 6=0, 7=0, 8=0, 9=0, 10=0, 11=0}, nan_value_counts={}, lower_bounds=org.apache.iceberg.SerializableByteBufferMap@fcc2b49e, upper_bounds=org.apache.iceberg.SerializableByteBufferMap@1b557080, key_metadata=null, split_offsets=[4], equality_ids=null, sort_order_id=0}],
result.deleteFiles [GenericDeleteFile{content=equality_deletes, file_path=ofs://sss/test1235/data/00000-0-8a53aa17-c767-47bd-b865-32e13d54bd8e-02521.parquet, file_format=PARQUET, spec_id=0, partition=PartitionData{}, record_count=534, file_size_in_bytes=1050981, column_sizes={1=1931}, value_counts={1=534}, null_value_counts={1=0}, nan_value_counts={}, lower_bounds=org.apache.iceberg.SerializableByteBufferMap@471b5f22, upper_bounds=org.apache.iceberg.SerializableByteBufferMap@9fc9501c, key_metadata=null, split_offsets=null, equality_ids=[1], sort_order_id=0},
GenericDeleteFile{content=position_deletes, file_path=ofs://sss/test1235/data/00000-0-8a53aa17-c767-47bd-b865-32e13d54bd8e-02522.parquet, file_format=PARQUET, spec_id=0, partition=PartitionData{}, record_count=58, file_size_in_bytes=2004, column_sizes={2147483546=239, 2147483545=153}, value_counts={2147483546=58, 2147483545=58}, null_value_counts={2147483546=0, 2147483545=0}, nan_value_counts={}, lower_bounds=org.apache.iceberg.SerializableByteBufferMap@c337bae4, upper_bounds=org.apache.iceberg.SerializableByteBufferMap@c337baa5, key_metadata=null, split_offsets=null, equality_ids=null, sort_order_id=null}] 
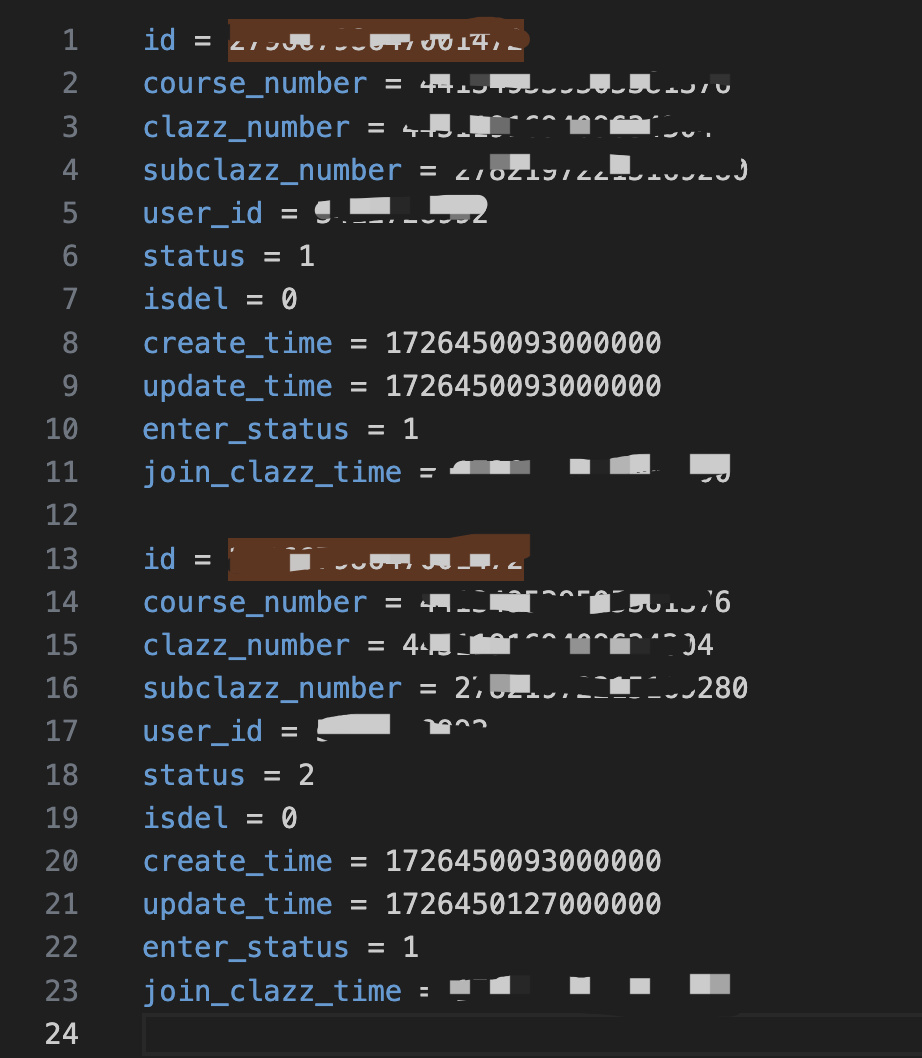

2024-09-16 09:25:53.026 [Source: MySQL-CDC- -> Calc(select=[id, course_number, clazz_number, subclazz_number, user_id, CAST(status) AS status, CASE(isdel IS NOT NULL, CASE(isdel, 1, 0), null:INTEGER) AS isdel, CAST(create_time) AS create_time, CAST(update_time) AS update_time, enter_status, CAST(join_clazz_time) AS join_clazz_time]) -> NotNullEnforcer(fields=[id]) (1/1)#0] INFO
