深入剖析开源AI阅读器项目Saga Reader基于大模型的文本转换与富文本渲染优化方案
引言
AI阅读器作为一种新型的内容消费工具,正在改变人们获取和处理信息的方式。本文将介绍Saga Reader项目中如何利用大型语言模型(LLM)进行网页内容抓取、智能优化和富文本渲染,特别是如何通过精心设计的提示词(prompt)引导LLM生成样式丰富的HTML内容,提升用户阅读体验。
关于Saga Reader
基于Tauri开发的著名开源AI驱动的智库式阅读器(前端部分使用Web框架),能根据用户指定的主题和偏好关键词自动从互联网上检索信息。它使用云端或本地大型模型进行总结和提供指导,并包括一个AI驱动的互动阅读伴读功能,你可以与AI讨论和交换阅读内容的想法。
Github - Saga Reader,完全开源,可外部服务0依赖,可纯本地电脑运行的AI项目。欢迎大家关注分享。码农开源不易,各位好人路过请给个小星星Star。
核心技术栈:Rust + Tauri(跨平台)+ Svelte(前端)+ LLM(大语言模型集成),支持本地 / 云端双模式
关键词:端智能,边缘大模型;Tauri 2.0;桌面端安装包 < 5MB,内存占用 < 20MB。
运行截图

系统架构概述
Saga Reader的内容处理流程主要包含以下几个关键步骤:
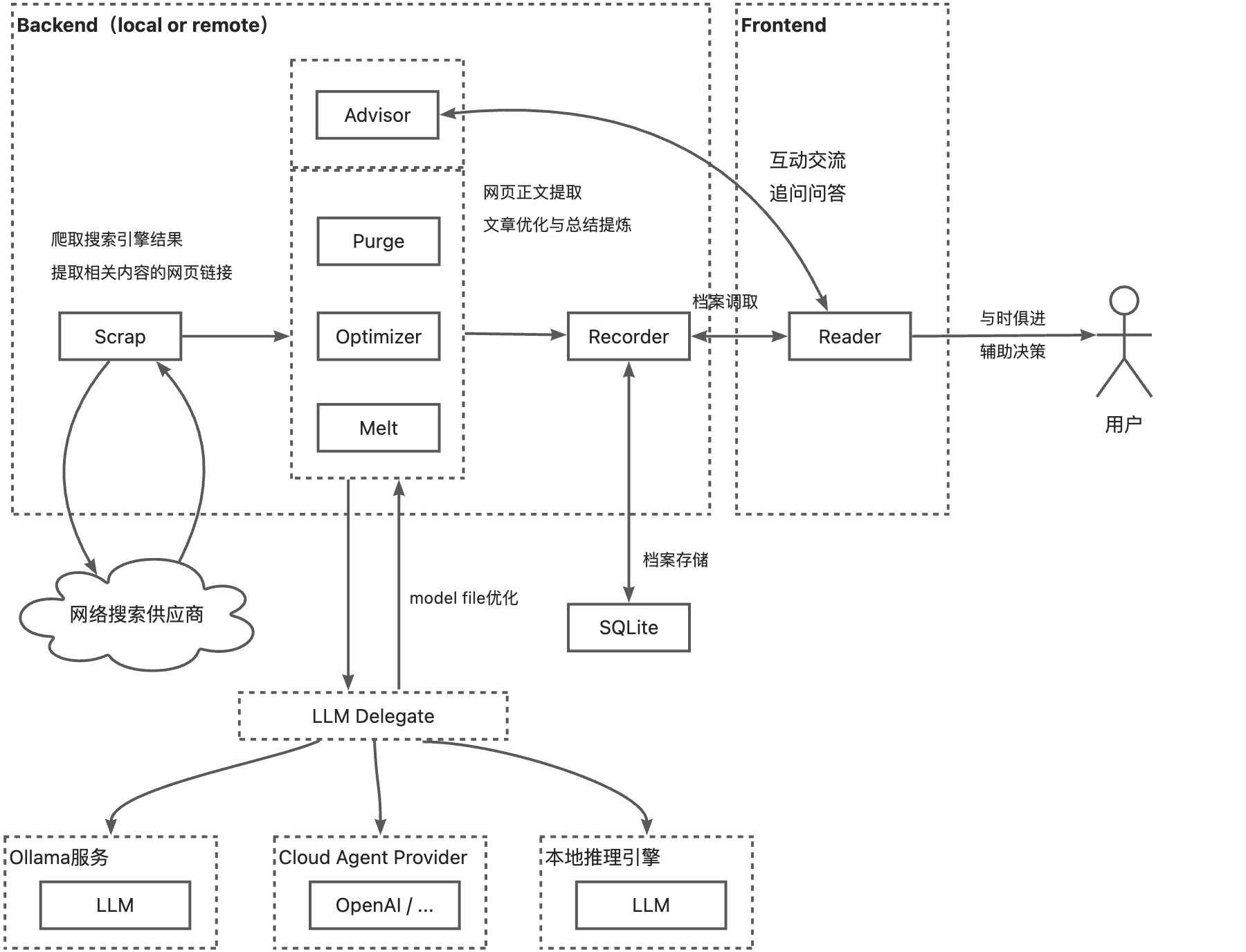
- 内容抓取:通过爬虫或RSS获取原始网页内容
- 内容净化(Purge):清理原始HTML中的无关元素
- 内容优化(Optimize):将净化后的内容转换为富文本格式
- 内容摘要(Melt):生成文章摘要
- 内容渲染:在前端展示优化后的内容
这些步骤形成了一个完整的内容处理管道,每个环节都由专门的处理器负责。
基于LLM的文章处理器
在Saga Reader中,文章处理的核心是ArticleLLMProcessor类,它实现了IArticleProcessor接口,负责调用LLM进行内容转换:
/// 基于LLM的文章处理器。
pub struct ArticleLLMProcessor {
/// Agent化的生成式服务实例。
agent: CompletionAgent,
/// 用于与Agent交互的user prompt。
user_prompt_command: String,
}
impl IArticleProcessor for ArticleLLMProcessor {
async fn process(&self, input: &Article) -> anyhow::Result<Article> {
