python高级(三)—— 字典和集合(泛映射类型)
本文主要内容
可散列类型
泛映射类型
字典
(1)字典推导式
(2)处理不存在的键
(3)字典的变种
集合
映射的再讨论
文中代码均放在github上:https://github.com/ampeeg/cnblogs/tree/master/python高级
可散列类型
''' |
''' |
泛映射类型
''' |
''' |
''' |
字典
''' |
(1)字典推导式
''' |
(2)处理不存在的键
''' |
(3)字典的变种
''' |
集合
''' |
set的操作方法很多,本文截自<流畅的python>一书,如下三个表: 表一:集合的数学方法
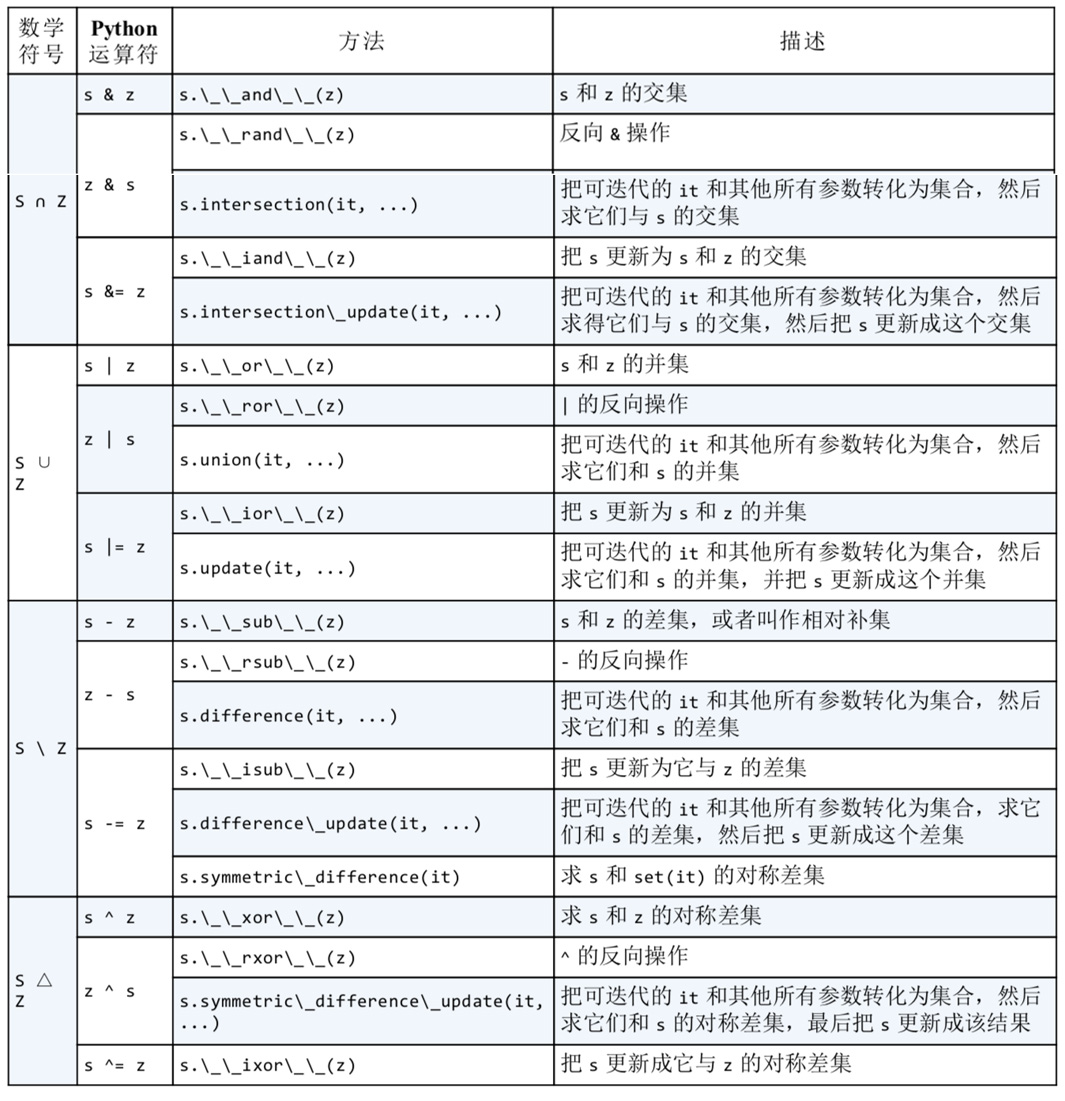 |
表2:集合的比较运算
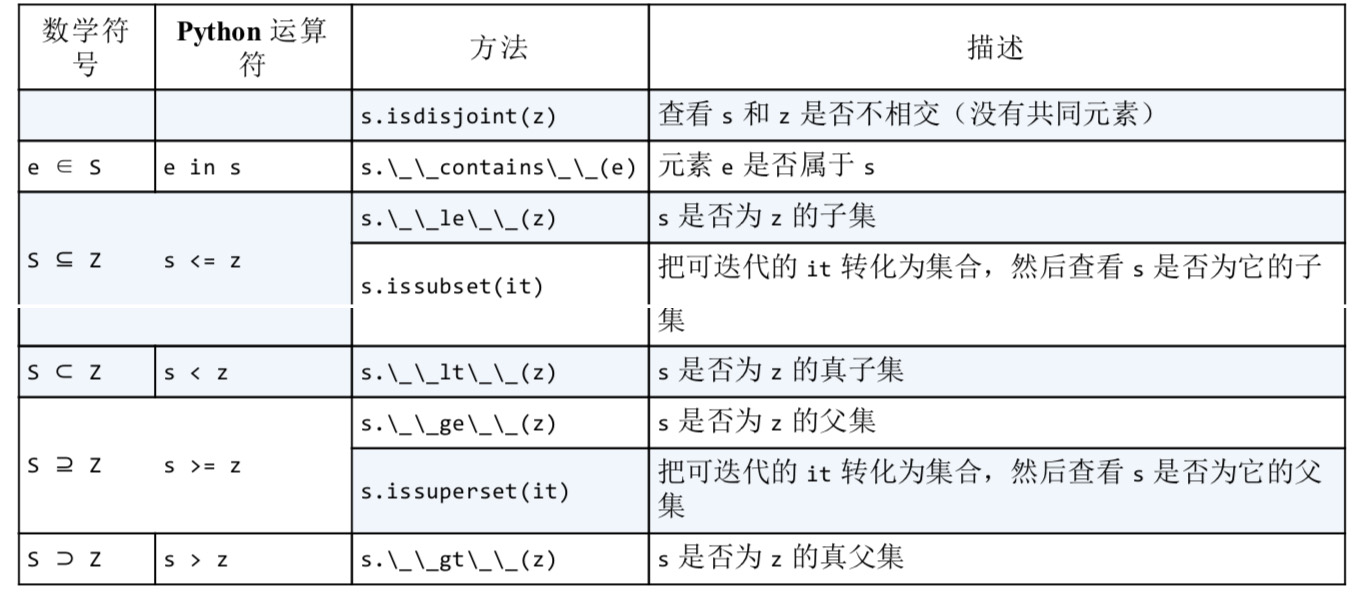 |
表3:集合的其他运算
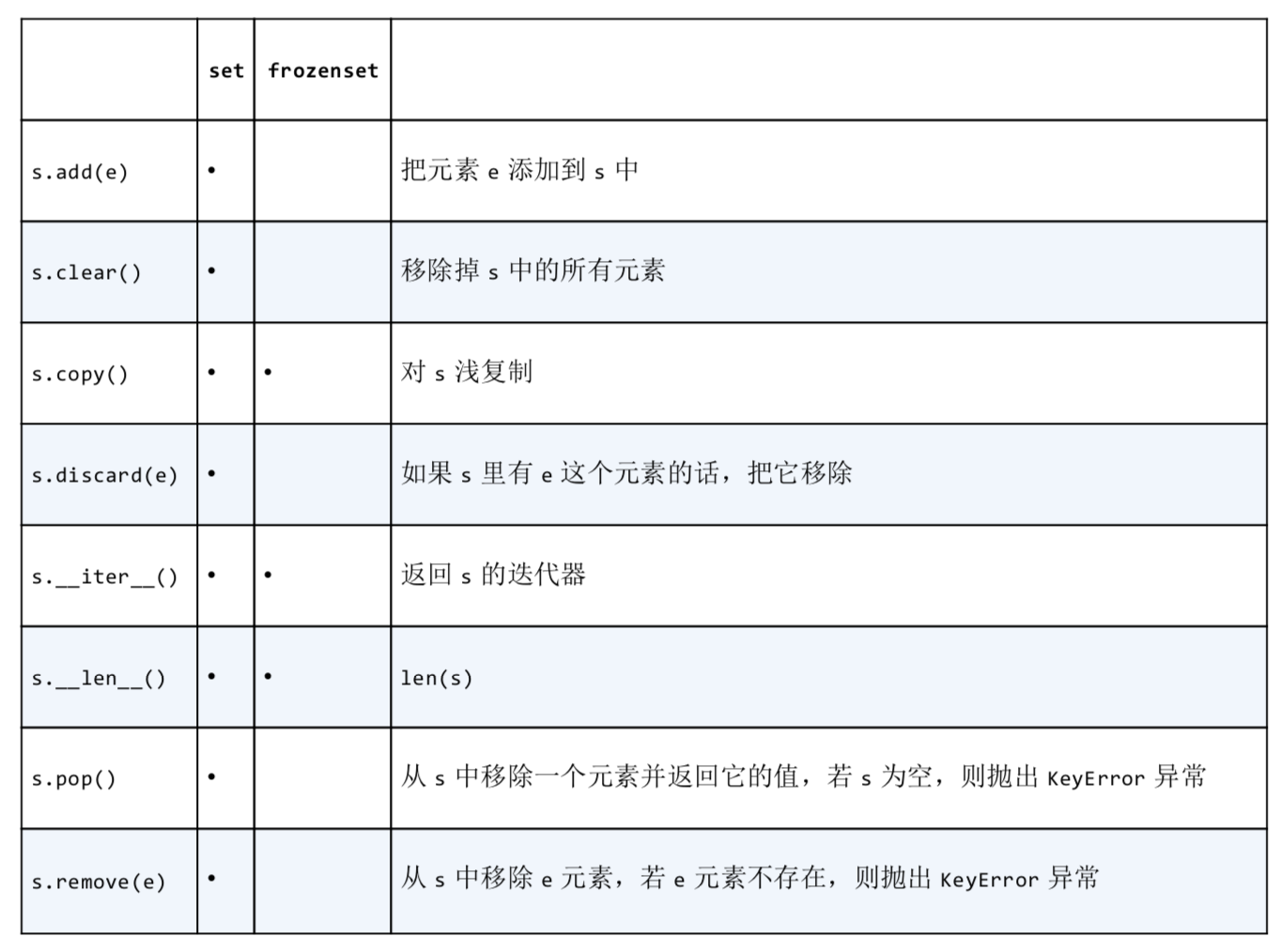 |
映射的再讨论
''' |
另外,《流畅的python》77页到80页对散列表算法以及字典、集合的效率、平时需要注意的问题进行了比较详细的探讨,建议严谨并有兴趣的同仁阅读,该部分内容对理解字典类型无比有益,场景中捉摸不透的莫名其妙的bug可能会迎刃而解。
重要的结论摘录如下:
(1)键必须是可散列的
(2)字典在内存上的开销巨大
(3)键查询很快
(4)键的次序取决于添加顺序
(5)往字典里添加新键可能会改变已有键的顺序
python高级系列文章目录
python高级(三)—— 字典和集合(泛映射类型)的更多相关文章
- Python中的字典与集合
今天我们来讲一讲python中的字典与集合 Dictionary:字典 Set:集合 字典的语法: Dictionary字典(键值对) 语法: dictionary = {key:value,key: ...
- Python基础__字典、集合、运算符
之前讨论的字符串.列表.元组都是有序对象,本节则重点讨论无序对象:字典与集合.一.字典 列表是Python中的有序集合,列表中的序指的是列表中的元素与自然数集形成了一个一一对应的关系.例如L=['I' ...
