Hadoop1.2.1 伪分布式安装
Hadoop组件依赖图(从下往上看)

安装步骤:


详细步骤:
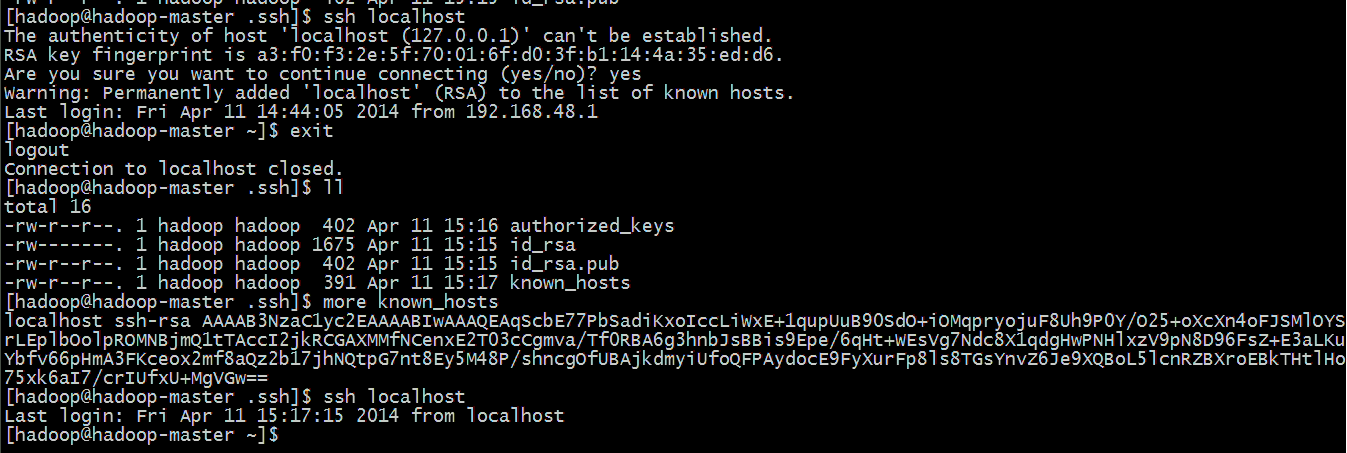
设置ssh自动登录(如下图):
1、输入命令 【ssh-keygen -t rsa】,然后一直按回车就可以了
2、然后切换目录到 ~ .ssh目录下执行命令【cp id_rsa.pub authorized_keys】
3、这样就完成了,然后测试
1) 输入命令【ssh localhost】,然后输入【yes】,就会登陆成功另外会看到原本的 .ssh目录变成了 ~ 目录
2) 输入命令【exit】退出,然后还是在以前的.ssh目录下,这时候输入ll会发现多了一个 known_hosts文件,顾名思义。
3) 然后再次输入命令【ssh localhost】就可以直接登录了,当然还可以【ssh ip地址】、【ssh 主机名】等等,只需第一次输入【yes】,之后就可以直接登录了。
下面进行hadoop相关文件配置:
1、配置 hadoop 环境文件 hadoop-env.sh

1) 打开文件,找到某行有 ”# export JAVA_HOME = ...” 字样的地方,去掉 “#” ,然后在等号后面填写你自己的 JDK 路径,比如像我自己的 JDK 路径,那就改为了 如下所示
export JAVA_HOME=/opt/modules/jdk1.7.0_45
2) 配置 Hadoop 的核心文件 core-site.xml
打开文件,会发现标签 <configuration></configuration> 中是空的,在空的地方添加如下配置
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master.dragon.org:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
</configuration>
2、

上面配置项是 hdfs副本数(默认为3),下面配置项为 是否进行权限检查
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
3、

<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master.dragon.org:9001</value>
</property>
</configuration>
当然下面两个也可以用默认配置
hadoop-master.dragon.org
hadoop-master.dragon.org
到这里,基本就算配置完毕了
测试:
首先格式化:hadoop namenode -format
然后启动:

初步学习安装可以一步一步来(在hadoop的bin目录下)
可先启动start-dfs.sh
然后可输入jps观察如下

可在浏览器 输入 http://192.168.1.123:50070看到相关信息(当然也可以输入域名等)
然后启动start-mapred.sh
然后可输入jps观察如下

