保存数据到文件的模块(json,pickle,shelve,configparser,xml)_python
一、各模块的主要功能区别
json模块:将数据对象从内存中完成序列化存储,但是不能对函数和类进行序列化,写入的格式是明文。 (与其他大多语言交互的类型)
pickle模块:将数据对象从内存中完成序列化存储,可以能对函数进行序列化,写入的格式是二进制格式wb。 (支持python的所有数据类型,python特有的)
configparser模块:保存字典内容到文件,并按照一定的格式写入文件保存。
shelve模块:将对象写入到文件,保存没有格式。(较为轻便好用)

xml模块:不同语言或程序之间数据交换(早期常用,目前较少用,逐渐被json取代)。
二、各模块使用例子
1、configparser模块
(1)写入文件
import configparser
config=configparser.ConfigParser()
config['default']={'name':'chen','age':21,'sex':'male'} #字典格式的内容1
config['default2']={'class':'1','num':'43','team':'6'} #字典格式的内容2
f=open('configfile','w') #创建一个文本
config.write(f) #将字典内容写入文本
保存格式:

(2)读取文件内容
config=configparser.ConfigParser()
config.read('configfile.ini')
print(config.sections()) #['default', 'default2'],查看键值
print(config['default']['age']) #21,读取分区里面键值内容 (3)修改文件内容
config=configparser.ConfigParser()
config.read('configfile.ini') #先读取文件放到内存
config.remove_section('default2') #对内存文件进行修改,这里是删除分区
config.set('default','name','chenchenchen') #将分区里面的'name'键对应的值改为'chenchen'
config.add_section('ddd') #增加分区
config.set('ddd','dddd','ddddd') #添加分区内容
f=open('configfile.ini','w') #直接覆盖
config.write(f) #将已修改的内存文件内容保存到硬盘文件 2、shelve模块(较为轻便,好用)
(1)写入文件
import shelve
f=shelve.open('shelvetest') #创建文件
f['default']=1 #写入内容,值可以是数值,字典,函数等等数据类型
f.close()
(2)读取文件
f=shelve.open('shelvetest') #创建文件
data=f.get('default')
print(data) #1
f['default']={'name':'chen','age':21,'sex':'male'}
data=f.get('default')
print(data) #{'name': 'chen', 'age': 21, 'sex': 'male'}
保存格式:

3、json模块
(1)写入文件
import json
dic={'name': 'chen', 'age': 21, 'sex': 'male'}
data=json.dumps(dic) #序列化简化
f=open('json.txt','w')
f.write(data) #写入
f.close()
保存格式:明文

(2)读取文件
f=open('json.txt','r')#打开文件
data=f.read() #读取文件
data=json.loads(data) #反序列化,反简化
print(data)
注:一般使用dump一次和load一次,否则数据容易混乱
4、pickle模块(对比json,可以对包括函数和类的对象做序列化)
(1)写入文件
import pickle
def add():
print('add')
data=pickle.dumps(add)
f=open('pickle.txt','wb') #注意这里写入的是二进制格式,不是明文,这也是与json不同的点
f.write(data)
f.close()
保存格式:

(2)读取文件
f=open('pickle.txt','rb') #对应也是需要二进制b读取
data=f.read()
data=pickle.loads(data) #取出变量名
data() #函数取出的是变量名add,需要执行的话脚本里面还要有add函数本体。若是保存其他对象的话,可以直接打印,如列表
json和pickle模块通用方法:
dump(简化,相当于dumps和write的功能)
f=open('pickle.txt','wb')
data=pickle.dump(add,f) #相当于后面两行
# data=pickle.dumps(add)
# f.write(data)
f.close()
load(简化,相当于loads和read的功能)
f=open('pickle.txt','rb')
data=pickle.load(f) #相当于后面两行一起
# data=f.read()
# data=pickle.loads(data) #
print(data)
5、xml模块(了解)
不同语言或程序之间数据交换的协议
(1)python处理xml


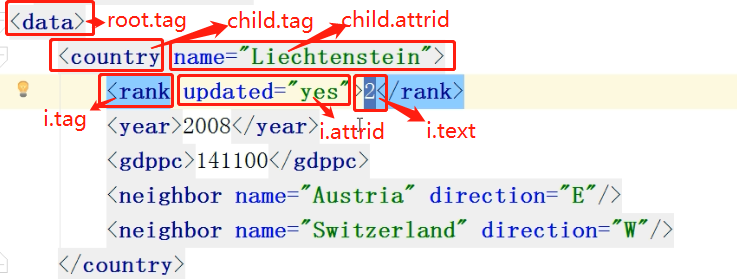

(2)修改
读取之后修改写回

修改之后:

