Stylized Image Caption论文笔记
Neural Storyteller (Krios et al. 2015)
: NST breaks down the task into two steps, which first generate unstylish captions than apply style shift techniques to generate stylish descriptions.
SentiCap: Generating Image Descriptions with Sentiments (AAAI 2016)
代码和数据都有公布. (代码用的是比较老的框架,没有读。)
Supervised Image Caption
Style: Positive, Negtive
Datasets:
MSCOCO
SentiCap Dataset:作者自己收集的一个数据集 (数据量不大,Positive: 998 images/2873 captions for train, 673 images/2019 captions for test, Negtive: 997 images/2468 captions for train, 503 images/ 1509 captions for test) 3 positive and 3 negative captions per image
This is done in a caption re-writing task based upon objective captions from MSCOCO by asking AMT workers to choose among ANPs of the desired sentiment, and incorporate one or more of them into any one of the five existing captions.
Evaluation Metrics:
Automatic metrics: BLEU, ROUGEL, METEOR, CIDEr
Human evaluation
Model


Shortcomings: requires paired image-sentiment caption data, but also world-level supervison to emphsize the sentiment words(e.g., sentiment strengths of each word in the sentiment caption), which makes the approach very expensive and difficult to scale up.(StyleNet)
StyleNet: Generating Attractive Visual Captions with Styles (CVPR2017)
代码没有公布,有第三方Pytorch实现,数据集公布了FlickrStyle9K(1k测试数据没有公开)
Unsupervised(without using supervised style-specific image-caption paired data): factual image caption pairs + stylized language corpus(only text)
Produce attractive visual captions with styles only using monolingual stylized language corpus(without paired images) and standard factual image/video-caption pairs.
Style:Romantic, Humorous
Datasets:
FlickrStyle10K(built on Flickr 30K image caption dataset, show a standard factual caption for a image, to revise the caption to make it romantic or humorous)(这里虽然有image-stylized caption pairs,但训练的时候作者并没有用这些成对的数据,而是用image-factual caption pairs + stylized text corpora,在evaluate的时候会用到image-stylized caption pairs,用作Ground Truth.)
Evaluation Metrics:
Automatic Metrics:BLEU, METEOR, ROUGE, CIDEr
Human evaluation
Model
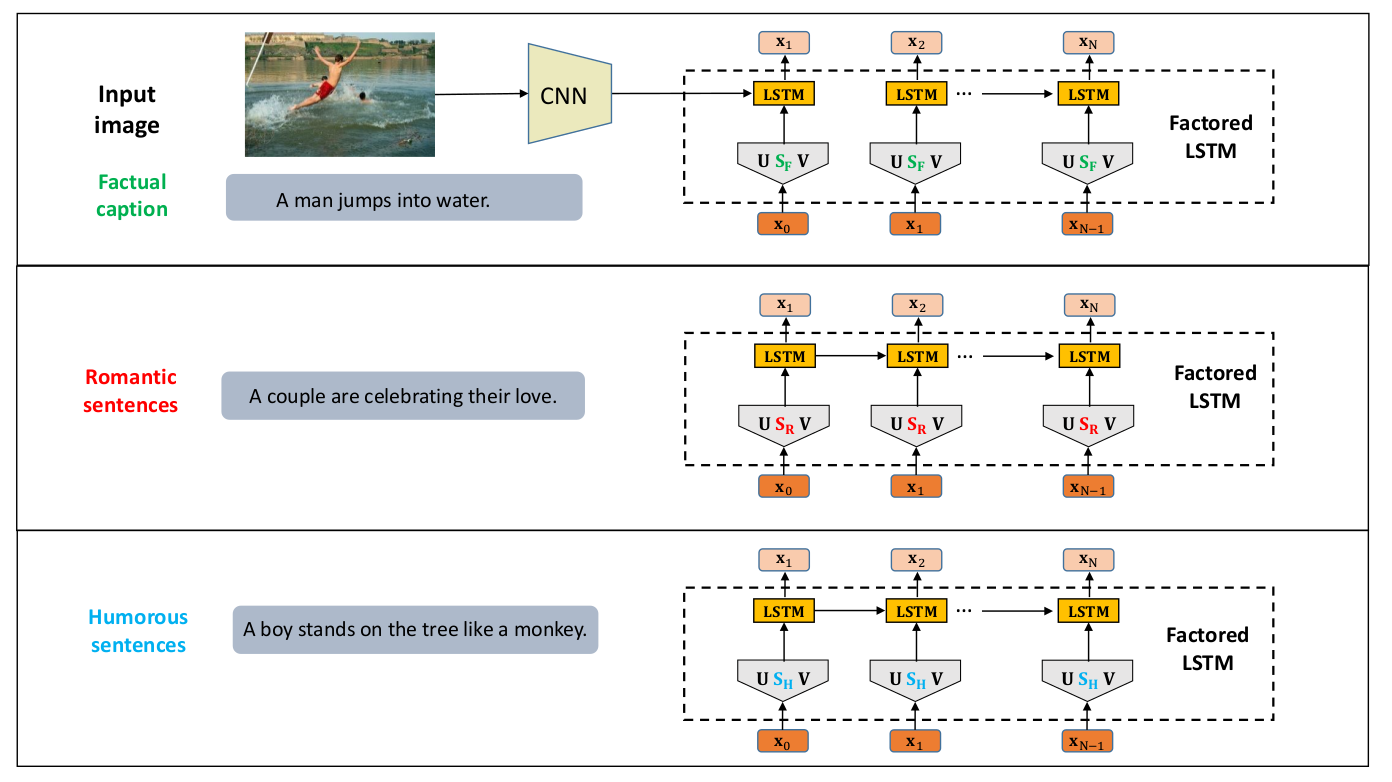
关键点:
1.将LSTM中参数Wx拆分成3项,Ux,Sx,Vx,模型中所有的LSTM网络除S之外的参数都是共享的,参数S用来记忆特定的风格。
2.类似于Multi-task sequence to sequence training. First task, train to generate factual captions given the paired images,更新所有的参数. Second, factored LSTM is trained as a language model,只更新SR或者SH.
