「Flink」使用Managed Keyed State实现计数窗口功能
先上代码:
public class WordCountKeyedState {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 初始化测试单词数据流
DataStreamSource<String> lineDS = env.addSource(new RichSourceFunction<String>() {
private boolean isCanaled = false;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while(!isCanaled) {
ctx.collect("hadoop flink spark");
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCanaled = true;
}
});
// 切割单词,并转换为元组
SingleOutputStreamOperator<Tuple2<String, Integer>> wordTupleDS = lineDS.flatMap((String line, Collector<Tuple2<String, Integer>> ctx) -> {
Arrays.stream(line.split(" ")).forEach(word -> ctx.collect(Tuple2.of(word, 1)));
}).returns(Types.TUPLE(Types.STRING, Types.INT));
// 按照单词进行分组
KeyedStream<Tuple2<String, Integer>, Integer> keyedWordTupleDS = wordTupleDS.keyBy(t -> t.f0);
// 对单词进行计数
keyedWordTupleDS.flatMap(new RichFlatMapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>() {
private transient ValueState<Tuple2<Integer, Integer>> countSumValueState;
@Override
public void open(Configuration parameters) throws Exception {
// 初始化ValueState
ValueStateDescriptor<Tuple2<Integer, Integer>> countSumValueStateDesc = new ValueStateDescriptor("countSumValueState",
TypeInformation.of(new TypeHint<Tuple2<Integer, Integer>>() {})
);
countSumValueState = getRuntimeContext().getState(countSumValueStateDesc);
}
@Override
public void flatMap(Tuple2<String, Integer> value, Collector<Tuple2<String, Integer>> out) throws Exception {
if(countSumValueState.value() == null) {
countSumValueState.update(Tuple2.of(0, 0));
}
Integer count = countSumValueState.value().f0;
count++;
Integer valueSum = countSumValueState.value().f1;
valueSum += value.f1;
countSumValueState.update(Tuple2.of(count, valueSum));
// 每当达到3次,发送到下游
if(count > 3) {
out.collect(Tuple2.of(value.f0, valueSum));
// 清除计数
countSumValueState.update(Tuple2.of(0, valueSum));
}
}
}).print();
env.execute("KeyedState State");
}
}
代码说明:
1、构建测试数据源,每秒钟发送一次文本,为了测试方便,这里就发一个包含三个单词的文本行
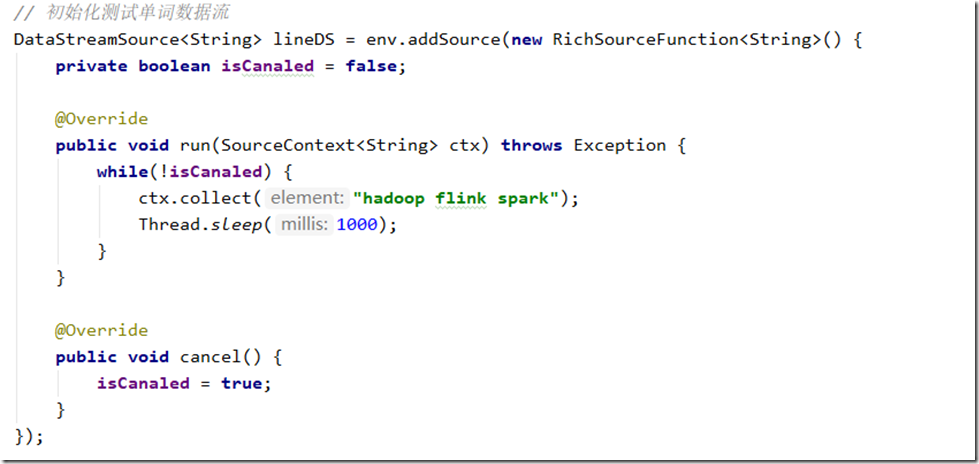
2、对句子按照空格切分,并将单词转换为元组,每个单词初始出现的次数为1

3、按照单词进行分组

4、自定义FlatMap
初始化ValueState,注意:ValueState只能在KeyedStream中使用,而且每一个ValueState都对一个一个key。每当一个并发处理ValueState,都会从上下文获取到Key的取值,所以每个处理逻辑拿到的ValueStated都是对应指定key的ValueState,这个部分是由Flink自动完成的。
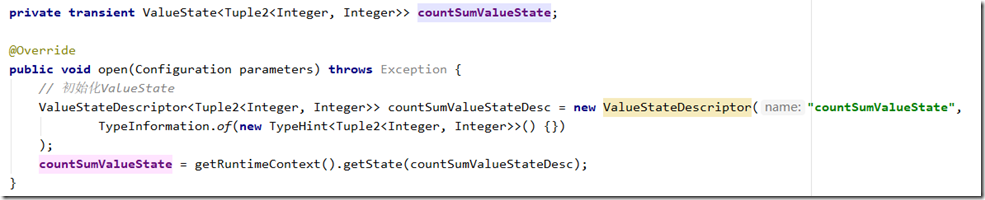
注意:
带默认初始值的ValueStateDescriptor已经过期了,官方推荐让我们手动在处理时检查是否为空
instead and manually manage the default value by checking whether the contents of the state is null.
”
/**
* Creates a new {@code ValueStateDescriptor} with the given name, default value, and the specific
* serializer.
*
* @deprecated Use {@link #ValueStateDescriptor(String, TypeSerializer)} instead and manually
* manage the default value by checking whether the contents of the state is {@code null}.
*
* @param name The (unique) name for the state.
* @param typeSerializer The type serializer of the values in the state.
* @param defaultValue The default value that will be set when requesting state without setting
* a value before.
*/
@Deprecated
public ValueStateDescriptor(String name, TypeSerializer<T> typeSerializer, T defaultValue) {
super(name, typeSerializer, defaultValue);
}
5、逻辑实现
在flatMap逻辑中判断ValueState是否已经初始化,如果没有手动给一个初始值。并进行累加后更新。每当count > 3发送计算结果到下游,并清空计数。