(3)删除:

(4)创建:

保存数据到文件的模块(json,pickle,shelve,configparser,xml)_python的更多相关文章
- python 全栈开发,Day25(复习,序列化模块json,pickle,shelve,hashlib模块)
一.复习 反射 必须会 必须能看懂 必须知道在哪儿用 hasattr getattr setattr delattr内置方法 必须能看懂 能用尽量用__len__ len(obj)的结果依赖于obj. ...
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- python模块--json \ pickle \ shelve \ XML模块
一.json模块 之前学习过的eval内置方法可以将一个字符串转成一个python对象,不过eval方法时有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,e ...
- python开发模块基础:序列化模块json,pickle,shelve
一,为什么要序列化 # 将原本的字典.列表等内容转换成一个字符串的过程就叫做序列化'''比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给?现在我们能想到的方法就是存在文 ...
- python序列化模块 json&&pickle&&shelve
#序列化模块 #what #什么叫序列化--将原本的字典.列表等内容转换成一个字符串的过程叫做序列化. #why #序列化的目的 ##1.以某种存储形式使自定义对象持久化 ##2.将对象从一个地方传递 ...
- python_ 模块 json pickle shelve
一,什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编写的代码( ...
- 模块 - json/pickle/shelve/xml/configparser
序列化: 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 为什么要序列化: 有种办法可以直接把内存数据(eg:10个列表,3 ...
- 序列化 json pickle shelve configparser
一 什么是 序列化 在我们存储数据或者 网络传输数据的时候,需要对我们的 对象进行处理,把对象处理成方便我们存储和传输的 数据格式,这个过程叫序列化,不同的序列化,结果也不相同,但是目的是一样的,都是 ...
- 常用模块(json/pickle/shelve/XML)
一.json模块(重点) 一种跨平台的数据格式 也属于序列化的一种方式 介绍模块之前,三个问题: 序列化是什么? 我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化. 反序列化又是什么? 将 ...
随机推荐
- 搜索练习题LETTERS
题目链接:http://ybt.ssoier.cn:8088/problem_show.php?pid=1212 或者http://poj.org/problem?id=1154 题目描述: 给 ...
- CentOS7安装postgreSQL11
1.添加PostgreSQL Yum存储库 sudo yum install https://download.postgresql.org/pub/repos/yum/11/redhat/rhel- ...
- sql多字段分组排序显示全部数据
建表sql CREATE TABLE `tbl_demo` ( `id` ) COLLATE utf8_bin NOT NULL, `payer_name` ) COLLATE utf8_bin DE ...
- C++中复制构造函数被调用的三种情况
C++中的构造函数 c++中的构造函数分为构造函数,和复制构造函数,相比于构造函数,复制构造函数使用更加方便,快捷.构造函数可以有多个,二复制构造函数只能有一个,因为复制构造函数的参数只能是当前类的一 ...
- MySQL int、char、varchar 最大值是多少?
1.int(len) (1)max(len) = 255 (2)存储范围: 带符号整数:-2147483648-2147483647. 无符号(unsigned)整数:0-4294967295. 2. ...
- vue项目下的导入和导出
本篇博文主要记录我们在写项目的时候经常需要用到导入和导出. 导入 首先定义一个模态弹窗,一般情况下会使用一个input(设置opacity:0)覆盖在显示的按钮上面 <!-- 3.导入 --&g ...
- C# DES加密、解密
/// <summary> /// DES加密字符串 /// </summary> /// <param name="pToEncrypt">待 ...
- Android中的Service基础
Service主要用于后台程序和跨进程访问,可以在不显示界面的前提下完成任务,不影响用户的其他操作. 这里我展示一些基本的用法 新建一个Service类 package com.example.ser ...
- the simmon effect(in psychology) :build the function of subject_information(modify the experiment programme),before we begin the experiment
#the real experiment for simon effect #load the library which is our need import pygame import sys i ...
- 快速安装字体.bat批处理脚本
因为经常要做些美工,暑假才换的笔记本上还没装什么字体,这次找到了字体资源,索性一次性装了~ 下载下来的字体包是\(.zip\)压缩文件,解压后如果一个个点\(.ttf\)文件来安装比较麻烦,所以写了一 ...