残差网络(Residual Network)
一、背景
1)梯度消失问题
我们发现很深的网络层,由于参数初始化一般更靠近0,这样在训练的过程中更新浅层网络的参数时,很容易随着网络的深入而导致梯度消失,浅层的参数无法更新。

可以看到,假设现在需要更新b1,w2,w3,w4参数因为随机初始化偏向于0,通过链式求导我们会发现,w1w2w3相乘会得到更加接近于0的数,那么所求的这个b1的梯度就接近于0,也就产生了梯度消失的现象。
2)网络退化问题
举个例子,假设已经有了一个最优化的网络结构,是18层。当我们设计网络结构的时候,我们并不知道具体多少层次的网络时最优化的网络结构,假设设计了34层网络结构。那么多出来的16层其实是冗余的,我们希望训练网络的过程中,模型能够自己训练这五层为恒等映射,也就是经过这层时的输入与输出完全一样。但是往往模型很难将这16层恒等映射的参数学习正确,那么就一定会不比最优化的18层网络结构性能好,这就是随着网络深度增加,模型会产生退化现象。它不是由过拟合产生的,而是由冗余的网络层学习了不是恒等映射的参数造成的。
二、ResNets 残差网络
ResNet是在2015年有何凯明,张翔宇,任少卿,孙剑共同提出的,ResNet使用了一个新的思想,ResNet的思想是假设我们涉及一个网络层,存在最优化的网络层次,那么往往我们设计的深层次网络是有很多网络层为冗余层的。那么我们希望这些冗余层能够完成恒等映射,保证经过该恒等层的输入和输出完全相同。具体哪些层是恒等层,这个会有网络训练的时候自己判断出来。

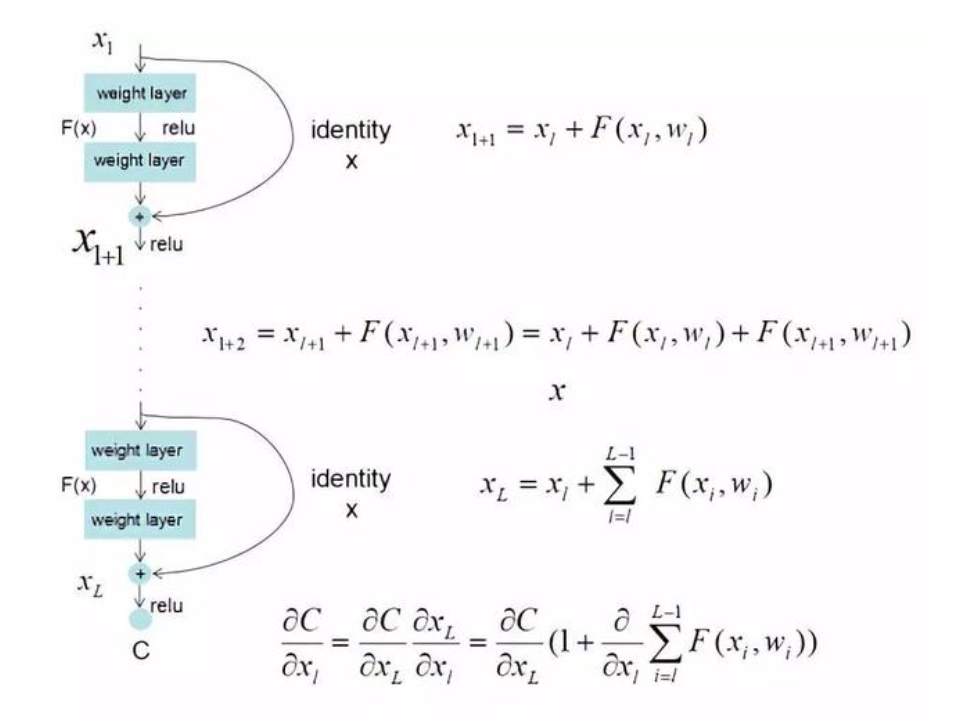
可以看到X是这一层残差块的输入,也称作F(x)为残差,x为输入值,F(X)是经过第一层线性变化并激活后的输出,该图表示在残差网络中,第二层进行线性变化之后激活之前,F(x)加入了这一层输入值X,然后再进行激活后输出。在第二层输出值激活前加入X,这条路径称作shortcut连接。
三、网络架构
1)普通网络(Plain Network)

2) 残差网络
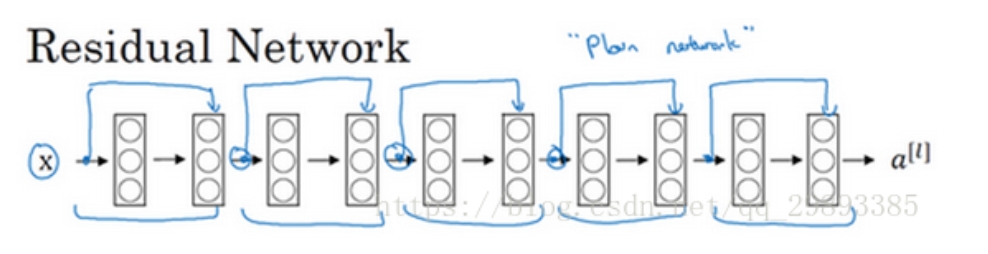
