编译原理:中间代码IR
IR,中间代码(Intermediate Representation,有时也称为Intermediate Code,IC),它是编译器中很重要的一种数据结构。编译器在做完前端工作以后,首先就生成IR,并在此基础上执行各种优化算法,最后再生成目标代码。
IR的用途和层次
设计IR的目的, 是要满足编译器中的各种需求。
需求的不同,就会导致IR的设计不同
通常情况下,IR有两种用途,一种是用来做分析和变换的,一种是直接用于解释执行的。
- 先来看第一种:用来分析和变换的
编译器中,基于 IR 的分析和处理工作,一开始可以基于一些抽象层次比较高的语义,这时所需要的 IR 更接近源代码。而在后面,则会使用低层次的、更加接近目标代码的语义。
基于这种从高到底的抽象层,IR可以归结为HIR/MIR和LIR三类
HIR:基于语言做一些分析和变换
假设你要开发一款 IDE,那最主要的功能包括:发现语法错误、分析符号之间的依赖关系(以便进行跳转、判断方法的重载等)、根据需要自动生成或修改一些代码(提供重构能力)。
这个时候,你对 IR 的需求,是能够准确表达源语言的语义就行了。这种类型的 IR,可以叫做 High IR,简称 HIR。
其实,AST 和符号表就可以满足这个需求。也就是说,AST 也可以算作一种 IR。 如果你要开发 IDE、代码翻译工具(从一门语言翻译到另一门语言)、代码生成工具、代码统计工具等,使用 AST(加上符号表)就够了。
基于HIR,可以做一些高层次的代码优化,比如常数折叠/内联等。在Java和Go的编译器中,可以看到不少基于AST做的优化工作。
MIR:独立于源语言和CPU架构做分析和优化
大量的优化算法是可以通用的,没有必要依赖源语言的语法和语义,也没有必要依赖具体的 CPU 架构。
这些优化包括部分算术优化、常量和变量传播、死代码删除等,实现这些类分析和优化功能的IR可以叫做Middle IR,简称MIR.
