牛B三人组-快速排序-堆排序-归并排序
快速排序
- 随便取个数,作为标志值,这里就默认为索引位置为0的值
- 记录左索引和右索引,从右往左找比标志值小的,小值和左索引值交换,右索引变化,然后从左往右找比标志值大的,大值和右索引值交换,左索引变化
- 循环第二步骤直到左索引和右索引碰头,标志值和当期左索引(右)交换,这样一个循环下,就得出一个标志值左边都比它小,右边都比大的数据样本
- 利用递归,对数据进行上述过程的最终标志值索引分割,分割到递归底层只有两个数,那么上述过程排序就一定有序了
实现要点:随机取标志值,循环右取小、左取大,利用左右索引碰头位置进行递归分割
def partition(li, left, right):
tmp = li[left]
while left < right:
while left < right and li[right] >= tmp: #从右面找比tmp小的数
right -= 1 # 往左走一步
li[left] = li[right] #把右边的值写到左边空位上
# print(li, 'right')
while left < right and li[left] <= tmp:
left += 1
li[right] = li[left] #把左边的值写到右边空位上
# print(li, 'left')
li[left] = tmp # 把tmp归位
return left def _quick_sort(li, left, right):
if left<right: # 至少两个元素
mid = partition(li, left, right)
_quick_sort(li, left, mid-1)
_quick_sort(li, mid+1, right)
快速排序一般情况很快,但是遇到最坏情况(倒序的情况),算法复杂度为O(n2),最好的情况(正序),算法复杂度为O(n)
快速排序有可能超过最大递归深度
堆排序
堆排序难点就是有一堆的概念需要你理解,开始前,那就必须讲讲概念了
树结构:我们程序见到的结构很像生活中的树,不过这里的是倒挂的,根在上,叶子在下,而根,在结构中,我们称为根节点,叶子称为叶子节点,中间的为枝节点
满二叉树和完全二叉树:
- 二叉树,就是每个节点最多两个枝节点或叶子节点
- 深度k,数下树有多少层,比如下图就是深度为4
- 满二叉树,除最后一层叶子节点,其他层节点都有两个子节点,节点数满足2^k-1
- 完全二叉树,节点数满足至少有2k-1个,至多有2k-1个,最后一层叶子节点可缺,但是这个缺,要连续缺,比如上图,缺7或缺67或缺567
大根堆和小根堆:
- 大根堆:满足父节点都比子节点大的完全二叉树
- 小根堆:满足父节点都比子节点小的完全二叉树
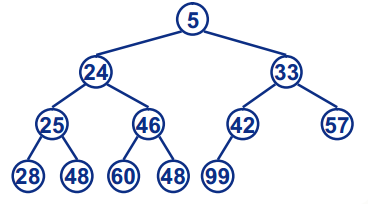
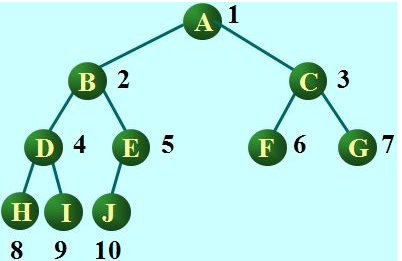
树的存储:存储时,我们用的就是列表存储,不过你会想,那怎么体现树的结构在里面的呢?从根节点开始,根节点放入索引位置为0的地方,下一层,从左为右依次放入,就如下图
树的存储规律:
- 已知父节点位置为i,获取左子节点位置为:2i+1,获取右子节点位置为:2i+2
- 已知子节点位置为i,获取父节点:无论这个子节点是左子还是右子,(i-1) // 2
堆的向下调整和建堆
由于刚开始拿到堆并不满足大根堆(大根堆用于从小到大排序,因为每次取完根节点最大数都是放在树的最后位置,也就是列表的最后位置,小根堆则用于从大到小排序)的情况,所以还需要了解堆的向下调整和建堆