let mut output = input.clone();
let content = output.content.as_ref().unwrap();
let mut chat = format!(r#"## 原内容\n"{}"\n"#, content);
chat.push_str(self.user_prompt_command.as_str());
let content = self.agent.completion(chat).await?;
output.content.replace(content);
Ok(output)
}
}
这个处理器的工作方式很直观:它接收一篇文章,将文章内容与预设的提示词组合,发送给LLM,然后用LLM的输出替换原始内容。
优化器(Optimizer)的实现
在内容处理管道中,优化器(Optimizer)是将净化后的内容转换为富文本格式的关键组件:
pub struct Optimizer {}
impl IPresetArticleLLMProcessor for Optimizer {
fn new_processor(llm_section: LLMSection) -> anyhow::Result<ArticleLLMProcessor> {
let options = AITargetOption {
temperature: Some(0.1),
..Default::default()
};
ArticleLLMProcessor::new(llm_section, SYSTEM_PROMPT.into(), USER_PROMPT_COMMAND_OPTIMIZE.into(), options)
}
}
优化器使用较低的temperature值(0.1),这有助于生成更加确定性的输出,确保HTML结构的一致性和稳定性。
从Markdown到富HTML的转变
最近的一项重要升级是将LLM的输出从简单的Markdown转变为样式丰富的HTML。这一转变的核心在于系统提示词(System Prompt)的设计。
系统提示词设计
新的系统提示词将LLM定位为"专业内容设计师",要求它生成"视觉现代化的HTML电子邮件片段":
You are to act as a professional Content Designer. Your task is to convert the provided article into **visually modern HTML email snippets** that render well in modern email clients like Hotmail.
