Tensorboard教程:监控指标可视化
Tensorflow监控指标可视化




参考文献
强烈推荐Tensorflow实战Google深度学习框架
实验平台:
Tensorflow1.4.0
python3.5.0
MNIST数据集将四个文件下载后放到当前目录下的MNIST_data文件夹下
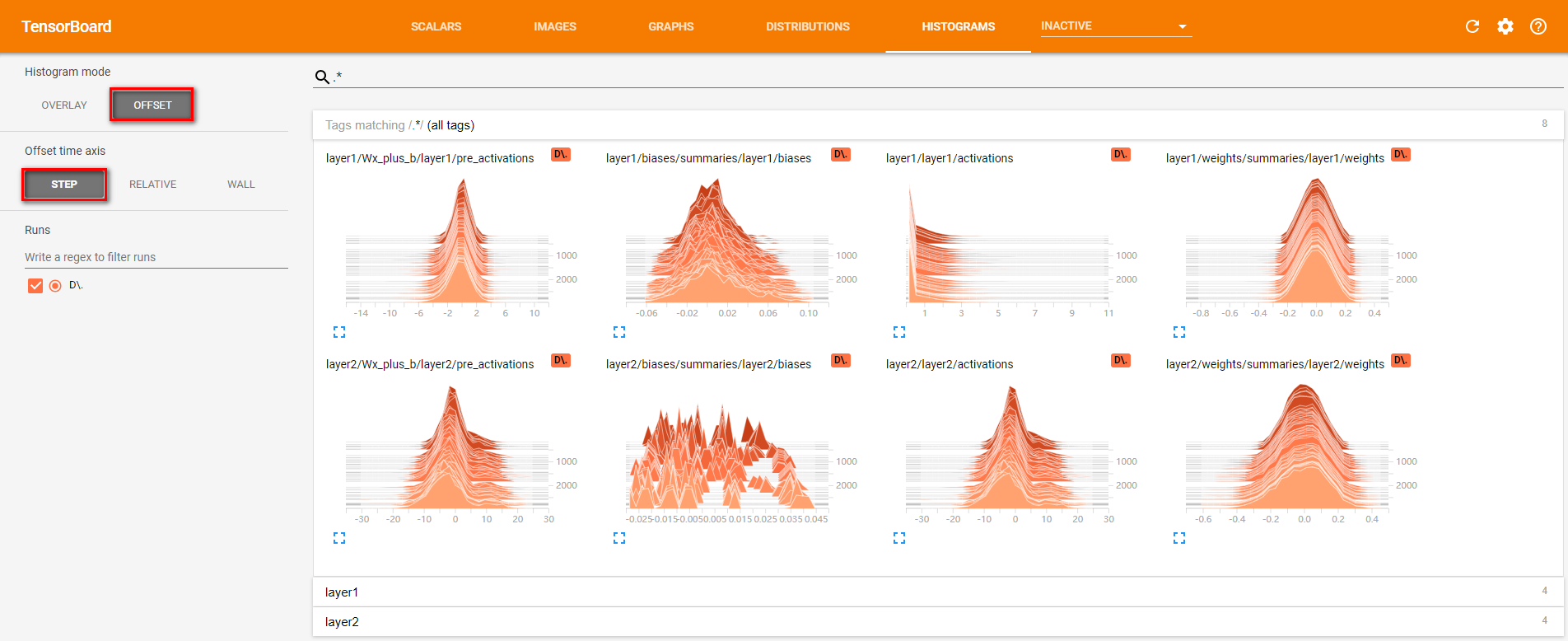
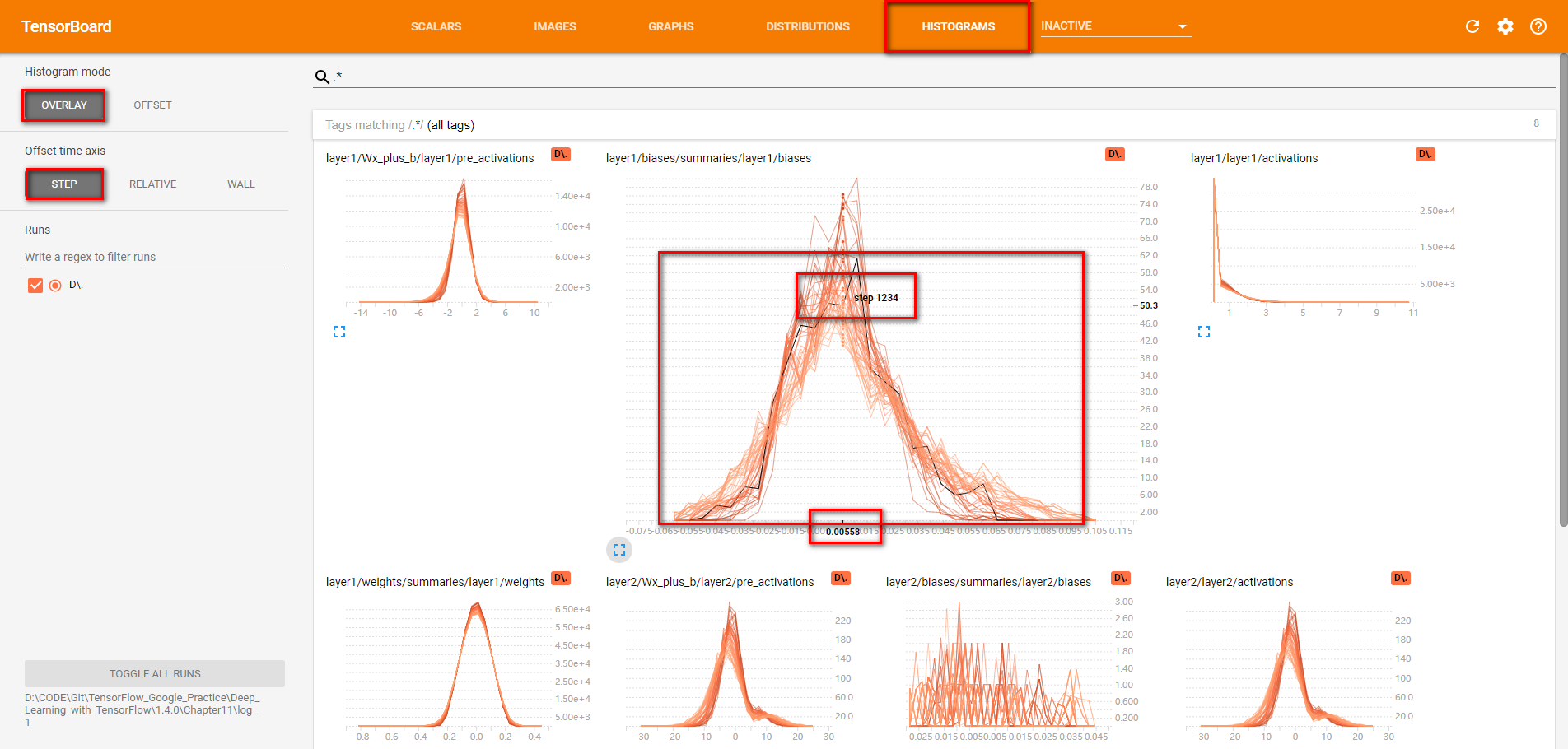
- Tensorflow命名空间与计算图可视化介绍了通过TensorBoard的GRAPHS可视化TensorFlow计算图的结构以及在计算图上的信息。TensorBoard 除了可以可视化TensorFlow 的计算图,还可以可视化TensorFlow 程序运行过程中各种有助于了解程序运行状态的监控指标。在本节中将介绍如何利用TensorBoard 中其他栏目可视化这些监控指标。除了GRAPHS以外,TensorBoard界面中还提供了SCALARS(标量),IMAGESAUDIO(图片),DISTRIBUTIONS(统计分布)HISTOGRAMS(直方图统计分布)和TEXT(文本)六个界面来可视化其他的监控指标。以下程序展示了如何将TensorFlow程序运行时的信息输出到TensorBoard 日志文件中。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import tqdm
# #### 1. 生成变量监控信息并定义生成监控信息日志的操作。
SUMMARY_DIR = "log_1"
BATCH_SIZE = 100
TRAIN_STEPS = 3000
# var给出了需要记录的张量,name给出了在可视化结果中显示的图表名称,这个名称一般和变量名一致
def variable_summaries(var, name):
# 将生成监控信息的操作放在同一个命名空间下
with tf.name_scope('summaries'):