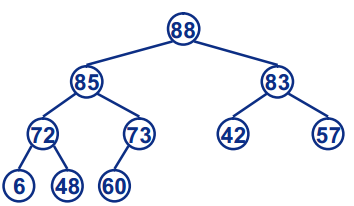
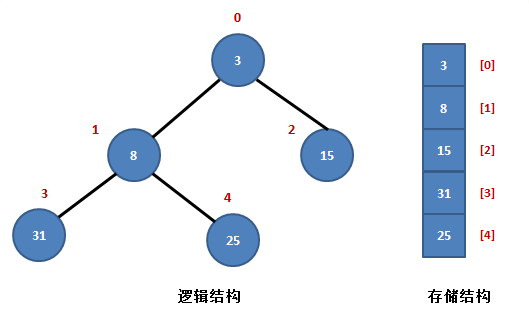
- 堆的向下调整,如下图,刚开始堆不满足大根堆,因为不满足根节点30比47,91大,所以需要进行向下调整,第一步:左右子节点比较,91大,并且大于根节点,发生位置交换 第二步:30下一层左右子节点比较,85大,也比30大,发生位置交换
经过上面过程,此时的堆就是大根堆了,不过这个调整过程有个前提,就是根节点下的子堆已经满足大根堆的条件,建立这个条件,我们叫建堆
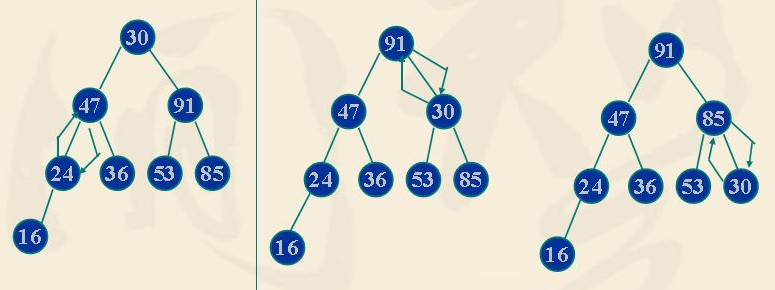
- 建堆:过程就要从底层的堆开,好比民主选择样,先从村选村长,再从村长中选县长,层层推举上去,如下图
第一步:85-91堆选举,91大,当村长,91目前就是村长,不用换
第二步:12-24-30堆选举,30大,当县长,情况满足不用换
第三步:85-47-91-36堆选举,91大,当县长,36-91交换,而且36比85小,村长也当不了,85-36交换,该过程就是向下调整的过程,村级对满足大根堆条件
第四步:整个堆推选市长,53小,又是向下调整的过程

所以建堆本质上也就是小堆基础上进行向下调整就能达到建堆的目的
代码实现要点:
- 堆向下调整:堆调整的上下边界,循环过程从2i+1左子节点开始,左右(前提是有右子)子节点比较大小-然后和父节点值比较确定是否交换
- 建堆:确定最后叶子节点(n-1)的父节点((n-2) // 2), 倒序循环调用向下调整
- 取数:根节点数与最后位置发生交换,调用向下调整(注意下边界high的变化,排除取好的最大数在调整范围)
def sift(li, low, high):
"""
:param li: 列表
:param low: 堆的根节点位置
:param high: 堆的最后一个元素的位置
:return:
"""
i = low # i最开始指向根节点
j = 2 * i + 1 # j开始是左孩子
tmp = li[low] # 把堆顶存起来
while j <= high: # 只要j位置有数
if j + 1 <= high and li[j+1] > li[j]: # 如果右孩子有并且比较大
j = j + 1 # j指向右孩子
if li[j] > tmp:
li[i] = li[j]
i = j # 往下看一层
j = 2 * i + 1
else: # tmp更大,把tmp放到i的位置上
li[i] = tmp # 把tmp放到某一级领导位置上
break
else:
li[i] = tmp # 把tmp放到叶子节点上 def heap_sort(li):
n = len(li)
for i in range((n-2)//2, -1, -1):
# i表示建堆的时候调整的部分的根的下标
sift(li, i, n-1)
# 建堆完成了
for i in range(n-1, -1, -1):
# i 指向当前堆的最后一个元素
li[0], li[i] = li[i], li[0]
sift(li, 0, i - 1) #i-1是新的high li = [i for i in range(100)]
import random
random.shuffle(li)
print(li) heap_sort(li)
print(li)
利用堆排序解决topK问题
思路:需要多少k,就建立以k个节点的小根堆,循环剩下数,如果比当前堆的根节点大,放入堆中,进行向下调整
def sift(li, low, high):
i = low
j = 2 * i + 1
tmp = li[low]