因为MIR跟源代码和目标代码都无关,所以在讲解优化算法时,通常是基于MIR,比如三地址代码(Three Address Code,TAC).
TAC的特点是:最多三个地址(也就是变量),其中赋值符号的左边是用来写入的,而右边最多可以有两个地址和一个操作符,用于读取数据并计算。
举例:
示例函数foo:
int foo (int a){
int b = 0;
if (a > 10)
b = a;
else
b = 10;
return b;
}
对应的TAC可能是:
BB1:
b := 0
if a>10 goto BB3 //如果t是false(0),转到BB3
BB2:
b := 10
goto BB4
BB3:
b := a
BB4:
return b
可以看到,TAC 用 goto 语句取代了 if 语句、循环语句这种比较高级的语句,当然也不会有类、继承这些高层的语言结构。但是,它又没有涉及数据如何在内存读写等细节,书写格式也不像汇编代码,与具体的目标代码也是独立的。
所以,它的抽象程度算是不高不低。
LIR:依赖于CPU架构做优化和代码生成
最后一类IR就是Low IR,简称LIR
这类IR的特点,是它的指令通常可以与机器指令一一对应,比较容易翻译成机器指令(或汇编代码)。因为LIR体现了CPU架构的底层特征,因此可以做一些于具体CPU架构相关的优化。
比如,下面是 Java 的 JIT 编译器输出的 LIR 信息,里面的指令名称已经跟汇编代码很像了,并且会直接使用 AMD64 架构的寄存器名称。
Java的JIT编译器的LIR:
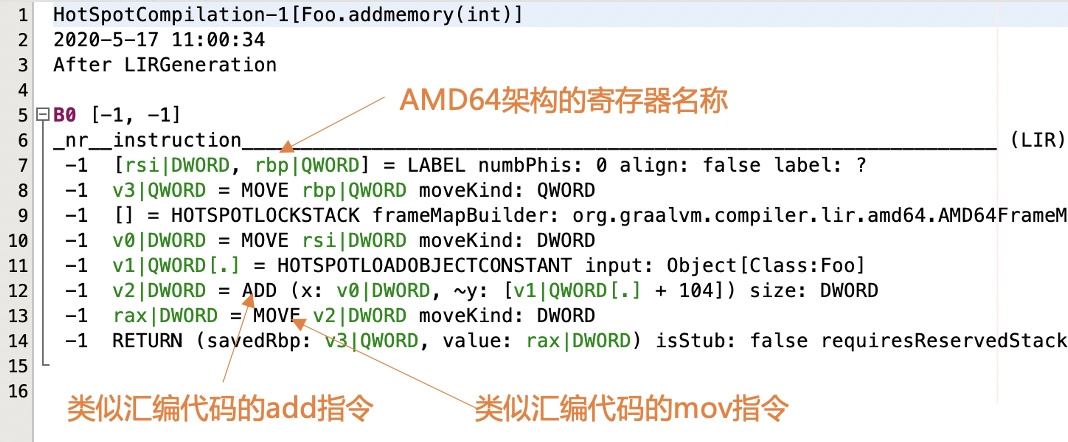
编译过程可以理解为,抽象层次高的 IR 一直 lower 到抽象层次低的 IR 的过程,并且在每种 IR 上都会做一些适合这种 IR 的分析和处理工作,直到最后生成了优化的目标代码。
扩展:lower 这个词的意思,就是把对计算机程序的表示,从抽象层次比较高的、便于人理解的格式,转化为抽象层次比较低的、便于机器理解的格式。