# 通过tf.histogram_summary函数记录张量中元素的取值分布
# tf.summary.histogram函数会生成一个Summary protocol buffer.
# 将Summary 写入TensorBoard 门志文件后,在HISTOGRAMS 栏,和
# DISTRIBUTION 栏下都会出现对应名称的图表。和TensorFlow 中其他操作类似,
# tf.summary.histogram 函数不会立刻被执行,只有当sess.run 函数明确调用这个操作时, TensorFlow
# 才会具正生成并输出Summary protocol buffer.
tf.summary.histogram(name, var)
# 计算变量的平均值,并定义生成平均值信息日志的操作,记录变量平均值信息的日志标签名
# 为'mean/'+name,其中mean为命名空间,/是命名空间的分隔符
# 在相同命名空间中的监控指标会被整合到同一栏中,name则给出了当前监控指标属于哪一个变量
mean = tf.reduce_mean(var)
tf.summary.scalar('mean/' + name, mean)
# 计算变量的标准差,并定义生成其日志文件的操作
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev/' + name, stddev)
# #### 2. 生成一层全链接的神经网络。
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
# 将同一层神经网络放在一个统一的命名空间下
with tf.name_scope(layer_name):
# 声明神经网络边上的权值,并调用权重监控信息日志的函数
with tf.name_scope('weights'):
weights = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1))
variable_summaries(weights, layer_name + '/weights')
# 声明神经网络边上的偏置,并调用偏置监控信息日志的函数
with tf.name_scope('biases'):
biases = tf.Variable(tf.constant(0.0, shape=[output_dim]))
variable_summaries(biases, layer_name + '/biases')
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
# 记录神经网络节点输出在经过激活函数之前的分布
tf.summary.histogram(layer_name + '/pre_activations', preactivate)
activations = act(preactivate, name='activation')
# 记录神经网络节点输出在经过激活函数之后的分布。
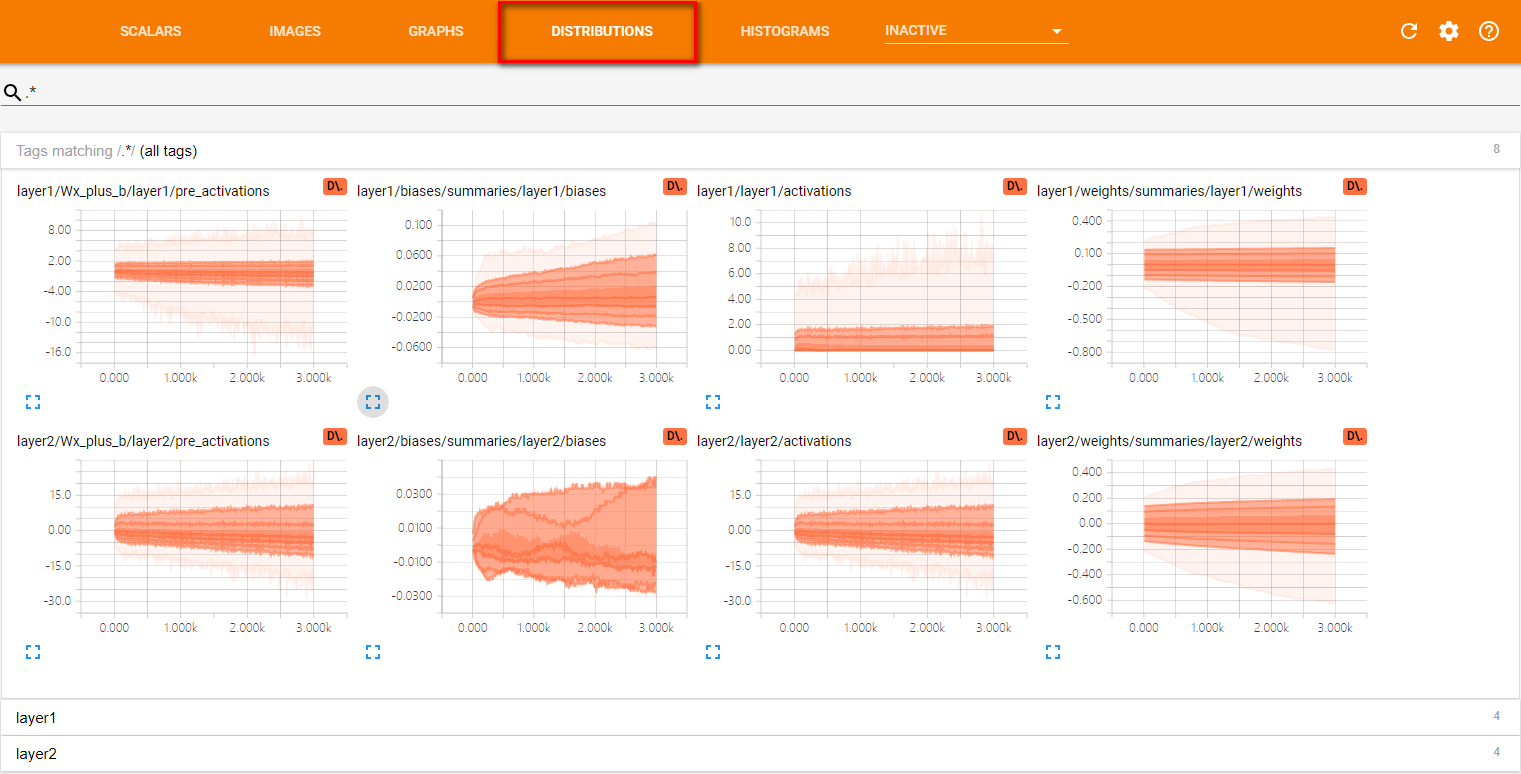
"""