while j <= high:
if j + 1 <= high and li[j+1] < li[j]:
j = j + 1
if li[j] < tmp:
li[i] = li[j]
i = j
j = 2 * i + 1
else:
break
li[i] = tmp def topk(li, k):
heap = li[0:k]
for i in range((k-2)//2, -1, -1):
sift(heap, i, k-1)
# 1.建堆
for i in range(k, len(li)-1):
if li[i] > heap[0]:
heap[0] = li[i]
sift(heap, 0, k-1) # 2.遍历
for i in range(k-1, -1, -1):
heap[0], heap[i] = heap[i], heap[0]
sift(heap, 0, i - 1)
# 3.出数
return heap import random
li = list(range(1000))
random.shuffle(li) print(topk(li, 10))
归并排序
归并排序的原理是两个已经有序的列表合并为大的有序列表,合并过程中,两个列表各自最小的数进行比较,把小的放入到一个新的列表
归并排序分为两个过程:拆分过程和合并过程,拆分过程好弄,就按一半一半的拆,直到底层为一个数的列表,此时开始合并,此时合并的前提--两个有序的列表已经满足
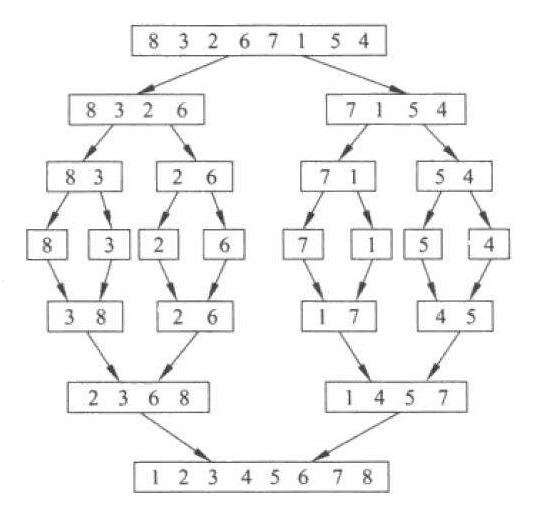
代码实现点:利用递归一半一半的分,合并:确定两个列表的边界范围,两个各取最小数进行比较-小的添加到新列表-对应的索引变化
注意:肯定有一边的数因为普遍小,先循环完,所以最后只要还有数的列表进行循环添加就可以了
def merge(li, low, mid, high):
i = low
j = mid + 1
ltmp = []
while i<=mid and j<=high: # 只要左右两边都有数
if li[i] < li[j]:
ltmp.append(li[i])
i += 1
else:
ltmp.append(li[j])
j += 1
# while执行完,肯定有一部分没数了
while i <= mid:
ltmp.append(li[i])
i += 1
while j <= high:
ltmp.append(li[j])
j += 1
li[low:high+1] = ltmp # li = [2,4,5,7,1,3,6,8]
# merge(li, 0, 3, 7)
# print(li) def merge_sort(li, low, high):
if low < high: #至少有两个元素,递归
mid = (low + high) //2
merge_sort(li, low, mid)
merge_sort(li, mid+1, high)
merge(li, low, mid, high) li = list(range(1000))
import random
random.shuffle(li)
print(li)
merge_sort(li, 0, len(li)-1)
print(li)
牛B三人组-快速排序-堆排序-归并排序的更多相关文章
- 排序算法Nb三人组-快速排序
核心思想: 将列表中第一个元素拿出来,放到一边,左右两个循环,左面的大于拿出来的数,就把他挪到右面, 右面的小于拿出来的数就把他放在左面,这是列表被第一个元素''分''为两个列表,在对两个列表进行同样 ...