把它变成ResNet的方法是加上所有跳跃连接,每两层增加一个捷径,构成一个残差块。如图所示,5个残差块连接在一起构成一个残差网络。
3)对比分析

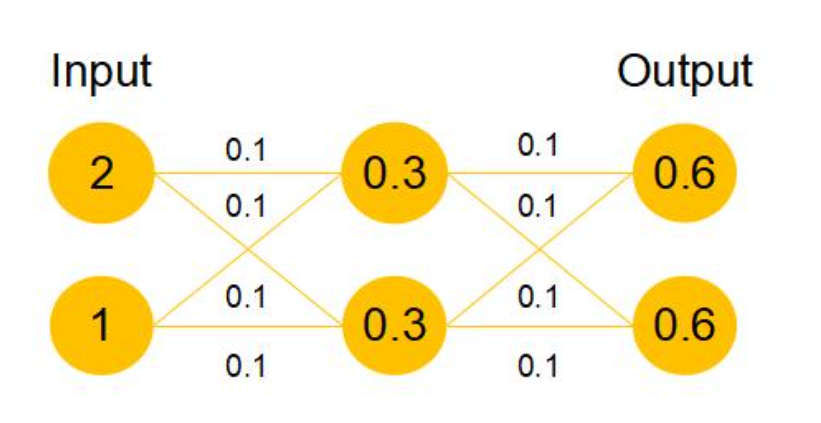
假设该曾网络只经过线性变换,没有bias也没有激活函数。我们发现因为随机初始化权重一般偏向于0,那么经过该网络的输出值为[0.6 0.6],很明显会更接近与[0 0],而不是[2 1],相比与学习h(x)=x,模型要更快到学习F(x)=0。并且ReLU能够将负数激活为0,过滤了负数的线性变化,也能够更快的使得F(x)=0。这样当网络自己决定哪些网络层为冗余层时,使用ResNet的网络很大程度上解决了学习恒等映射的问题,用学习残差F(x)=0更新该冗余层的参数来代替学习h(x)=x更新冗余层的参数。
这样当网络自行决定了哪些层为冗余层后,通过学习残差F(x)=0来让该层网络恒等映射上一层的输入,使得有了这些冗余层的网络效果与没有这些冗余层的网络效果相同,这样很大程度上解决了网络的退化问题
残差网络(Residual Network)的更多相关文章
- [DeeplearningAI笔记]卷积神经网络2.3-2.4深度残差网络
4.2深度卷积网络 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 [残差网络]--He K, Zhang X, Ren S, et al. Deep Residual Learni ...
- 关于深度残差网络(Deep residual network, ResNet)
题外话: From <白话深度学习与TensorFlow> 深度残差网络: 深度残差网络的设计就是为了克服这种由于网络深度加深而产生的学习效率变低,准确率无法有效提升的问题(也称为网络退化 ...
- 残差网络(Residual Networks, ResNets)
1. 什么是残差(residual)? “残差在数理统计中是指实际观察值与估计值(拟合值)之间的差.”“如果回归模型正确的话, 我们可以将残差看作误差的观测值.” 更准确地,假设我们想要找一个 $x$ ...