“Factual” and “Emotional”: Stylized Image Captioning with Adaptive Learning and Attention (ECCV 2018)
Style-factual LSTM block: Sx, Sh and gxt, ght
Two-stage learning strategy
MLE loss + KL divergence
Image Captioning at Will: A Versatile Scheme for Effectively Injecting Sentiments into Image Descriptions (Preprint 30 Jan 2018)
SENTI-ATTEND: Image Captioning using Sentiment and Attention (Preprint 24 Nov 2018)
这篇文章可以看作是SentiCap的后续工作,采用的是Supervised的方式。
Datasets
MS COCO: 用于生成generic image captions
SentiCap dataset:
Evaluation Metrics
standard image caption evaluation metrics: BLEU, ROUGE-L, METEOR, CIDEr, SPICE
Entropy

Model
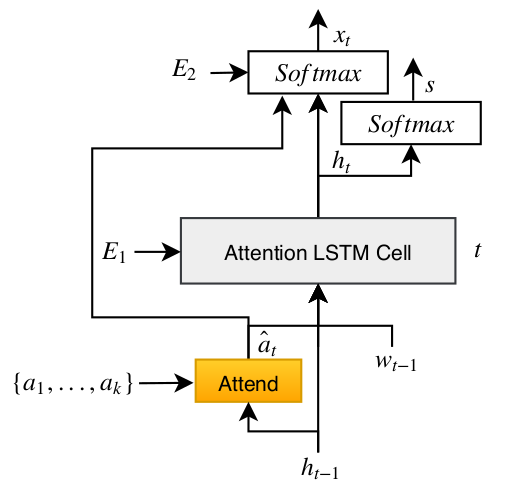

损失函数:
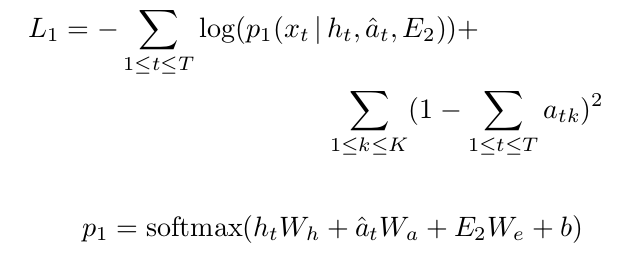
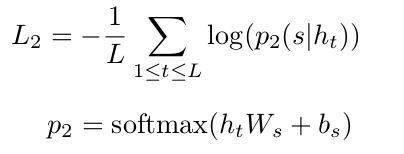
文章没有公布代码,实验部分对比的是SentiCap以及Image Caption at Will
疑问: SentiCap数据集很小,利用image-caption pairs来Cross entropy loss训练会有效果吗???