- 排序NB三人组
排序NB三人组 快速排序,堆排序,归并排序 1.快速排序 方法其实很简单:分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”.先从右往左找一个小于6的数,再从左往 ...
- 列表排序之NB三人组附加一个希尔排序
NB三人组之 快速排序 def partition(li, left, right): tmp = li[left] while left < right: while left < ri ...
- 1、算法介绍,lowB三人组,快速排序
1.什么是算法 2.递归 # 一直递归,递归完成再打印 def func4(x): if x > 0: func4(x - 1) print(x) func4(5) 3.时间 复杂度 (1)引入 ...
- 算法 排序lowB三人组 冒泡排序 选择排序 插入排序
参考博客:基于python的七种经典排序算法 [经典排序算法][集锦] 经典排序算法及python实现 首先明确,算法的实质 是 列表排序.具体就是操作的列表,将无序列表变成有序列表! 一 ...
- 算法排序-NB三人组
快速排序: 堆排序: 二叉树: 两种特殊二叉树: 二叉树的存储方式: 小结: 堆排序正题: 向下调整: 堆排序过程: 堆排序-内置模块: 扩展问题topk: 归并排序: 怎么使用: NB三人组小结
- Java实现单链表的快速排序和归并排序
本文描述了LeetCode 148题 sort-list 的解法. 题目描述如下: Sort a linked list in O(n log n) time using constant space ...
- 排序算法之low B三人组
排序low B三人组 列表排序:将无序列表变成有充列表 应用场景:各种榜单,各种表格,给二分法排序使用,给其他算法使用 输入无序列表,输出有序列表(升序或降序) 排序low B三人组 1. 冒泡排序 ...
- kill、killall、pkill杀手三人组
1.1 kill.killall.pkill杀手三人组 1.利用kill 进程号 方式杀掉rsync进程 [root@backup ~]# ps -ef |grep rsync root 3500 1 ...
随机推荐
- js基本知识4
1. 数组 看电影 电影院 座位 大的变量 里面可以放很多的值 var arr = [1,3,57]; var ar = new Array(); new object(); new Date() v ...
- bash之局部变量与子shell(转载)
shell是每个接触linux.unix用户不得不会的工具,谈到shell就又联系到bash,因为这个shell是普遍被使用的.那么bash中的局部变量和子shell你是否能熟练掌握呢?这里推荐一本学 ...
- Dubbo源代码实现三:注册中心Registry
我们知道,对于服务治理框架来说,服务通信(RPC)和服务管理两部分必不可少,而服务管理又分为服务注册.服务发现和服务人工介入,我们来看看Dubbo框架的结构图(来源网络): 图中可以看出,服务提供者P ...
- aix 常用命令
官网上的介绍: AIX 常用命令汇总 http://www.ibm.com/developerworks/cn/aix/library/au-dutta_cmds.html 我们先SSH 到AIX 系 ...
- MapReduce编程实例6
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- 利用 jQuery 克隆 Object
在网上搜索关键字 “javascript object clone”,可以找到很多实现克隆 Object 的代码,可是据我测试,让人满意的几乎没有. 今天发现 jQuery 的作者 John Resi ...
- [shell]简单的shell提示和参数脚本
该shell脚本有如下点: bash or dash case语句的写法 脚本help写法 参数是否为空的写法 算数运算的写法 #! /bin/bash case "$1" in ...
- Android——Activity恢复用户用EditText输入的数据
说明: 在横屏输入的内容,在Activity销毁后,即横屏后,获取用户输入的内容 步骤: 1.在xml页面定义EditText的id 2.用onSaveInstanceState保存用户输入的数据 ( ...
- Android——Android studio项目中如何查看R.java文件(转)
Android Studio 是Google推出的一个Android开发环境,它集成了Android 开发工具用于开发和调试,类似 Eclipse ADT.Google公司停止对eclipse的后续支 ...
- 一个性能较好的JVM参数配置(转)
一个性能较好的web服务器jvm参数配置: -server//服务器模式-Xmx2g //JVM最大允许分配的堆内存,按需分配-Xms2g //JVM初始分配的堆内存,一般和Xmx配置成一样以避免每次 ...