Few-shot示例约束
提示词中包含了多种HTML组件的模板,作为few-shot示例,引导LLM按照特定的样式生成内容:
- 标准段落:用于介绍、结论和过渡文本
- 要点列表:用于组织多个核心观点
- 强调文本:用于突出关键词或短语
- 引用块:用于突出重要观点或原文引用
- 图片块:用于嵌入文章中的图片
例如,要点列表的模板如下:
<ul style="margin:20px 0; padding-left:0; list-style-type:none;">
<li style="position:relative; margin-bottom:12px; padding-left:28px; font-family:'Google Sans',Roboto,Arial,sans-serif; font-size:15px; line-height:1.6" class="text-surface-700-300">
<span class="preset-filled-primary-500" style="position:absolute; left:0; top:0; width:18px; height:18px; border-radius:50%; color:white; text-align:center; line-height:18px; font-size:12px;">1</span>
Description of the first key point
</li>
</ul>
输出要求
提示词还详细规定了输出的要求,包括:
- 美观优雅的设计,和谐的配色方案
- 一致的视觉风格
- 将Markdown图片链接转换为HTML img标签
- 使用多种视觉元素增强可读性
- 移除与正文无关的操作性信息
- 翻译为中文
- 使用过渡文本连接各个组件
- 适当引用重要的原文片段
- 使用高亮样式标记关键点
前端渲染实现
在前端,ArticleRenderWidget.svelte组件负责渲染优化后的内容:
<script lang="ts">
/** eslint-disable svelte/no-at-html-tags */
import type { ArticleRenderProps, ArticleRenderType } from './types';
import Markdown from './Markdown.svelte';
import { removeCodeBlockWrapper } from '$lib/utils/text';
import { featuresApi } from '$lib/hybrid-apis/feed/impl';
import { onMount } from 'svelte';
const { value }: ArticleRenderProps = $props();
const purgedHtml = $derived(removeCodeBlockWrapper(value));
const renderType: ArticleRenderType = $derived(purgedHtml[0] === '<' ? 'html' : 'markdown');
let htmlContainer: HTMLDivElement | null = $state(null);
onMount(() => {
if (!htmlContainer) return;
const anchorClickInterceptor = (event: MouseEvent) => {
// 检查点击的元素是否是一个链接
const target = event.target as HTMLElement;
if (target?.tagName === 'A') {
// 阻止默认的链接跳转行为
event.preventDefault();
// 获取链接的 href 属性
const url = (target as HTMLAnchorElement).href;
// 调用特定函数来处理链接
featuresApi.open_article_external(url);
}
};
(htmlContainer as HTMLDivElement).addEventListener('click', anchorClickInterceptor);
return () => {
(htmlContainer as HTMLDivElement).removeEventListener('click', anchorClickInterceptor);
};
});
</script>
{#if renderType === 'html'}
<div bind:this={htmlContainer} class="p-6 preset-filled-surface-50-950">{@html purgedHtml}</div>
{:else}
<Markdown {value} />
{/if}
该组件能够智能判断内容类型,对HTML和Markdown分别采用不同的渲染方式:
- 对于HTML内容,直接使用Svelte的
{@html}指令渲染 - 对于Markdown内容,使用
Markdown.svelte组件渲染
此外,组件还实现了链接点击拦截,确保外部链接在适当的环境中打开。
内容处理流水线
在FeaturesAPIImpl中,我们可以看到完整的内容处理流水线:
async fn process_article_pipelines(
&self,
article: &mut Article,
purge: &ArticleLLMProcessor,
optimizer: &ArticleLLMProcessor,
melt: &ArticleLLMProcessor,
) -> anyhow::Result<(Article, Article, Article)> {