- python大法好——字典、集合
字典 前面我们说过列表,它适合于将值组织到一个结构中并且通过编号对其进行引用.字典则是通过名字来引用值的数据结构,并且把这种数据结构称为映射,字典中的值没有特殊的顺序,都存储在一个特定的键(key)下 ...
- Python数据类型(字典和集合)
1.5 Dictionary(字典) 在Python中,字典用放在花括号{}中一系列键-值对表示.键和值之间用冒号分隔,键-值对之间用逗号分隔. 在字典中,你想存储多少个键-值对都可以.每个键都与一个 ...
- [19/09/19-星期四] Python中的字典和集合
一.字典 # 字典 # 使用 {} 来创建字典 d = {} # 创建了一个空字典 # 创建一个保护有数据的字典 # 语法: # {key:value,key:value,key:value} # 字 ...
- python 数据类型三 (字典)
一.字典的介绍 字典(dict)是python中唯一的一个映射类型,它是以{}括起来的键值对组成,在dict中key是唯一的,在保存的时候,根据key来计算出一个内存地址,然后将key-value保存 ...
- python第三周:集合、函数、编码、文件
1.集合: 集合的创建: list_1 = set([1,2,3,4,5]) list_2 = set([2,3,44,7,8]) 集合的特性:集合是无序的,集合可以去掉重复的元素 集合的操作:求交集 ...
- Python中的字典和集合
一.字典(dict) 1. 概述 字典是Python唯一的映射类型. 只能使用不可变的对象(比如字符串)来作为字典的键,但是可以把不可变或可变的对象作为字典的值. 键值对在 ...
- python基础之字典、集合
一.字典(dictionary) 作用:存多个值,key-value存取,取值速度快 定义:key必须是不可变类型,value可以是任意类型 字典是一个无序的,可以修改的,元素呈键值对的形式,以逗号分 ...
- python初识数据类型(字典、集合、元组、布尔)与运算符
目录 python数据类型(dict.tuple.set.bool) 字典 集合 元组 布尔值 用户交互与输出 获取用户输入 输出信息 格式化输出 基本运算符 算术运算符 比较运算符 逻辑运算符 赋值 ...
随机推荐
- windows下 apache,php,mysql,phpadmin集成化安装
1.appserv 直接下载安装, 2.linux环境下下载安装LAMP
- Powerdesigner逆向工程从mysql生成PDM
大家喜欢用powerDesigner进行数据库建模.通常都是先设计出物理模型图,再转换出数据库需要的SQL语句,从而生成数据库.但“powerDesigner逆向工程”就能将数据库逆向转为物理模型图. ...
- BBS项目(2)
我们实现登录功能的随机验证码的产生 views.py def get_random_color(): return ( # 创建三个0-255的随机数 random.randint(0, 255), ...
- javascrip总结43:标签上自定义属性的操作
1 获取标签属性 语法: element.getAttribute('属性名') 返回对应属性的值 ,如果没有返回null. //html <div id="box" ind ...
- Android canvas bug
安卓4.1.1-4.1.2的webkit在渲染canvas元素时有bug. 具体表现是出现重影,即canvas的clearRect()方法不能彻底清空画布,仍然保留之前某个状态当“背景”. 目前的修复 ...
- zuluCryt cli howto
1.解锁卷的命令. zuluCrypt-cli -o -d /dev/sdc1 -m blabla -e ro -f /home/keyFile zuluCrypt-cli -o -d /dev/sd ...
- FileAppender
http://logback.qos.ch/manual/appenders.html#FileAppender <configuration> <appender name=&qu ...
- 设计模式13---桥接模式(Bridge Pattern)
桥接模式将抽象与具体实现分离,使得抽象与具体实现可以各自改变互不影响.桥接模式属于设计模式中的结构模式. 桥梁模式涉及的角色 抽象(Abstraction)角色:抽象定义,引用对接口对象的引用. 重新 ...
- poj—1753 (DFS+枚举)
...
- solr&lucene3.6.0源码解析(一)
本文作为系列的第一篇,主要描述的是solr3.6.0开发环境的搭建 首先我们需要从官方网站下载solr的相关文件,下载地址为http://archive.apache.org/dist/luc ...