Scrapy 分布式数据采集方案
运行环境 CentOS7. + Python2. + Scrapy1. + MongoDB3. + BeautifulSoup4.
编程工具 PyCharm + Robomongo + Xshell 请确保你的 python版本为2..5以上 版本
强烈推荐直接【翻 墙 安 装】,简单轻松
yum install gcc libffi-devel python-devel openssl-devel
pip install scrapy 如果提示以下错误
AttributeError: 'module' object has no attribute 'OP_NO_TLSv1_1'
说明你的 Twisted 版本过高,请执行
pip install Twisted==16.4. 然后再安装以下内容
pip install scrapyd
pip install scrapy-mongodb
pip install beautifulsoup4
pip install scrapy-redis
pip install pymongo
pip install scrapyd-client
pip install Pillow
pip install python-scrapyd-api # windows下安装方法也是一样的,推荐顺手安装一下windows版本,这样在 IDE(PyCharm)下能够得到Scrapy的代码提示,而且不会报 类不存在 的错误 然后执行
scrapy startproject fusnion
就可以创建一个名为 funsion 的项目 附录A:Scrapy Shell 调试
Linux 命令行下输入(以本站点为例)
scrapy shell 'http://www.cnblogs.com/funsion/'
进入交互式shell,输入以下内容
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(response.body, 'html.parser')
>>> print soup.title
如果能输出 <title>Funsion Wu - 博客园</title> 则代表成功 附录B:参考文档
Scrapy 中文文档 http://scrapy-chs.readthedocs.org/zh_CN/latest/index.html
参考文档 https://piaosanlang.gitbooks.io/spiders/01day/README1.html
Scrapyd 文档 http://scrapyd.readthedocs.io/en/stable/
BeautifulSoup 中文手册 http://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
Scrapy-Redis 文档 http://scrapy-redis.readthedocs.io/en/stable/
Scrapy-Mongodb 文档 https://github.com/sebdah/scrapy-mongodb
Pillow 文档 http://pillow.readthedocs.io/en/latest/index.html
Python-Scrapyd-Api 文档 http://python-scrapyd-api.readthedocs.io/en/latest/
参考文档 http://www.pastandnow.com/2015/11/16/Use-Scrapyd-client-Deploy-Spider/ 附录C:mongodb安装方法
下载文件 https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-3.4.6.tgz
tar zxf mongodb-linux-x86_64-rhel70-3.4..tgz
cd mongodb-linux-x86_64-rhel70-3.4./
mkdir -p /data/{mongodb_data,mongodb_log}
ln -s /usr/local/src/mongodb-linux-x86_64-rhel70-3.4./bin/mongo /usr/local/bin/
nohup /usr/local/src/mongodb-linux-x86_64-rhel70-3.4./bin/mongod --dbpath=/data/mongodb_data --logpath=/data/mongodb_log/mongodb.log --logappend --fork > /dev/null >& &
编辑/etc/rc.local,加入下述代码然后再保存即可。
nohup /usr/local/src/mongodb-linux-x86_64-rhel70-3.4./bin/mongod --dbpath=/data/mongodb_data --logpath=/data/mongodb_log/mongodb.log --logappend --fork > /dev/null >& & 附录D:Scrapy代理解决方案
https://github.com/TeamHG-Memex/scrapy-rotating-proxies
https://github.com/luyishisi/Anti-Anti-Spider (防采集策略)
http://www.cnblogs.com/kylinlin/p/5242266.html (Scrapy+Tor防采集) 附录E:Scrapy-Demo地址