LSTM多加了E1和E2两个输入,每一步LSTM拿ht来预测s这个操作在SentiCap里也有,然后文章一直处于PrePrint状态。
SemStyle: Learning to Generate Stylised Image Captions using Unaligned Text (CVPR 2018)
公布了部分代码和数据
Style: Story
Learns on existing image caption datasets with only factual descriptions + a large set of styled texts without aligned images
Two-stage training strategy for the term generator and language generator
Dataset:
Descriptive Image Captions: MSCOCO
The Styled Text: bookcorpus
Evaluation:
Automatic relevance metrics: Widely-used captioning metrics (BLEU, METEOR, CIDEr, SPICE)
Automatic style metrics: 作者自己提出的LM(4-gram model)、GRULM(GRU language model)、CLF(binary classifier)
Human evaluations of relevance and style
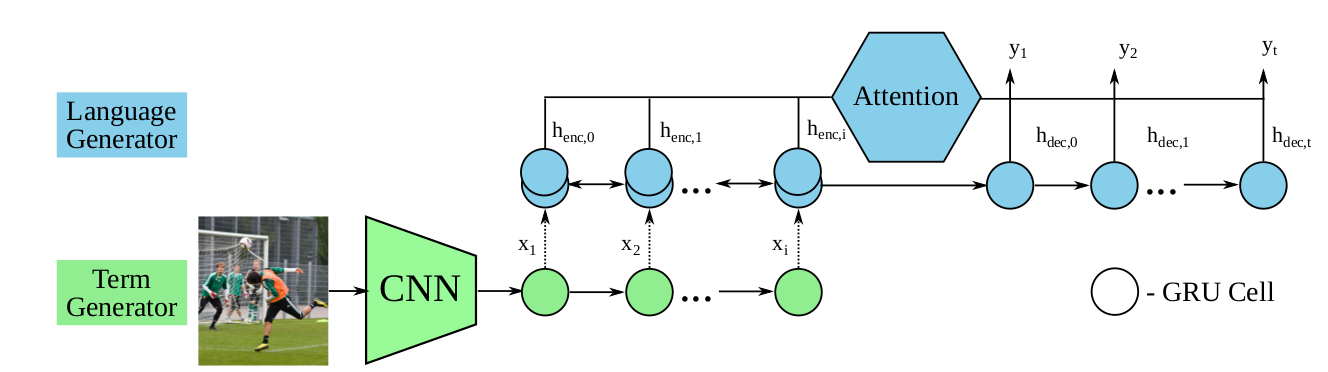
Unsupervised Stylish Image Description Generation via Domain Layer Norm (AAAI 2019)
Unsupervised Image Caption
Four different styles: fairy tale, romance, humor, country song lyrics(lyrics)
Our model is jointly trained with a paired unstylish image description corpus(source domain) and a monolingual corpus of the specific style(target domain)
代码和数据集均未公开
Datasets:
Source Domain:VG-Para(Krause et al. 2017)
Target: BookCorpus(humor and romance), 作者自己收集的country song lyrics and fairy tale
Evaluation Metircs:
Metrics of Semantic Relevance: 作者自己提出的p和r,SPICE
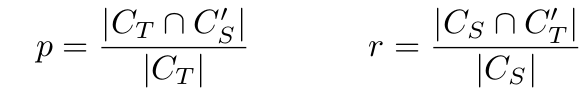
Metrics of Stylishness: transfer accuracy
Human evaluation
Approach Key Point
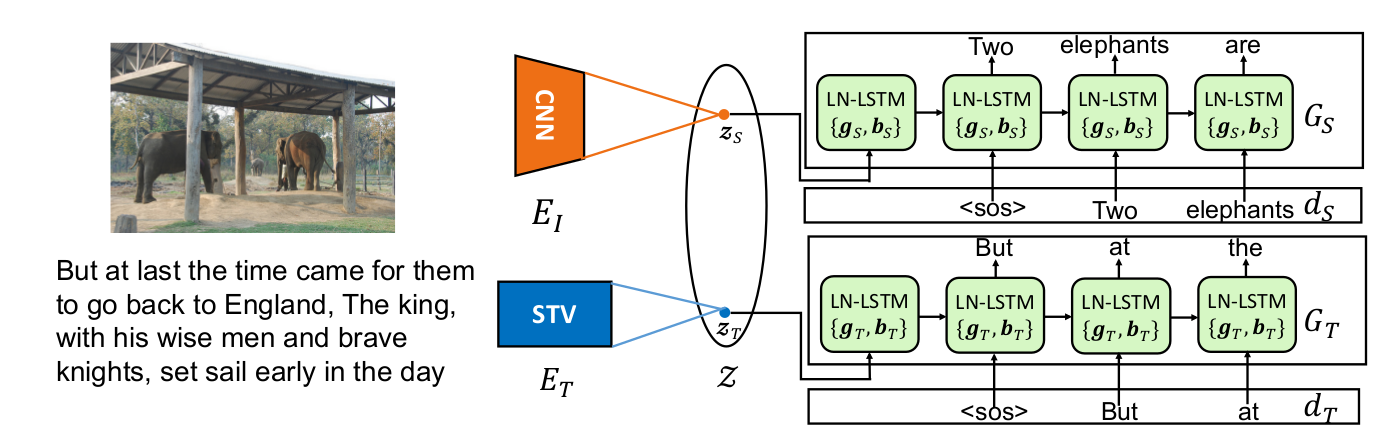
EI和ET分别将图片和目标风格的描述映射到同一个隐空间,Gs用来生成非风格化的描述,即Source domain里的句子,EI和GS组合起来就是传统的Image Caption的Encoder-Decoder模型,训练数据是有监督的Image-Caption对。GT用来生成风格化的描述,ET将风格化的句子编码到隐空间Z,GT则根据隐空间内的编码zT重新生成风格化的句子(Reconstruction),训练数据是风格化的句子。模型训练完成之后,将EI和GT组合,就可以生成风格化的图像描述。
关键点1:作者假设存在一个隐空间Z使得可以将图片, 不带风格的源描述以及带风格的目标描述映射到这个空间。