let out_purged_article = purge.process(article).await?;
info!(
"article purged, title = {}, source_link = {}, optimizing",
article.title, article.source_link
);
let out_optimized_article = optimizer.process(&out_purged_article).await?;
info!(
"purged article optimized, title = {}, melting",
out_purged_article.title
);
if let Some(optimized_content) = out_optimized_article.content.clone() {
if optimized_content.contains("QINO-AGENTIC-EXECUTION-FAILURE") {
return Err(anyhow::Error::msg("QINO-AGENTIC-EXECUTION-FAILURE"));
}
}
let out_melted_article = melt.process(&out_optimized_article).await?;
info!(
"optimized article melted, title = {}, recording",
out_melted_article.title
);
Ok((
out_purged_article,
out_optimized_article,
out_melted_article,
))
}
这个方法依次调用三个处理器:
purge:清理原始HTMLoptimizer:将净化后的内容转换为富文本melt:生成文章摘要
处理完成后,返回三个版本的文章,分别对应处理流程的三个阶段。
技术亮点与创新
1. 基于Few-shot的HTML样式约束
通过在系统提示词中提供HTML组件的模板,我们实现了对LLM输出的精确控制。这种few-shot示例约束的方法,使LLM能够生成符合预期样式的HTML内容,而不是简单的文本或基础Markdown。
2. 多模态内容处理管道
Saga Reader实现了一个完整的内容处理管道,从原始网页到富文本展示,每个环节都由专门的处理器负责。这种模块化设计使系统易于维护和扩展。
3. 智能渲染适配
前端组件能够智能判断内容类型,对HTML和Markdown分别采用不同的渲染方式,确保最佳的展示效果。
结论
Saga Reader项目通过精心设计的提示词和完整的内容处理管道,成功地将大型语言模型应用于文本转换与富文本渲染优化。这种方法不仅提升了用户阅读体验,也为AI辅助内容处理提供了一个可行的实践范例。
未来,我们可以进一步探索更多的视觉元素和交互方式,使AI生成的内容更加丰富多样,更好地满足用户的阅读需求。同时,随着大型语言模型能力的不断提升,我们也可以期待更加智能和个性化的内容处理方案。
Saga Reader系列技术文章
- 开源我的一款自用AI阅读器,引流Web前端、Rust、Tauri、AI应用开发
- 【实战】深入浅出 Rust 并发:RwLock 与 Mutex 在 Tauri 项目中的实践
- 【实战】Rust与前端协同开发:基于Tauri的跨平台AI阅读器实践
- 揭秘 Saga Reader 智能核心:灵活的多 LLM Provider 集成实践 (Ollama, GLM, Mistral 等)
- Svelte 5 在跨平台 AI 阅读助手中的实践:轻量化前端架构的极致性能优化
- Svelte 5状态管理实战:基于Tauri框架的AI阅读器Saga Reader开发实践
- Svelte 5 状态管理全解析:从响应式核心到项目实战
- 【实战】基于 Tauri 和 Rust 实现基于无头浏览器的高可用网页抓取
深入剖析开源AI阅读器项目Saga Reader基于大模型的文本转换与富文本渲染优化方案的更多相关文章
- webApp 阅读器项目实践
这是一个webApp 阅读器的项目,是慕课网的老师讲授的一个实战,先给出项目源码在GitHub的地址:https://github.com/yulifromchina/MobileWebReader. ...
- 《BI项目笔记》基于雪花模型的维度设计
GBGradeCode 外键关系: 1 烟叶等级 T_GBGradeCode.I_DistinctionID=T_Distinction.I_DistinctionID 烟叶等级分为:上等烟.中等烟. ...
- 《Interest Rate Risk Modeling》阅读笔记——第八章:基于 LIBOR 模型用互换和利率期权进行对冲
目录 第八章:基于 LIBOR 模型用互换和利率期权进行对冲 思维导图 推导浮息债在重置日(reset date)的价格 第八章:基于 LIBOR 模型用互换和利率期权进行对冲 思维导图 推导浮息债在 ...
- 电子书及阅读器Demo
电子书阅读器(Kindle,电子纸技术.LCD.电子墨水技术等: 亚马逊/当当网站) 电子书产业可分5大环节:内容供应商.数字格式制作商.内容流通服务平台.传输平台以及终端阅读器产品. 全球电子书市 ...
- kobo阅读器安装koreader
动机 kobo阅读器是加拿大的电子阅读器品牌,与kindle类似.问题是这个阅读器在中国无法连接电子书商店,即使是用SS翻出去也不行.一气之下花了一个下午折腾,安装一个开源的阅读器. 安装 代码仓库在 ...
- Vue小说阅读器(仿追书神器)
一个vue阅读器项目,目前已升级到2.0,阅读器支持横向分页并滑动翻页(没有动画,需要动画的可以自己设置,增加transitionDuration即可) 技术栈 vue全家桶+mint-ui gith ...