- 第二类用于解释执行的IR -- P-code
前3类IR是从抽象层次来划分的,他们都用来分析和变换的。
第二中用于解释执行的IR,这类IR有一个名称,叫做P-code, 也就是Portable Code的意思。
由于它于具体机器无关,因此可以很容易地运行在多种电脑上。这类IR对编译器来说,就是做编译器的目标代码。
注:P-code也可能被进一步编译,形成可以直接执行的机器码 Java 的字节码就是这样的例子。因此,在本节中探究 Java 的两个编译器,一个把源代码编译成字节码,一个把字节码编译成目标代码(支持 JIT 和 AOT 两种方式)。
IR的呈现格式
IR通常是没有书写格式的
- 一方面,大多数的IR跟AST一样,只是编译过程中一个数据结构而已,或者说只有内存格式。比如,LLVM的IR在内存里是一些对象和接口
- 另一方面,为了调试需要,可以把IR以文本的方式输出,用于现实和分析,比如下面的Julia的IR:
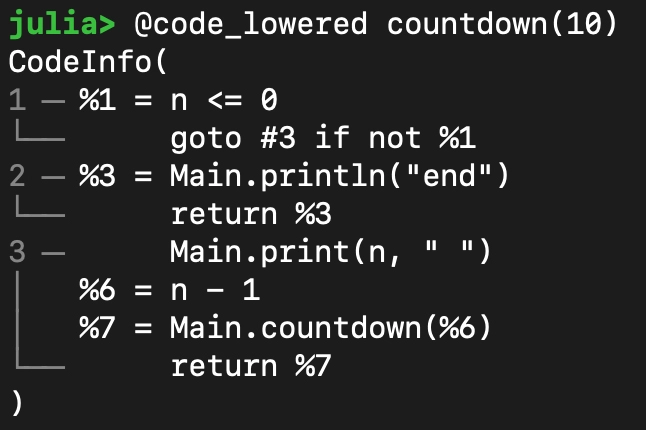
在少量情况下,IR 有比较严格的输出格式,不仅用于显示和分析,还可以作为结果保存,并可以重新读入编译器中。比如,LLVM 的 bitcode,可以保存成文本和二进制两种格式,这两种格式间还可以相互转换
以 C 语言为例,来看下 fun1 函数,及其对应的 LLVM IR 的文本格式和二进制格式:
//fun1.c
int fun1(int a, int b){
int c = 10;
return a+b+c;
}
LLVM IR 的文本格式("clang -emit-llvm -S fun1.c -o fun1.ll"命令生成,这里只节选了主要部分):
; ModuleID = 'fun1.c'
source_filename = "function-call1.c"
target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.14.0"