com.ververica.cdc.connectors.mysql.source.reader.MySqlSourceReader - Binlog offset on checkpoint 859: {transaction_id=null, ts_sec=1726449952, file=mysql-bin.022296, pos=459680089, kind=SPECIFIC, gtids=15fad577-6501-11ea-b6b2-b8599fae21fa:9456479883-9480246523, row=1, event=2, server_id=31681949}
2024-09-16 09:30:53.037 [Source: MySQL-CDC- -> Calc(select=[id, course_number, clazz_number, subclazz_number, user_id, CAST(status) AS status, CASE(isdel IS NOT NULL, CASE(isdel, 1, 0), null:INTEGER) AS isdel, CAST(create_time) AS create_time, CAST(update_time) AS update_time, enter_status, CAST(join_clazz_time) AS join_clazz_time]) -> NotNullEnforcer(fields=[id]) (1/1)#0] INFO
com.ververica.cdc.connectors.mysql.source.reader.MySqlSourceReader - Binlog offset on checkpoint 860: {transaction_id=null, ts_sec=1726450252, file=mysql-bin.022296, pos=474797741, kind=SPECIFIC, gtids=15fad577-6501-11ea-b6b2-b8599fae21fa:9456479883-9480269403, row=1, event=2, server_id=31681949}

Flink-cdc同步mysql到iceberg丢失数据排查的更多相关文章
- Elasticsearch的快速使用——Spring Boot使用Elastcisearch, 并且使用Logstash同步mysql和Elasticsearch的数据
我主要是给出一些方向,很多地方没有详细说明.当时我学习的时候一直不知道怎么着手,花时间找入口点上比较多,你们可以直接顺着方向去找资源学习. 如果不是Spring Boot项目,那么根据Elastics ...
- MySQL不会丢失数据的秘密,就藏在它的 7种日志里
本文收录在 GitHub 地址 https://github.com/chengxy-nds/Springboot-Notebook 进入正题前先简单看看MySQL的逻辑架构,相信我用的着. MySQ ...
- Canal:同步mysql增量数据工具,一篇详解核心知识点
老刘是一名即将找工作的研二学生,写博客一方面是总结大数据开发的知识点,一方面是希望能够帮助伙伴让自学从此不求人.由于老刘是自学大数据开发,博客中肯定会存在一些不足,还希望大家能够批评指正,让我们一起进 ...
- 电商网站垮IDC数据备份,MySql主从同步,图片及其它数据文件的同步
原文网址:http://www.bzfshop.net/article/180.html 对一个电子商务网站而言,最宝贵的资源就是数据.服务器是很廉价的东西,即使烧了好几个也问题不大,但是用户数据如果 ...
- 基于 MySQL Binlog 的 Elasticsearch 数据同步实践 原
一.背景 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品.订单等数据的多维度检索. 使用 Elasticsearch 存储业务数据可以 ...