https://gitee.com/funsion_wu/demo/tree/master/scrapy
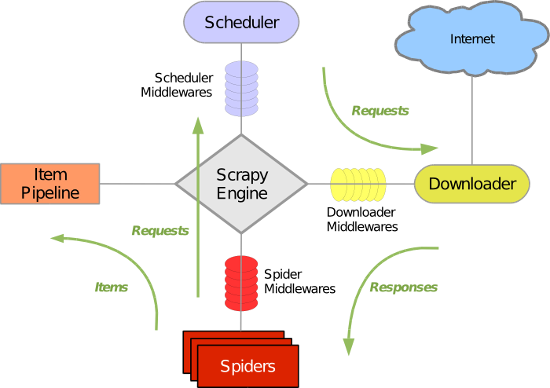
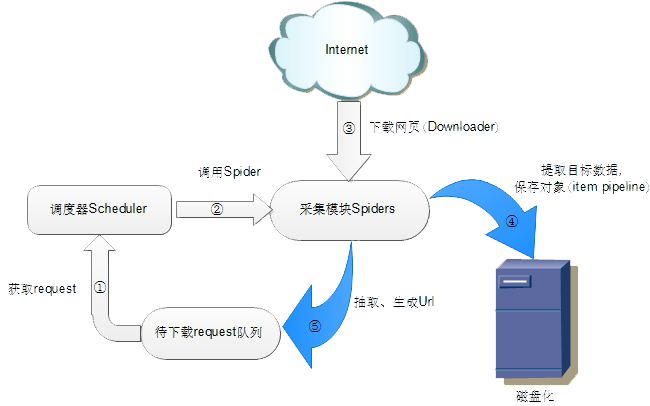
Scrapy架构图
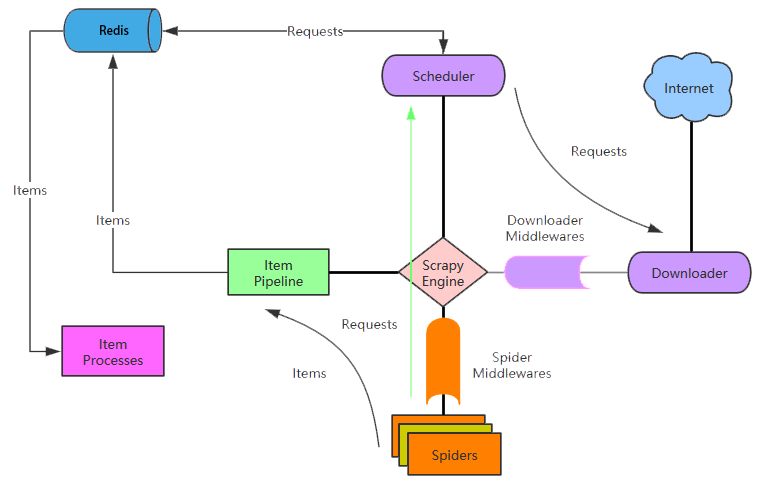
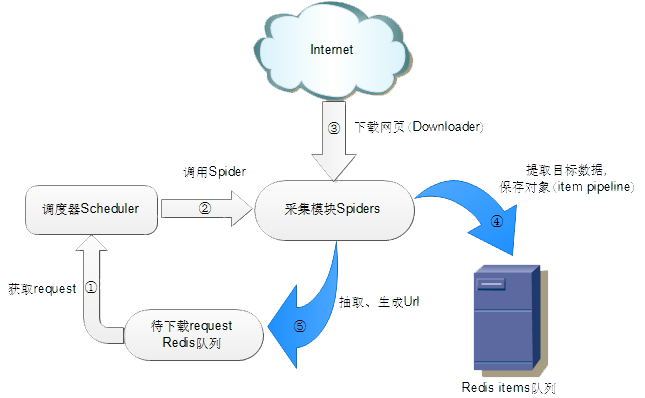
Scrapy-Redis架构图
Scrapy 分布式数据采集方案的更多相关文章
- Memcached常规应用与分布式部署方案
1.Memcached常规应用 $mc = new Memcache(); $mc->conncet('127.0.0.1', 11211); $sql = sprintf("SELE ...
- Window Redis分布式部署方案 java
Redis分布式部署方案 Window 1. 基本介绍 首先redis官方是没有提供window下的版本, 是window配合发布的.因现阶段项目需求,所以研究部署的是window版本的,其实都 ...
- Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- scrapy分布式的几个重点问题
我们之前的爬虫都是在同一台机器运行的,叫做单机爬虫.scrapy的经典架构图也是描述的单机架构.那么分布式爬虫架构实际上就是:由一台主机维护所有的爬取队列,每台从机的sheduler共享该队列,协同存 ...
- Python爬虫【五】Scrapy分布式原理笔记
Scrapy单机架构 在这里scrapy的核心是scrapy引擎,它通过里面的一个调度器来调度一个request的队列,将request发给downloader,然后来执行request请求 但是这些 ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 基于Solr和Zookeeper的分布式搜索方案的配置
1.1 什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud.当一个系统的索引数据量少的时候 ...
- ebay分布式事务方案中文版
http://cailin.iteye.com/blog/2268428 不使用分布式事务实现目的 -- ibm https://www.ibm.com/developerworks/cn/clou ...
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
随机推荐
- Python全栈day21(调用模块路径BASEDIR的正确方法)
正常写python程序会有一个可执行的bin.py文件,假如这个文件需要导入my_module里面定义的模块,应该怎么设置sys.path 文件夹目录结构如下,因为bin不在与my_module同级目 ...
- [linux基础学习]默认的目录介绍
以下用一个表格来罗列linux默认的目录或文件及其用途: 目录/文件 用途 来源 / /处于Linux文件系统树形结构的最顶端,它是Linux文件系统的入口,所有的目录.文件.设备都在/之下. - / ...
- python的@classmethod和@staticmethod
本文是对StackOverflow上的一篇高赞回答的不完全翻译,原文链接:meaning-of-classmethod-and-staticmethod-for-beginner Python面向对象 ...
- birt 日志打印
在birt初始initialize 方法里,定义日志输出方法 importPackage(Packages.java.util.logging); importPackage(Packages.log ...
- shell_01
定义变量: name='qwer' 不解析任何字符 name="qwer" 会解析$和\特殊字符 name1=123;name2=456 定义多个变量 now_date=`date ...
- HTML5开源RPG游戏引擎lufylegendRPG 0.1发布
一,小小开篇 首先不得不先介绍一下这个引擎: lufylegendRPG是lufylegend的拓展引擎,使用它时,需要引入lufylegend.同时您也需要了解lufylegend语法,这样才能 ...
- vxworks 的 socket, thread, 信号量模型
http://www.vxdev.com/docs/vx55man/vxworks/netguide/c-sockets.html http://www.vxdev.com/docs/vx55man/ ...
- python logging模块介绍
1.日志级别 日志一共分成5个等级,从低到高分别是:DEBUG INFO WARNING ERROR CRITICAL. DEBUG:详细的信息,通常只出现在诊断问题上 INFO:确认一切按预期运行 ...
- PAT 1145 Hashing - Average Search Time [hash][难]
1145 Hashing - Average Search Time (25 分) The task of this problem is simple: insert a sequence of d ...
- Yii 2.x 和1.x区别以及yii2.0安装
知乎上有个类似的问题:http://www.zhihu.com/question/22924271/answer/23085751 大致思路不会变,开发流程变化也不是很大.有变化的是1.yii2带入的 ...