可在浏览器 输入 http://192.168.1.123:50030看到相关信息(当然也可以输入域名等)
好了,到这里伪分布式环境搭建就算结束了。
Hadoop1.2.1 伪分布式安装的更多相关文章
- Hadoop1.1.2伪分布式安装
一.安装前准备设置Linux的静态IP修改VirtualBox的虚拟网卡地址修改主机名把hostname和ip绑定关闭防火墙:service iptables stop二.SSH免密码登陆生成秘钥文件 ...
- Hadoop1.1.2伪分布式安装笔记
一.设置Linux的静态IP 修改桌面图标修改,或者修改配置文件修改 1.先执行ifconfig,得到网络设备的名称eth0 2.编辑/etc/sysconfig/network-scripts/if ...
- Hadoop1.0.4伪分布式安装
前言: 目前,学习hadoop的目的是想配合其它两个开源软件Hbase(一种NoSQL数据库)和Nutch(开源版的搜索引擎)来搭建一个知识问答系统,Nutch从指定网站爬取数据存储在Hbase数据库 ...
- redhat 安装hadoop1.2.1伪分布式
完整安装过程参考:http://www.cnblogs.com/shishanyuan/p/4147580.html 一.环境准备 1.安装linux.jdk 2.下载hadoop2. ...
- hadoop伪分布式安装之Linux环境准备
Hadoop伪分布式安装之Linux环境准备 一.软件版本 VMare Workstation Pro 14 CentOS 7 32/64位 二.实现Linux服务器联网功能 网络适配器双击选择VMn ...
- Hadoop开发第3期---Hadoop的伪分布式安装
一.准备工作 1. 远程连接工具的安装 PieTTY 是在PuTTY 基础上开发的,改进了Putty 的用户界面,提供了多语种支持.Putty 作为远程连接linux 的工具,支持SSH 和telne ...
- 第二章 伪分布式安装hadoop hbase
安装单机模式的hadoop无须配置,在这种方式下,hadoop被认为是一个单独的java进程,这种方式经常用来调试.所以我们讲下伪分布式安装hadoop. 我们继续上一章继续讲解,安装完先试试SSH装 ...
- HBase基础和伪分布式安装配置
一.HBase(NoSQL)的数据模型 1.1 表(table),是存储管理数据的. 1.2 行键(row key),类似于MySQL中的主键,行键是HBase表天然自带的,创建表时不需要指定 1.3 ...
- Zookeeper 初体验之——伪分布式安装(转)
原文地址: http://blog.csdn.net/salonzhou/article/details/47401069 简介 Apache Zookeeper 是由 Apache Hadoop 的 ...
随机推荐
- C#指南,重温基础,展望远方!(8)C#数组
数组是一种数据结构,其中包含许多通过计算索引访问的变量. 数组中的变量(亦称为数组的元素)均为同一种类型,我们将这种类型称为数组的元素类型. 数组类型是引用类型,声明数组变量只是为引用数组实例预留空间 ...
- 构造函数、析构函数、赋值与初始化、explicit关键字
一.构造函数.默认构造函数 (1).构造函数 构造函数是特殊的成员函数 创建类类型的新对象,系统自动会调用构造函数 构造函数是为了保证对象的每个数据成员都被正确初始化 函数名和类名完全相同 不能定义构 ...
- UVA10624 - Super Number(dfs)
题目:UVA10624 - Super Number(dfs) 题目大意:给你n和m要求找出这种m位数,从第n位到第m位都满足前i位是能够被i整除,假设没有这种数,输出-1.有多个就输出字典序最小的那 ...
- 温故而知新 chrome 浏览器一些小技巧、小细节
1.console 模块如何换行? shift + enter即可. 2.有时候 network 没有分类标签(xhr.img.js.css)怎么办? 按下这个图标就可以显示出来了
- MySQL中多表删除方法
如果您是才接触MySQL数据库的新人,那么MySQL中多表删除是您一定需要掌握的,下面就将为详细介绍MySQL中多表删除的方法,供您参考,希望对你学习掌握MySQL中多表删除能有所帮助. 1.从MyS ...
- Linux 进程资源用量监控和按用户设置进程限制
每个 Linux 系统管理员都应该知道如何验证硬件.资源和主要进程的完整性和可用性.另外,基于每个用户设置资源限制也是其中一项必备技能. 在这篇文章中,我们会介绍一些能够确保系统硬件和软件正常工作的方 ...
- android.animation(4) - ObjectAnimator的ofInt(), ofFloat()(转)
一.概述 1.引入 上几篇给大家讲了ValueAnimator,但ValueAnimator有个缺点,就是只能对数值对动画计算.我们要想对哪个控件操作,需要监听动画过程,在监听中对控件操作.这样使用起 ...
- 102. Linked List Cycle【medium】
Given a linked list, determine if it has a cycle in it. Example Given -21->10->4->5, tail ...
- vuex中store分文件时候index.js进行文件整合
import Vue from 'vue' import Vuex from 'vuex' Vue.use(Vuex); import getters from './getters.js' impo ...
- 【转】如何把hadoop-1.x源码关联到Eclipse工程
[转]http://www.tuicool.com/articles/mIb2EzU