; Function Attrs: noinline nounwind optnone ssp uwtable
define i32 @fun1(i32, i32) #0 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
store i32 %0, i32* %3, align 4
store i32 %1, i32* %4, align 4
store i32 10, i32* %5, align 4
%6 = load i32, i32* %3, align 4
%7 = load i32, i32* %4, align 4
%8 = add nsw i32 %6, %7
%9 = load i32, i32* %5, align 4
%10 = add nsw i32 %8, %9
ret i32 %10
}
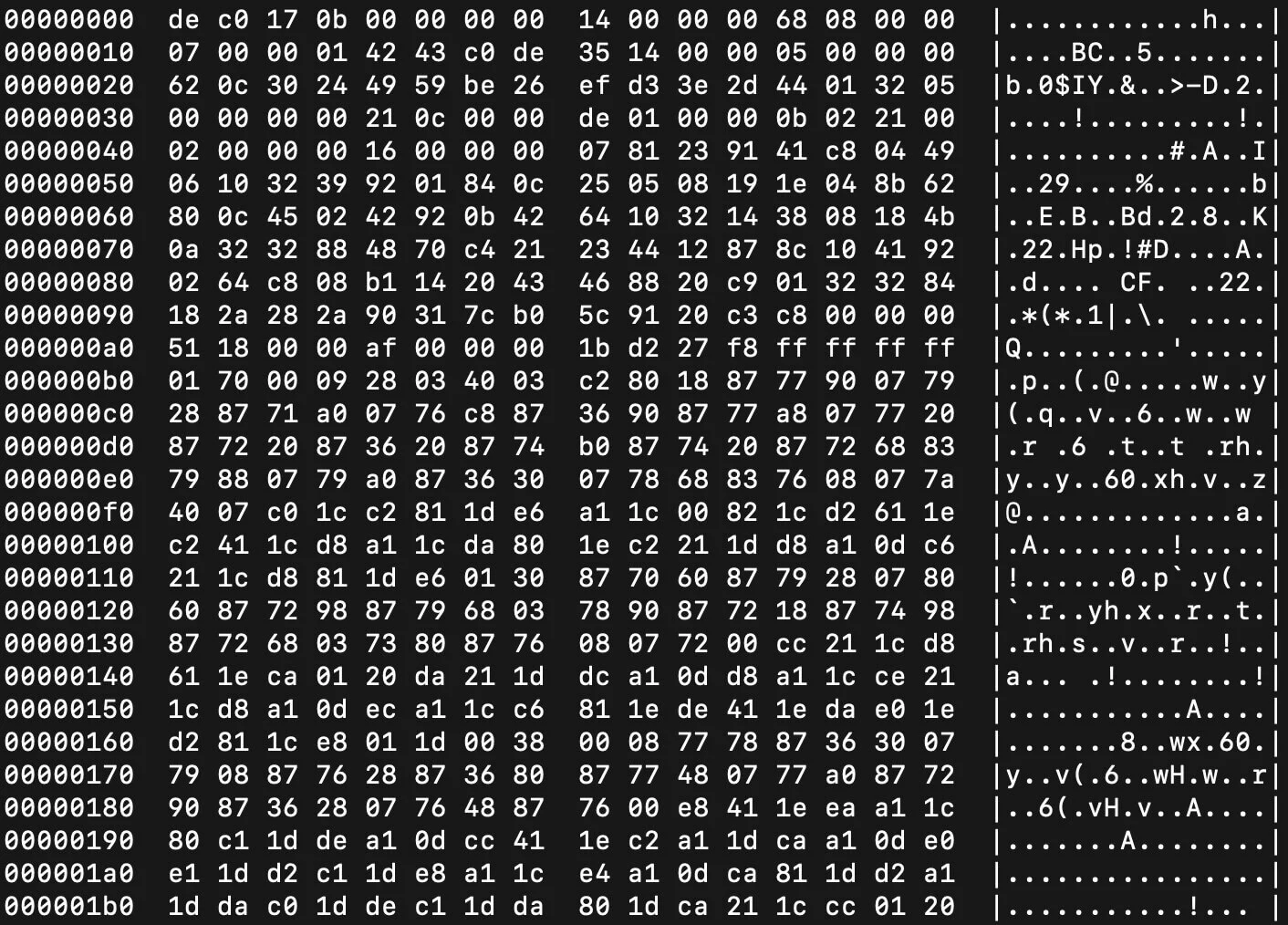
二进制格式(用"clang -emit-llvm -c fun1.c -o fun1.bc"命令生成,用"hexdump -C fun1.bc"命令显示):
LLVM IR的二进制格式:
IR的数据结构
在实际的实现中,有线性结构/树结构/有向无环图(DAG)/程序依赖图(PDG)等多种格式。编译器会根据需要,选择合适的数据结构。
在运行某些算法的时候,采用某个数据结构可能会更顺畅,而采用另一些结构可能会带来内在的阻滞。所以,一定要根据具体要处理的工作特点,来选择合适的数据结构。
下面来看下各种格式的特点。
第一种:类似TAC的线性结构(Linear Form)
可以把代码表示成一行行的指令或语句,用数组或者列表保存就行了。其中的符号,需要引用符号表,来提供类型等信息。
这种线性结构有时候也被称作 goto 格式。因为高级语言里的条件语句、循环语句,要变成用 goto 语句跳转的方式。