对于layerl ,因为使用了ReLU函数作为激活函数,所以所有小于0的值部被设为了0。于是在激活后
的layerl/activations 图上所有的值都是大于0的。而对于layer2 ,因为没有使用激活函数,
所以layer2/activations 和layer2/pre_activations 一样。
"""
tf.summary.histogram(layer_name + '/activations', activations)
return activations
def main():
mnist = input_data.read_data_sets("./datasets/MNIST_data", one_hot=True)
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
# 将输入变量还原成图片的像素矩阵,并通过tf.iamge_summary函数定义将当前的图片信息写入日志的操作
hidden1 = nn_layer(x, 784, 500, 'layer1')
y = nn_layer(hidden1, 500, 10, 'layer2', act=tf.identity)
# 计算交叉熵并定义生成交叉熵监控日志的操作。
with tf.name_scope('cross_entropy'):
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_))
tf.summary.scalar('cross_entropy', cross_entropy)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
"""
计算模型在当前给定数据上的正确率,并定义生成正确率监控日志的操作。如果在sess.run()
时给定的数据是训练batch,那么得到的正确率就是在这个训练batch上的正确率;如果
给定的数据为验证或者测试数据,那么得到的正确率就是在当前模型在验证或者测试数据上
的正确率。
"""
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# tf.scalar_summary,tf.histogram_summary,tf.image_summary函数都不会立即执行,需要通过sess.run来调用这些函数
# 因为程序重定义的写日志的操作非常多,一一调用非常麻烦,所以Tensorflow提供了tf.merge_all_summaries函数来整理所有的日志生成操作。
# 在Tensorflow程序执行的过程中只需要运行这个操作就可以将代码中定义的所有日志生成操作全部执行一次,从而将所有日志文件写入文件。
merged = tf.summary.merge_all()
with tf.Session() as sess:
# 初始化写日志的writer,并将当前的Tensorflow计算图写入日志
summary_writer = tf.summary.FileWriter(SUMMARY_DIR, sess.graph)
tf.global_variables_initializer().run()