「Flink」使用Managed Keyed State实现计数窗口功能的更多相关文章
- Flink状态专题:keyed state和Operator state
众所周知,flink是有状态的计算.所以学习flink不可不知状态. 正好最近公司有个需求,要用到flink的状态计算,需求是这样的,收集数据库新增的数据. ...
- 「Flink」Flink的状态管理与容错
在Flink中的每个函数和运算符都是有状态的.在处理过程中可以用状态来存储数据,这样可以利用状态来构建复杂操作.为了让状态容错,Flink需要设置checkpoint状态.Flink程序是通过chec ...
- 「Flink」Flink 1.9 WebUI运行作业界面分析
运行作业界面 在以下界面中,可以查看到作业的名称.作业的启动时间.作业总计运行时长.作业一共有多少个任务.当前正在运行多少个任务.以及作业的当前状态. 这里的程序:一共有17个任务,当前正在运行的是1 ...
- 「Flink」事件时间与水印
我们先来以滚动时间窗口为例,来看一下窗口的几个时间参数与Flink流处理系统时间特性的关系. 获取窗口开始时间Flink源代码 获取窗口的开始时间为以下代码: org.apache.flink.str ...
- 「Flink」Flink中的时间类型
Flink中的时间类型和窗口是非常重要概念,是学习Flink必须要掌握的两个知识点. Flink中的时间类型 时间类型介绍 Flink流式处理中支持不同类型的时间.分为以下几种: 处理时间 Flink ...
- 「Flink」RocksDB介绍以及Flink对RocksDB的支持
RocksDB介绍 RocksDB简介 RocksDB是基于C++语言编写的嵌入式KV存储引擎,它不是一个分布式的DB,而是一个高效.高性能.单点的数据库引擎.它是由Facebook基于Google开 ...
- 「Flink」理解流式处理重要概念
什么是流式处理呢? 这个问题其实我们大部分时候是没有考虑过的,大多数,我们是把流式处理和实时计算放在一起来说的.我们先来了解下,什么是数据流. 数据流(事件流) 数据流是无边界数据集的抽象 我们之前接 ...
- 「Flink」配置使用Flink调试WebUI
很多时候,我们在IDE中编写Flink代码,我们希望能够查看到Web UI,从而来了解Flink程序的运行情况.按照以下步骤操作即可,亲测有效. 1.添加Maven依赖 <dependency& ...
- 「Flink」使用Java lambda表达式实现Flink WordCount
本篇我们将使用Java语言来实现Flink的单词统计. 代码开发 环境准备 导入Flink 1.9 pom依赖 <dependencies> <dependency> < ...
随机推荐
- react元素获取e时,点击target为空的现象
今天呢,学习react过程中,我要获取一个元素的e, checkAll=(e)=>{ console.log(e) console.log(e.target) } render() { retu ...
- 使用Razor 使用Razor表达式处理命名空间 精通ASP-NET-MVC-5-弗瑞曼
- vijos 分梨子
点击打开题目 很有(wei)趣(suo)的一道题 暴力解法也不难,枚举大小下限与甜度下限,在一个一个地试 显然 O(n^3) 炸掉 但如何将其缩短,只好从那个式子来入手了: C1⋅(ai−a0)+C2 ...
- 个人第四次作业Alpha2版本测试
个人第四次作业Alpha2版本测试 这个作业属于哪个课程 软件工程 这个作业要求在哪里 作业要求 团队名称 GP工作室 这个作业的目标 对其他小组的项目进行测试 测试人员 陈杰 学号 20173102 ...
- 团队项目-Beta冲刺2
博客介绍 这个作业属于哪个课程 https://edu.cnblogs.com/campus/xnsy/GeographicInformationScience 这个作业要求在哪里 https://w ...
- if continue的用法(跳过本次循环,执行下一个循环)
Python continue 语句跳出本次循环 当需要跳过本次循环的时候,使用continue能跳过本次循环,直接下一个循环 如下脚本: for url in alllink: if url == ...
- php--->使用callable强制指定回调类型
php 使用callable强制指定回调类型 如果一个方法需要接受一个回调方法作为参数,我们可以这样写 <?php function dosth($callback){ call_user_fu ...
- obj2gltf安装详细教程
在线转换地址:http://52.4.31.236/convertmodel.html 在使用cesium的过程中需要使用到gltf模型,官方推荐使用obj2gltf插件将obj模型转换成gltf格式 ...
- Tomcat项目启动常见错误以及原因,持续更新.........
一 Context initialization failed 错误截图: 原因: jdk版本与项目不对应,可重新设置项目jdk和ide编译的jdk即可
- 超链接a标签的伪类选择器问题,Link标签与visited标签的失效问题(问题介绍与解决方法)。
<!DOCTYPE html>< html>< head> <meta charset="utf-8" /> < ...