第二种:树结构
树结构也可以用作IR,AST就是一种树结构。
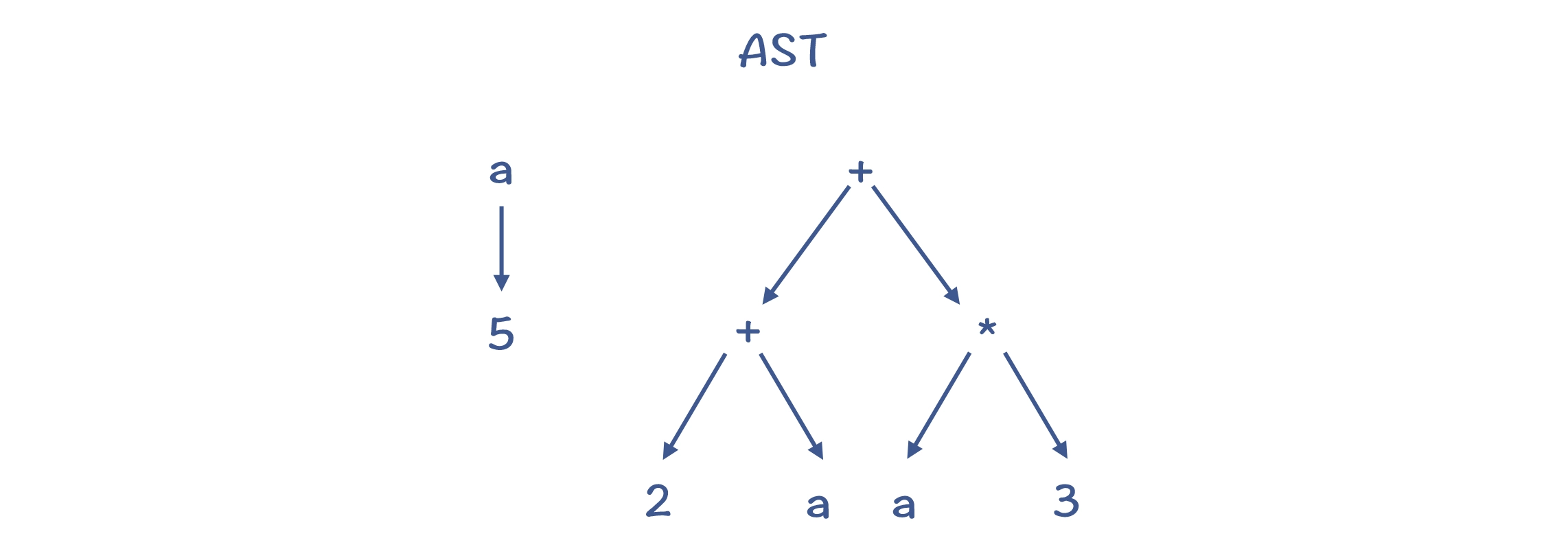
树结构的缺点是:可能有冗余的子树。 比如,语句"a=5; b=(2+a)+a*3;"形成的AST就有冗余。如果基于这个树结构生成代码,可能会做两次从内存中读取 a 的值的操作,并存到两个临时变量中。
冗余的子树:
第三种: 有向无环图(Directed Acyclic Graph,DAG)
DAG 结构,是在树结构的基础上,消除了冗余的子树。比如,上面的例子转化成 DAG 以后,对 a 的内存访问只做一次就行了。
GAG结构消除了冗余的子树:
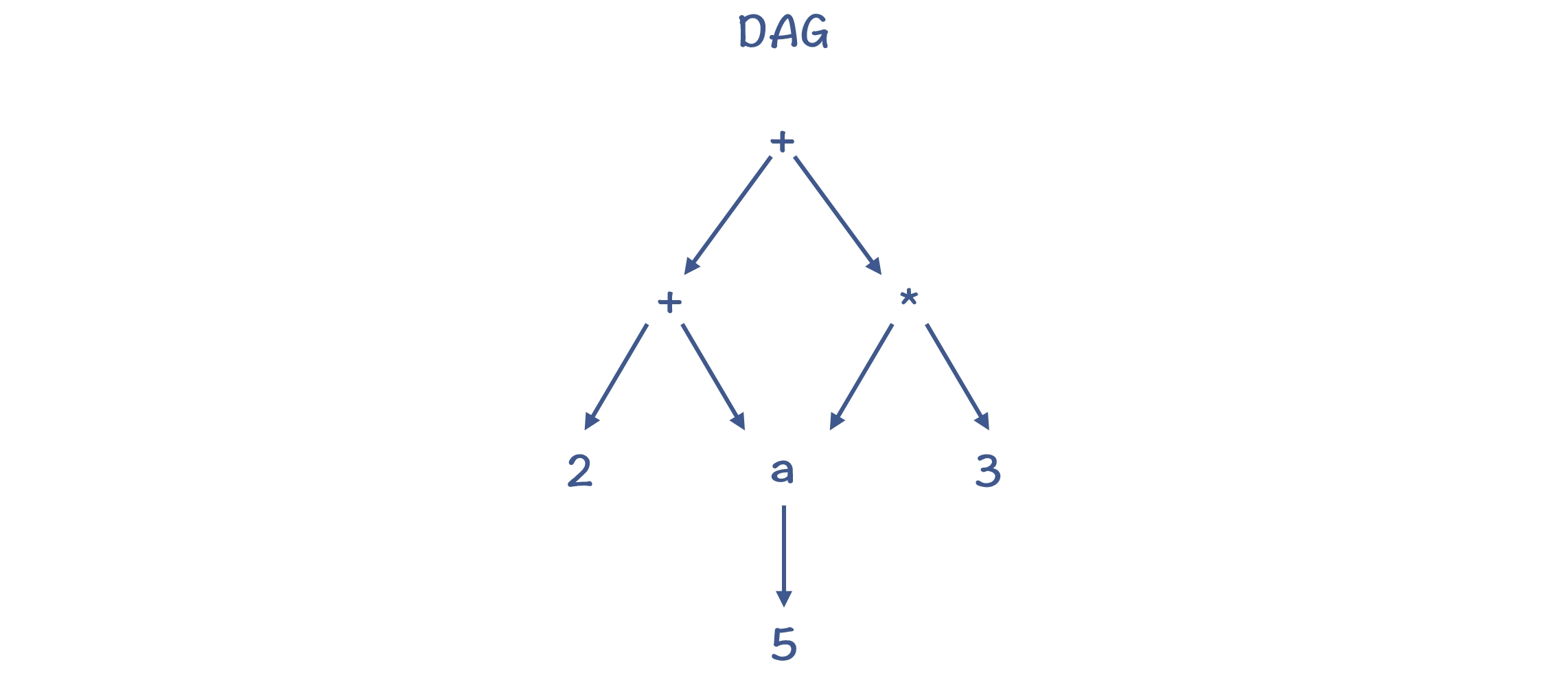
在 LLVM 的目标代码生成环节,就使用了 DAG 来表示基本块内的代码。
第四种: 程序依赖图(Program Dependence Graph,PDG)
程序依赖图,是显式地把程序中的数据依赖和控制依赖表示出来,形成一个图状的数据结构。基于这个数据结构,我们再做一些优化算法的时候,会更容易实现。
这种数据结构里,因为会有很多图节点,又被形象地称为“节点之海(Sea of Nodes)”
接下来介绍一个重要的IR设计范式:SSA格式
SSA格式的IR
SSA 是** Static Single Assignment ** 的缩写,也就是静态单赋值。 这是 IR 的一种设计范式,它要求一个变量只能被赋值一次。我们来看个例子。
“y = x1 + x2 + x3 + x4”的普通 TAC 如下:
y := x1 + x2;
y := y + x3;
y := y + x4;
其中,y被赋值三次,如果写成SSA的形式,就只能写成下面的样子:
t1 := x1 + x2;
t2 := t1 + x3;
y := t2 + x4;
那为什么要费力写成这种形式呢,还要为此多添加t1和t2两个临时变量?