- Leetcode本地阅读器开发--01界面设计一
返回项目声明及目录:Leetcode本地阅读器开发--总声明 整个界面设计如下:后续可能会不断优化和加入新功能 1.启动后界面 2.进行具体题目搜索 3.进行分类搜索 本节主要介绍程序界面的绘制: 1 ...
- RichText 富文本开源项目总结
在Android开发中,我们不免会遇到富文本的编辑和展示的需求,以下是本人之前star的富文本编辑器的开源项目,供大家参考: 一.RichEditor 开源项目地址:https://github.co ...
- 采用QT技术,开发OFD电子文档阅读器
前言 ofd作为板式文档规范,相当于国产化的pdf.由于pdf标准制定的较早,相关生态也比较完备,市面上的pdf阅读器种类繁多.国内ofd阅读器寥寥无几,作者此前采用wpf开发了一款阅读器,但该阅读器 ...
- AI 也开源:50 大开源 AI 项目 (转)
这些开源AI项目专注于机器学习.深度学习.神经网络及其他应用场合. 自IT界早期以来,研制出能像人类那样“思考”的机器一直是研究人员的一大目标.在过去几年,计算机科学家们在人工智能(AI)领域已取得了 ...
随机推荐
- selenium自动化测试-获取网页截图
今天学习下使用selenium自动化测试工具获取网页截图. 1,如果是简单获取当前屏幕截图只需要使用方法: driver.get_screenshot_as_file('screenshot.png' ...
- Windows 提权-服务_DLL 劫持
本文通过 Google 翻译 DLL Hijacking – Windows Privilege Escalation 这篇文章所产生,本人仅是对机器翻译中部分表达别扭的字词进行了校正及个别注释补充. ...
- Linux性能分析-CPU上下文切换
前言 在Linux性能分析-平均负载中,提到过一种导致平均负载升高的情况,就是有大量进程或线程等待cpu调度. 为什么大量进程或者线程等待CPU调度会导致负载升高呢? 当大量进程或者线程等待调度时,c ...
- 开发app步骤总结
以下是用IDEA后端Java开发(如Spring Boot)与Android Studio前端开发app的逻辑实现步骤详解: 一.技术选择 通信协议:推荐使用RESTful API(HTTP/HTTP ...
- 【Linux】5.5 Shell运算符
Shell运算符 Shell 和其他编程语言一样,支持多种运算符,包括: 算数运算符 关系运算符 布尔运算符 字符串运算符 文件测试运算符 原生bash不支持简单的数学运算,但是可以通过其他命令来实现 ...
- Python+硅基流动API实现小说转有声读物
一.注册硅基流动账号获取文本转语音api 1.注册登录硅基流动 注册.登录硅基流动 查看apikey 查看赠送的免费额度 点击文档中心 2.查看文本转语音api 查看文本转语音api 查看api使用指 ...
- 聊聊一体机与AI知识库
提供AI咨询+AI项目陪跑服务,有需要回复1 之前写了一篇关于一体机的文章: DeepSeek一体机是个什么鬼 一体机产生的原因是春节期间DeepSeek的火爆带动了一些公司的AI需求,但很多公司如医 ...
- MySQL 插入一条 SQL 语句,redo log 记录的是什么?
MySQL 插入一条 SQL 语句,redo log 记录的内容 在 MySQL 的 InnoDB 存储引擎中,redo log(重做日志)主要用来保证事务的持久性和崩溃恢复能力.redo log 记 ...
- VTK 入门系列之二:为三维场景添加坐标轴
一.引言 在进行三维可视化开发时,我们常常希望能够清晰了解模型在空间中的位置.方向与比例关系.而最直观的辅助工具就是三维坐标轴(Axes).在 VTK 中,vtkAxesActor 提供了一种开箱即用 ...
- 在AI大爆发的背景下,企业管理软件有什么冲击
今天与同行开会提到在AI大爆发的背景下,未来企业管理软件究竟有什么冲击? 我和同事对此问题进行了探讨,一些拙见,与大家分享.先直接说观点:在未来的5到10年,制造业的管理软件市场将几乎消失.下面我来聊 ...