for i in tqdm.tqdm(range(TRAIN_STEPS)):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
# 运行训练步骤以及所有的日志生成操作,得到这次运行的日志。
summary, _ = sess.run([merged, train_step], feed_dict={x: xs, y_: ys})
# 将得到的所有日志写入日志文件,这样TensorBoard程序就可以拿到这次运行所对应的
# 运行信息。
summary_writer.add_summary(summary, i)
summary_writer.close()
if __name__ == '__main__':
main()
TensorFlow日志生成函数与Tensorboard界面栏对应关系

按命名空间分类的监控指标
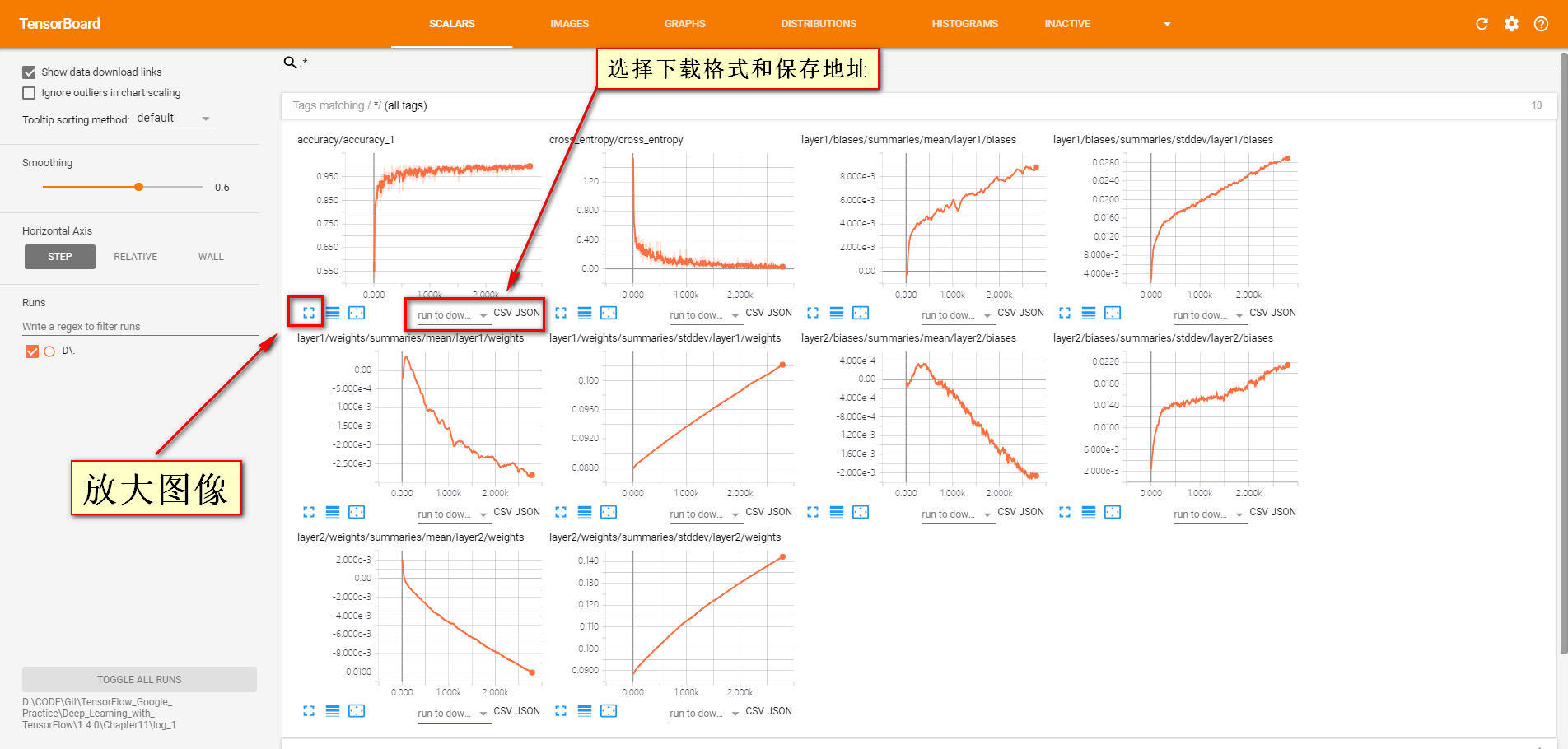
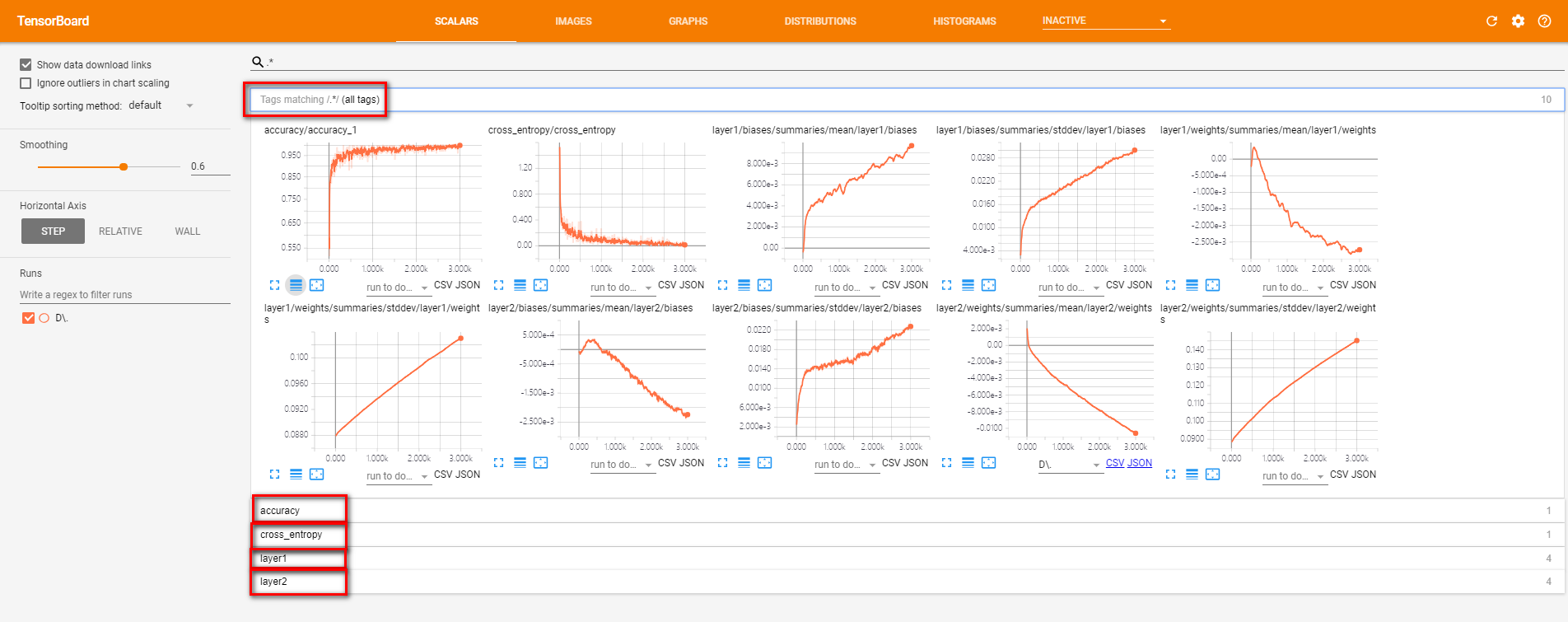
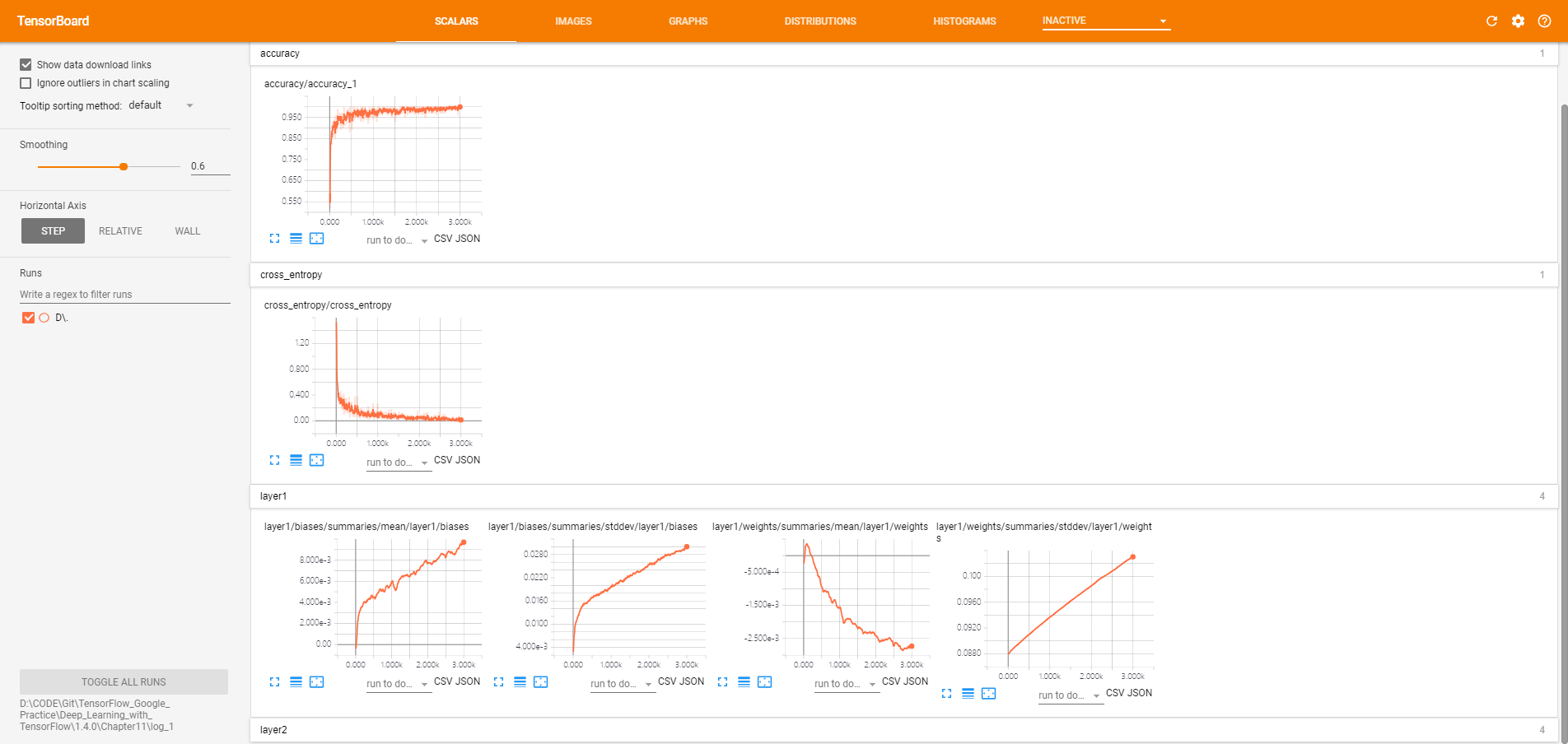
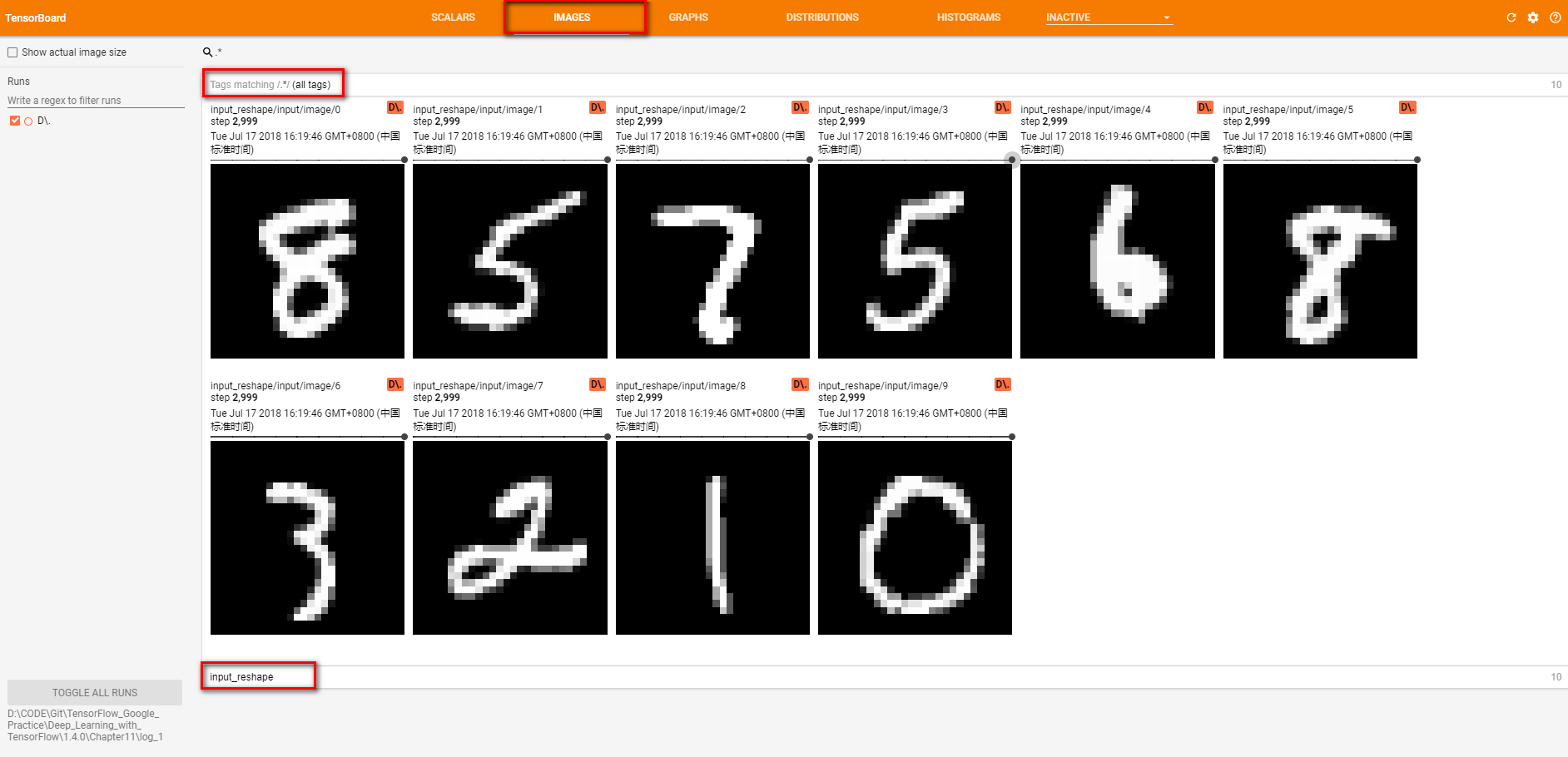

Tensorboard教程:监控指标可视化的更多相关文章
- 吴裕雄--天生自然深度学习TensorBoard可视化:监控指标可视化
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 1. 生成变量监控信息并定义生 ...