原因是,使用SSA的形式,体现了精确的使用--定义(use-def)关系,并且由于变量的值定义出来后就不再变化,使得基于SSA更容易运行一些优化算法。
在SSA格式的IR中,有些特别的指令,叫做phi指令,举个例子:
同样对于示例代码:
int foo (int a){
int b = 0;
if (a > 10)
b = a;
else
b = 10;
return b;
}
它对应SSA格式的IR可以写成:
BB1:
b1 := 0
if a>10 goto BB3
BB2:
b2 := 10
goto BB4
BB3:
b3 := a
BB4:
b4 := phi(BB2, BB3, b2, b3)
return b4
其中,变量b有四个版本:b1是初始值,b2是else块(BB2)的取值,b3是if块(BB3)的取值,最后一个基本块(BB4)要把b的最后取值作为函数返回值。很明显,b的取值有可能是b2,也有可能是b3,这个时候,就需要phi指令了。
phi指令,会根据控制流的实际情况确定b4的值。 如果BB4的前序节点是BB2,那么b4的取值是b2;而如果BB4的前序节点是BB3,那么b4的取值就是b3.所以,如果要满足SSA的要求,也就是一个变量只能赋值一次,那么在遇到程序分支的情况下,就必须引入phi指令。
最后要指出的是:由于SSA格式的有点,现代语言用于优化的IR,很多都是基于SSA的了,包括Java的JIT编译器/JavaScript的V8编译器/Go语言的gc编译器/Julia编译器以及LLVM工具等。 所以一定要高度重视SSA.
小结
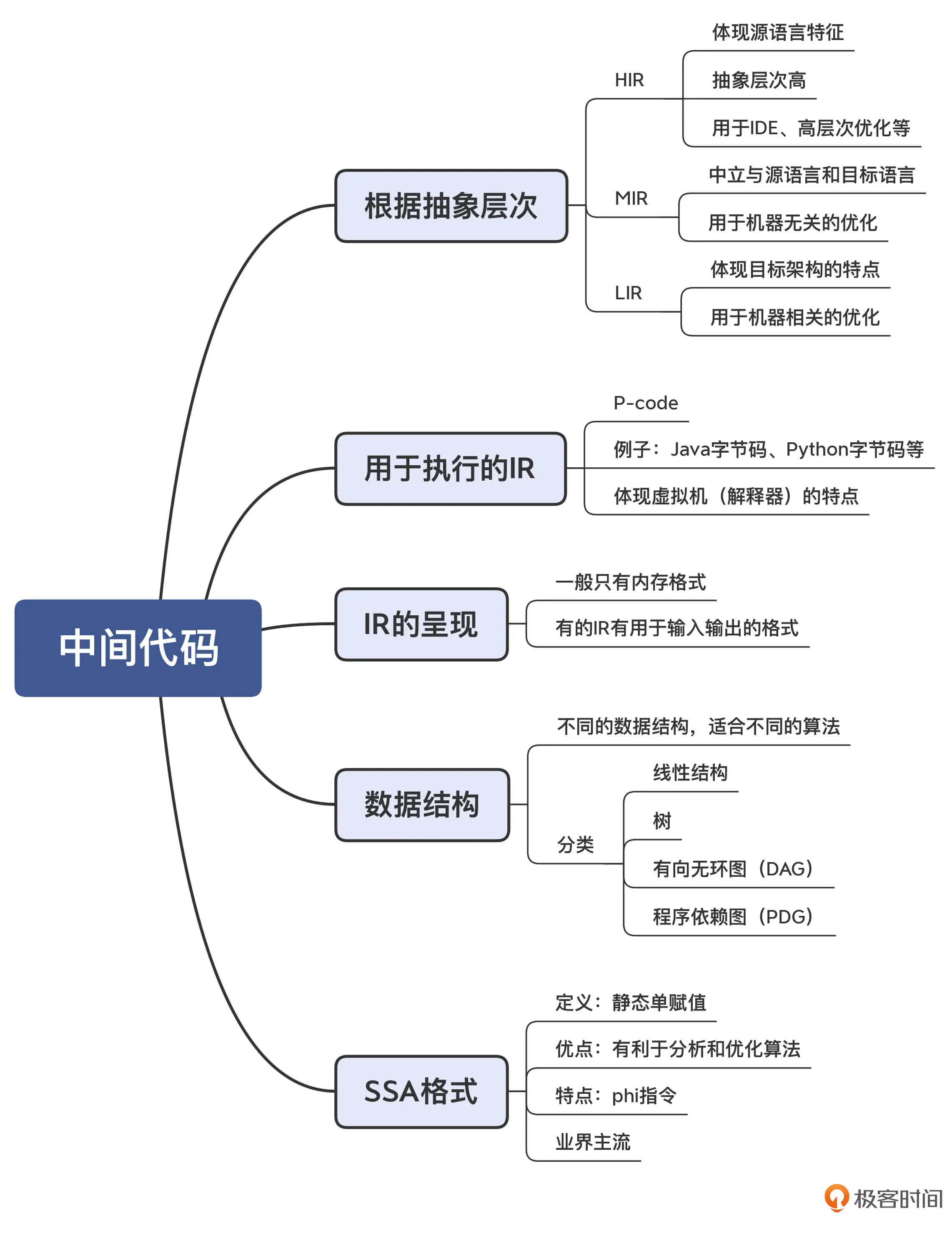
IR的几个重要概念:
根据抽象层次和使用目的的不同,可以设计不同的IR.