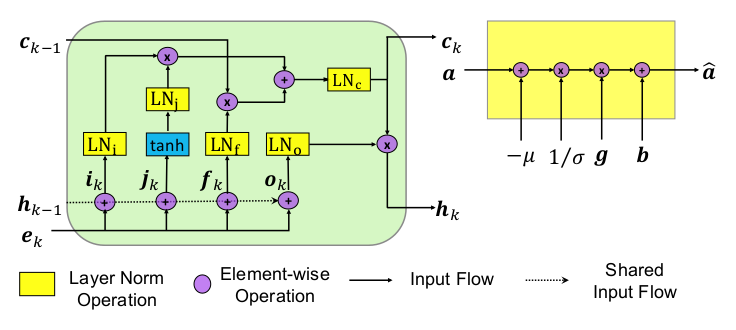
关键点2:GS和GT只在层规范化的参数不同,其他参数是共享的。即GS和GT的LN-LSTM是共享的,其中只有参数{gS,bS}和{gT,bT}不同,作者将这种机制称为Domain Layer Norm(DLN)。层规范化操作(layer norm operation)作用在LSTM的每一个Gate(input gate,forget gate, output gate)上。
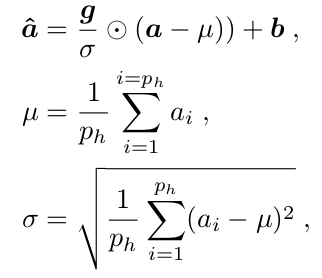
Stylized Image Caption论文笔记的更多相关文章
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
- 论文笔记之:Natural Language Object Retrieval
论文笔记之:Natural Language Object Retrieval 2017-07-10 16:50:43 本文旨在通过给定的文本描述,在图像中去实现物体的定位和识别.大致流程图如下 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
随机推荐
- 百度网盘直链下载助手(MacOS&Chrome)
简介 众所周知,通过百度网盘(未开通会员)直接下载文件的速度极慢,通过安装浏览器插件可以极大的提高下载速度. 安装文件 Tampermonkey NeatDownloadManager Extensi ...
- DirectX11 With Windows SDK--11 混合状态
原文:DirectX11 With Windows SDK--11 混合状态 前言 这一章会着重讲述混合状态,在下一章则会讲述深度/模板状态 DirectX11 With Windows SDK完整目 ...
- 【Leetcode链表】合并两个有序链表(21)
题目 将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两个链表的所有节点组成的. 示例: 输入:1->2->4, 1->3->4 输出:1->1-> ...
- poj 3225 【线段树】
poj 3225 这题是用线段树解决区间问题,看了两天多,算是理解一点了. Description LogLoader, Inc. is a company specialized in provid ...
- python == 符号
- oralce分析函数如何工作
语法 FUNCTION_NAME(<参数>,…) OVER (<PARTITION BY 表达式,…> <ORDER BY 表达式 <ASC DESC> &l ...
- oracle函数 RAWTOHEX(c1)
[功能]将一个二进制构成的字符串转换为十六进制 [参数]c1,二进制的字符串 [返回]字符串 [示例] select RAWTOHEX('A123') from dual;
- GMTC2019|闲鱼-基于Flutter的架构演进与创新
2012年应届毕业加入阿里巴巴,主导了闲鱼基于Flutter的新混合架构,同时推进了Flutter在闲鱼各业务线的落地.未来将持续关注终端技术的演变及趋势 Flutter的优势与挑战 Flutter是 ...
- @codeforces - 1209H@ Moving Walkways
目录 @description@ @solution@ @accepted code@ @details@ @description@ 机场中常常见到滑行道:假如一个滑行道的运行速度为 s,你的行走速 ...
- python---异常处理与反射
一.异常处理 1.异常基础 在编程过程中为了增加友好性,在程序出现bug时一般不会将错误信息显示给用户,而是现实一个提示的页面,通俗来说就是不让用户看见大黄页!!! try: pass except ...