- 基于MySQL Binlog的Elasticsearch数据同步实践
一.为什么要做 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品.订单等数据的多维度检索. 使用 Elasticsearch 存储业务数 ...
- 通过Gearman实现MySQL到Redis的数据同步
对于变化频率非常快的数据来说,如果还选择传统的静态缓存方式(Memocached.File System等)展示数据,可能在缓存的存取上会有很大的开销,并不能很好的满足需要,而Redis这样基于内存的 ...
- 快速同步mysql数据到redis中
MYSQL快速同步数据到Redis 举例场景:存储游戏玩家的任务数据,游戏服务器启动时将mysql中玩家的数据同步到redis中. 从MySQL中将数据导入到Redis的Hash结构中.当然,最直接的 ...
- Gearman + Nodejs + MySQL UDF异步实现 MySQL 到 Redis 的数据同步
[TOC] 1, 环境 CentOS, MySQL, Redis, Nodejs 2, Redis简介 Redis是一个开源的K-V内存数据库,它的key可以是string/set/hash/list ...
- TiDB 作为 MySQL Slave 实现实时数据同步
由于 TiDB 本身兼容绝大多数的 MySQL 语法,所以对于绝大多数业务来说,最安全的切换数据库方式就是将 TiDB 作为现有数据库的从库接在主 MySQL 库的后方,这样对业务方实现完全没有侵入性 ...
随机推荐
- Golang之学习资源参考
使用golang开发也有一段时间,在此总结一些自己从0入门到掌握所涉及一些资源,希望可以帮助其他人 [初级] 基础语法练习: https://gobyexample.com/ [中级] 1.gola ...
- elastic 7.15 集群搭建
准备三台ES 7.15 关于系统配可以参考之前的文章. https://www.cnblogs.com/yg_zhang/p/10214196.html 这里写一下 的集群配置.这里和之前配置有所不同 ...
- HarmonyOS Next 集成支付宝SDK后无法在模拟器上安装调试的问题
之前使用模拟器调试都正常,在集成支付宝SDK后,同事说在模拟器上无法安装调试,因为真机资源不够,模拟器不能用实在耽误事,所以就花了点时间研究一下. 报错原因 官方文档的解释 根据文档的说明,应该是cp ...
- Pytorch 手写数字识别 深度学习基础分享
本篇是一次内部分享,给项目开发的同事分享什么是深度学习.用最简单的手写数字识别做例子,讲解了大概的原理. 手写数字识别 展示首先数字识别项目的使用.项目实现过程: 训练出模型 准备html手写板 fl ...
- 『玩转Streamlit』--片段Fragments
在 Streamlit 应用开发中,Fragments组件是一种用于更精细地控制页面元素更新和显示顺序的工具. 它允许开发者将内容分解成多个小的片段,这些片段可以按照特定的顺序或者逻辑进行更新,而不是 ...
- Linux清理内存,清理储存
因为工作中项目部署服务器后更新迭代或者服务器使用时间长后会出现内存/储存爆满,所以整合了一下,方便以后使用: 清理虚拟内存 查看内存 free -h 清理缓存 输入命令释放内存 0 – 不释放 1 – ...
- C#调用Python代码的方式(二),以PaddleOCR-GUI为例
前言 前面介绍了在C#中使用Progress类调用Python脚本的方法,但是这种方法在需要频繁调用并且需要进行数据交互的场景效果并不好,因此今天分享的是C#调用Python代码的方式(二):使用py ...
- The Financial-Grade Digital Infrastructure
01 Product Introduction The Financial-Grade Digital Infrastructure is a digitally-enabled foun ...
- Qt编写RK3588视频播放器/支持RKMPP硬解/支持各种视音频文件和视频流/海康大华视频监控
一.前言 用ffmpeg做硬解码开发,参考自带的示例hw_decode.c即可,里面提供了通用的dxva2/d3d11va/vaapi这种系统层面封装的硬解码,也就是无需区分用的何种显卡,操作系统自动 ...
- Qt编写地图综合应用48-地球模式、三维模式、地铁模式
一.前言 百度地图本身提供了普通模式.地球模式.三维模式.地铁模式等好多种,普通模式是最常用的默认的,就是那个街道图和卫星图的,而地球模式和三维模式是最近几年才新增加的,为了迎合现在越来越多的用户的需 ...