IR可能采取多种数据结构,每种结构适合不同的处理工作
由于SSA格式的有点,主流的编译器都在采用这种范式来设计IR
参考:
中间代码:不是只有一副面孔
编译原理:中间代码IR的更多相关文章
- 【编译原理】c++实现自下而上语法分析及中间代码(四元式)生成
写在前面:本博客为本人原创,严禁任何形式的转载!本博客只允许放在博客园(.cnblogs.com),如果您在其他网站看到这篇博文,请通过下面这个唯一的合法链接转到原文! 本博客全网唯一合法URL:ht ...
- Atitit.编译原理与概论
Atitit.编译原理与概论 编译原理 词法分析 Ast构建,语法分析 语意分析 6 数据结构 1. ▪ 记号 2. ▪ 语法树 3. ▪ 符号表 4. ▪ 常数表 5. ▪ 中间代码 1. ▪ 临 ...
- Compiler Theory(编译原理)、词法/语法/AST/中间代码优化在Webshell检测上的应用
catalog . 引论 . 构建一个编译器的相关科学 . 程序设计语言基础 . 一个简单的语法制导翻译器 . 简单表达式的翻译器(源代码示例) . 词法分析 . 生成中间代码 . 词法分析器的实现 ...
- 学了编译原理能否用 Java 写一个编译器或解释器?
16 个回答 默认排序 RednaxelaFX JavaScript.编译原理.编程 等 7 个话题的优秀回答者 282 人赞同了该回答 能.我一开始学编译原理的时候就是用Java写了好多小编译器和 ...
- 编译原理(一)绪论概念&文法与语言
绪论概念&文法与语言 以老师PPT为标准,借鉴部分教材内容,AlvinZH学习笔记. 绪论基本概念 1. 低级语言:字位码.机器语言.汇编语言.与特定的机器有关,功效高,但使用复杂.繁琐.费时 ...