- Deep Residual Learning for Image Recognition(残差网络)
深度在神经网络中有及其重要的作用,但越深的网络越难训练. 随着深度的增加,从训练一开始,梯度消失或梯度爆炸就会阻止收敛,normalized initialization和intermediate n ...
- CNN卷积神经网络_深度残差网络 ResNet——解决神经网络过深反而引起误差增加的根本问题,Highway NetWork 则允许保留一定比例的原始输入 x。(这种思想在inception模型也有,例如卷积是concat并行,而不是串行)这样前面一层的信息,有一定比例可以不经过矩阵乘法和非线性变换,直接传输到下一层,仿佛一条信息高速公路,因此得名Highway Network
from:https://blog.csdn.net/diamonjoy_zone/article/details/70904212 环境:Win8.1 TensorFlow1.0.1 软件:Anac ...
- 残差网络resnet学习
Deep Residual Learning for Image Recognition 微软亚洲研究院的何凯明等人 论文地址 https://arxiv.org/pdf/1512.03385v1.p ...
- 深度残差网络(DRN)ResNet网络原理
一说起“深度学习”,自然就联想到它非常显著的特点“深.深.深”(重要的事说三遍),通过很深层次的网络实现准确率非常高的图像识别.语音识别等能力.因此,我们自然很容易就想到:深的网络一般会比浅的网络效果 ...
- JPEG Image Super-Resolution via Deep Residual Network
基于深度残差网络的JPEG图像超分辨率 JPEG Image Super-Resolution via Deep Residual Network PDF https://www.researchga ...
- 深度残差网络——ResNet学习笔记
深度残差网络—ResNet总结 写于:2019.03.15—大连理工大学 论文名称:Deep Residual Learning for Image Recognition 作者:微软亚洲研究院的何凯 ...
随机推荐
- POSt 提交参数 实体 和字符串
//1.后台接受是 字符串形式 [HttpPost] public int SendTaxiAudioByWX(string userid, string suid, string indexno, ...
- mysql 数据类型 及 常用命令
一.数据类型 1.整型 数据类型 存储空间 说明 取值范围 TINYINT 1字节 非常小的整数 带符号值:-128~127 无符号值:0~255 SMALLINT 2字节 较小的整数 带符号值:-3 ...
- Git(未完待续)
Git的历史咱们就不多说来,我还是喜欢直白点,直接来干货吧 在Linux上安装Git 不同的系统不同的安装命令,基础的就不说来,centos直接yum就ok. 安装完成后,还需要最后一步设置,在命令行 ...
- 【HLSDK系列】服务端 UpdateClientData 函数
首先说明下,这个函数是写在 mp.dll 里的. 服务器会给每个客户端发送一些数据,其中两大数据种类就是 clientdata_t 和 entity_state_t 这里要说的是 clientdata ...
- XML格式化加载的时候提示Content is not allowed in prolog. Nested exception: Content is not allowed in prolog
原因:原本是.xml文件格式的内容,被你用右键,文本编辑,保存,导致格式不认了. 解决方法:下载个notepad+ 工具,用这工具打开,修改,编辑,保存,即可被继续认作xml格式.
- 洛谷P2125图书馆书架上的书 题解报告
题目描述 图书馆有n个书架,第1个书架后面是第2个书架,第2个书架后面是第3个书架……第n-1个书架后面是第n个书架,第n个书架后面是第1个书架,第i个书架上有b[i]本书.现在,为了让图书馆更美观, ...
- 2656: [Zjoi2012]数列(sequence)(递归+高精度)
好久没写题了T T NOIP 期中考双血崩 显然f(x)=f(x>>1)+f((x>>1)+1),考虑每次往x>>1递归,求出f(x),复杂度O(logN) 我们设 ...
- 【DP】【P5080】 Tweetuzki 爱序列
Description Tweetuzki 有一个长度为 \(n\) 的序列 \(a_1~,~a_2~,~\dots~,a_n\). 他希望找出一个最大的 \(k\),满足在原序列中存在一些数 \(b ...
- Google protocol buffer的配置和使用(Linux&&Windows)
最近自己的服务器做到序列化这一步了,在网上看了下,序列化的工具有boost 和google的protocol buffer, protocol buffer的效率和使用程度更高效一些,就自己琢磨下把他 ...
- ftp server安装与配置
http://note.youdao.com/noteshare?id=905513cfcdba7d6a8d2fbdd0874a6259