- Spring Boot 2.x监控数据可视化(Actuator + Prometheus + Grafana手把手)
TIPS 本文基于Spring Boot 2.1.4,理论支持Spring Boot 2.x所有版本 众所周知,Spring Boot有个子项目Spring Boot Actuator,它为应用提供了 ...
- 【转载】apache kafka系列之-监控指标
原文地址:http://blog.csdn.net/lizhitao/article/details/24581907 1.监控目标 1.当系统可能或处于亚健康状态时及时提醒,预防故障发生 2.报警提 ...
- apache kafka系列之-监控指标
apache kafka中国社区QQ群:162272557 1.监控目标 1.当系统可能或处于亚健康状态时及时提醒,预防故障发生 2.报警提示 a.短信方式 b.邮件 2.监控内容 2.1 机器监控 ...
- Linux CPU监控指标
Linux CPU监控指标 Linux提供了非常丰富的命令可以进行CPU相关数据进行监控,例如:top.vmstat等命令.top是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执 ...
- 关于kafka生产者相关监控指标的理解(未解决)
关于生产者相关的监控指标含义的理解,希望大神帮忙进行确定下. 这边找了官网,看了网上各样的资料,但都无法帮我理解监控项目相关含义. 相关的监控项目是从jconsole获取的,并接入到了 ...
- Hadoop记录- zookeeper 监控指标
目前zookeeper获取监控指标已知的有两种方式: 1.通过zookeeper自带的 four letter words command 获取各种各样的监控指标 2.通过JMX Client连接zo ...
- 【MySQL】常用监控指标及监控方法
对之前生产中使用过的MySQL数据库监控指标做个小结. 指标分类 指标名称 指标说明 性能类指标 QPS 数据库每秒处理的请求数量 TPS 数据库每秒处理的事务数量 并发数 数据库实例当前并行处理的 ...
- Hadoop记录-Hadoop集群重要监控指标
通用监控指标 对于每个RPC服务应该监控 RpcProcessingTimeAvgTime(PRC处理的平均时间) 通常hdfs在异常任务突发大量访问时,这个参数会突然变得很大,导致其他用户访问hdf ...
随机推荐
- angularjs工作原理解析
个人觉得,要很好的理解AngularJS的运行机制,才能尽可能避免掉到坑里面去.在这篇文章中,我将根据网上的资料和自己的理解对AngularJS的在启动后,每一步都做了些什么,做一个比较清楚详细的解析 ...
- nginx配置,php安装
yum -y install libxml2 libxml2-develyum -y install libxslt-devel yum -y install bzip2-devel yum -y i ...
- 安装cocoa pods
1.移除现有Ruby默认源 $gem sources --remove https://rubygems.org/ 2.使用新的源 $gem sources -a https://ruby.taoba ...
- HDU 5636 Shortest Path
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=5636 题解: 1.暴力枚举: #include<cmath> #include<c ...
- HDU 5206 Four Inages Strategy 水题
题目链接: hdu:http://acm.hdu.edu.cn/showproblem.php?pid=5206 bc(中文):http://bestcoder.hdu.edu.cn/contests ...
- Spring学习(七)——增强类
Spring 切点 什么是切点?切点(Pointcut),每个程序类都拥有多个连接点,如一个拥有两个方法的类,这两个方法都是连接点,即连接点是程序类中客观存在的事物.但在这为数从多的连接点中,如何定位 ...
- Beta阶段冲刺第一天
提供当天站立式会议照片一张 讨论项目每个成员的昨天进展 昨天开始了Beta阶段的冲刺,总体讨论了一下这个阶段的任务,然后明确了个人分工. 讨论项目每个成员的存在问题 第一天暂时还没有什么问题,可能最大 ...
- rfid工作原理
RFID的工作原理是:标签进入磁场后,如果接收到阅读器发出的特殊射频信号,就能凭借感应电流所获得的能量发送出存储在芯片中的产品信息(即Passive Tag,无源标签或被动标签),或者主动发送某一频率 ...
- beta阶段评语
首先我说一下自己心中的排序 1.俄罗斯方块 2 连连看 3 考试管理系统 4 食物链教学软件 5 约跑App 6 礼物挑选小工具 我的理由: 新峰的俄罗斯的方块,虽然当初的亮点没做出来,但是整体流程完 ...
- 【beta】Scrum站立会议第7次....11.9
小组名称:nice! 组长:李权 成员:于淼 刘芳芳韩媛媛 宫丽君 项目内容:约跑app(约吧) 时间:2016.11.9 12:00——12:30 地点:传媒西楼220室 本次对beta阶段 ...