- C#面向过程之编译原理、变量、运算符
.net基础:.net与C# .net是一个平台 c#是一门语言 .net的用途a.桌面应用程序 b.网站应用程序 c.专业游戏开发(XBOX360) d.嵌入式设备软件开发 e.智能手机APP开发 ...
- Java的编译原理
概述 java语言的"编译期"分为前端编译和后端编译两个阶段.前端编译是指把*.java文件转变成*.class文件的过程; 后端编译(JIT, Just In Time Comp ...
- MOOC 编译原理笔记(一):编译原理概述以及程序设计语言的定义
编译原理概述 什么是编译程序 编译程序指:把某一种高级语言程序等价地转换成另一张低级语言程序(如汇编语言或机器代码)的程序. 高级语言程序-翻译->机器语言程序-运行->结果. 其中编译程 ...
- 《编译原理》控制流语句 if 和 while 语句的翻译 - 例题解析
<编译原理>控制流语句 if 和 while 语句的翻译 - 例题解析 将 if 和 while 语句翻译成四元式 注:不同教材会有小差异,使用 _ 或者 - ,如果是 -,请注意区分 - ...
- Java 实现《编译原理》中间代码生成 -逆波兰式生成与计算 - 程序解析
Java 实现<编译原理>中间代码生成 -逆波兰式生成与计算 - 程序解析 编译原理学习笔记 (一)逆波兰式是什么? 逆波兰式(Reverse Polish notation,RPN,或逆 ...
随机推荐
- vue element 动态增加表单并进行表单验证
表单验证:需要注意的一点是: 普通表单验证单项依靠的是prop-而动态生成的表单要用:prop 书写的语法是:prop="'moreNotifyObject.' + index +'.not ...
- IIS反向代理和URL重写——实现https重定向,文件类型隐藏访问重写,nodejs等服务重写等等
一.Why? 1.先来讲一讲为什么我们要使用url重写这个东西 2.因为我学习的后端是nodejs,然后我发现nodejs一个非常让人难受的事,就是它监听端口不是80和443时,你访问网页需要输入端口 ...
- Linux - top相关的快捷键
q:退出top命令窗口(quit). k:按照进程ID终止(kill)一个进程.例如,你可以输入k,然后输入进程的PID来终止它. r:重新设置进程的优先级.输入r后,你可以输入新的优先级值. f:进 ...
- 2024数证杯决赛团体赛wp
2024数证杯决赛团体赛wp 容器密码:mW7@B!tRp*Xz46Y9#KFUV^J2&NqoHqTpLCE%8rvGW(AX#1k@YL3$M5!bWY*9HLFq7UZR6^T!XoVm ...
- 震惊!AI 编程竟然让程序员 “失业” 了?真相让人意外
在科技飞速发展的当下,AI 编程的异军突起无疑成为了整个编程领域乃至社会各界热议的焦点. 去年,全球首个AI程序员Devin横空出世,不仅能独立完成代码开发.修复Bug,甚至能通过阅读技术文档自主学习 ...
- [第一章]ABAQUS CM插件中文手册
ABAQUS Composite Modeler User Manual(zh-CN) Dassault Systèmes, 2018 注: 源文档的交叉引用链接,本文无效 有些语句英文表达更易理解, ...
- allure 报告空白
在pycharm 运行py文件后生成的报告内容空白: 尝试方法 替换allure版本号---不好用 用命令生成.html测试报告,再以浏览器形式打开 ** ** 命令 allure generate ...
- GIT 基础操作-初始化
命令行说明 全局设置 git config --global user.name "" git config --global user.email "" 创建 ...
- VS2019如何将主菜单从标题栏移到单独一行
vs2019安装后默认将菜单栏放在标题栏位置,这给我们日常使用带来些许不便 多窗口不能直观看到项目名 小屏幕上可以用来拖动窗口的区域太小 下面是恢复经典标题栏和菜单栏位置的方法 工具->选项-& ...
- 虚拟机为什么ping不通主机
在虚拟机里各种操作都正常.就是ping不通主机.为什么? NAT模式下(网络地址转换模式),虚拟机后网络适配器就会出现VMnet8网卡: 把VMnet8的ip4设定成你主机同段IP.这个VMnet8地 ...