Netty之缓冲区ByteBuf解读(一)

Netty 在数据传输过程中,会使用缓冲区设计来提高传输效率。虽然,Java 在 NIO 编程中已提供 ByteBuffer 类进行使用,但是在使用过程中,其编码方式相对来说不太友好,也存在一定的不足。所以高性能的 Netty 框架实现了一套更加强大,完善的 ByteBuf,其设计理念也是堪称一绝。
ByteBuffer 分析
在分析 ByteBuf 之前,先简单讲下 ByteBuffer 类的操作。便于更好理解 ByteBuf 。
ByteBuffer 的读写操作共用一个位置指针,读写过程通过以下代码案例分析:
// 分配一个缓冲区,并指定大小
ByteBuffer buffer = ByteBuffer.allocate(100);
// 设置当前最大缓存区大小限制
buffer.limit(15);
System.out.println(String.format("allocate: pos=%s lim=%s cap=%s", buffer.position(), buffer.limit(), buffer.capacity()));
String content = "ytao公众号";
// 向缓冲区写入数据
buffer.put(content.getBytes());
System.out.println(String.format("put: pos=%s lim=%s cap=%s", buffer.position(), buffer.limit(), buffer.capacity()));
其中打印了缓冲区三个参数,分别是:
- position 读写指针位置
- limit 当前缓存区大小限制
- capacity 缓冲区大小
打印结果:
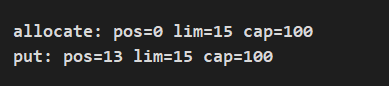
当我们写入内容后,读写指针值为 13,ytao公众号英文字符占 1 个 byte,每个中文占 4 个 byte,刚好 13,小于设置的当前缓冲区大小 15。
接下来,读取内容里的 ytao 数据:
buffer.flip();
System.out.println(String.format("flip: pos=%s lim=%s cap=%s", buffer.position(), buffer.limit(), buffer.capacity()));
byte[] readBytes = new byte[4];
buffer.get(readBytes);
System.out.println(String.format("get(4): pos=%s lim=%s cap=%s", buffer.position(), buffer.limit(), buffer.capacity()));
String readContent = new String(readBytes);
System.out.println("readContent:"+readContent);
读取内容需要创建个 byte 数组来接收,并制定接收的数据大小。
在写入数据后再读取内容,必须主动调用ByteBuffer#flip或ByteBuffer#clear。
ByteBuffer#flip它会将写入数据后的指针位置值作为当前缓冲区大小,再将指针位置归零。会使写入数据的缓冲区改为待取数据的缓冲区,也就是说,读取数据会从刚写入的数据第一个索引作为读取数据的起始索引。
ByteBuffer#flip相关源码:
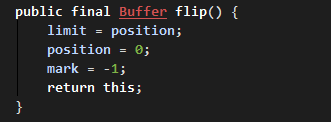
ByteBuffer#clear则会重置 limit 为默认值,与 capacity 大小相同。

接下读取剩余部分内容:
第二次读取的时候,可使用buffer#remaining来获取大于或等于剩下的内容的字节大小,该函数实现为limit - position,所以当前缓冲区域一定在这个值范围内。
readBytes = new byte[buffer.remaining()];
buffer.get(readBytes);
System.out.println(String.format("get(remaining): pos=%s lim=%s cap=%s", buffer.position(), buffer.limit(), buffer.capacity()));
打印结果:

以上操作过程中,索引变化如图:
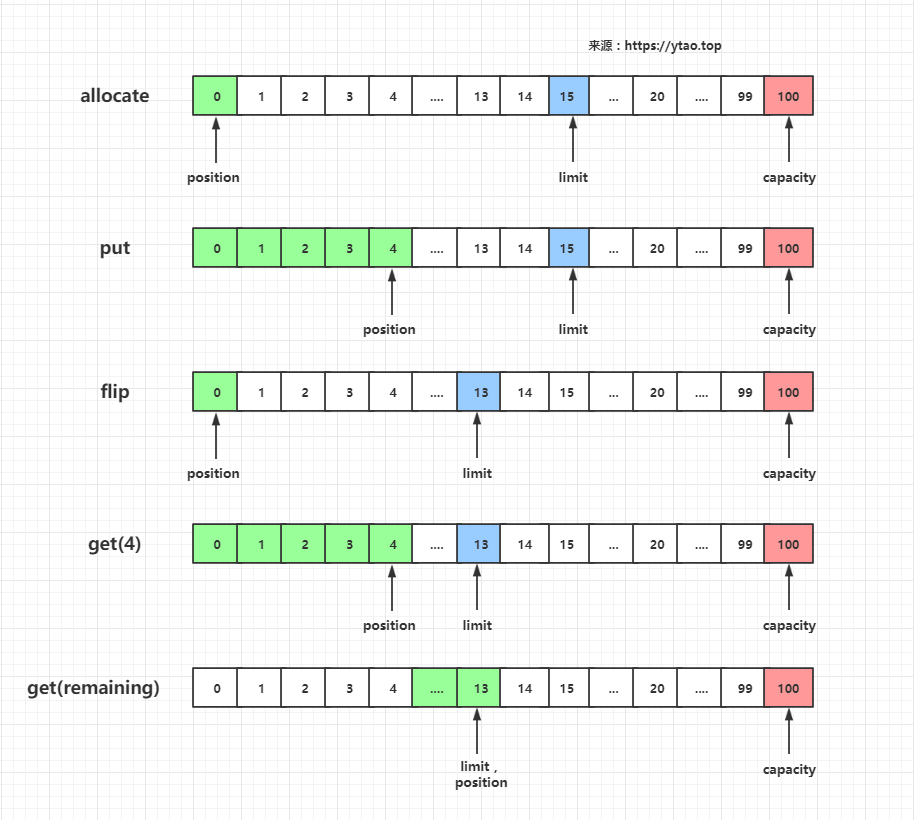
ByteBuf 读写操作
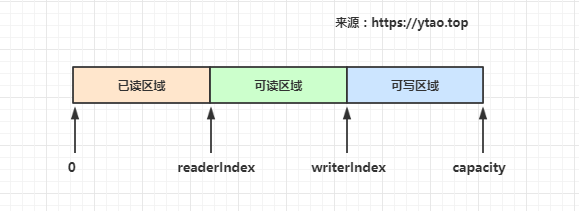
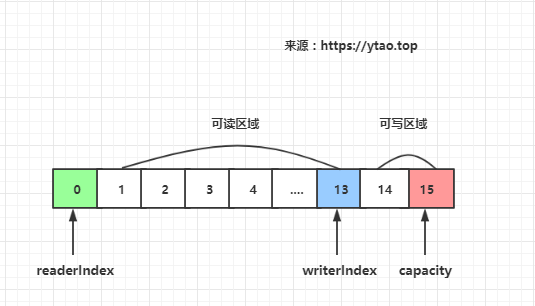
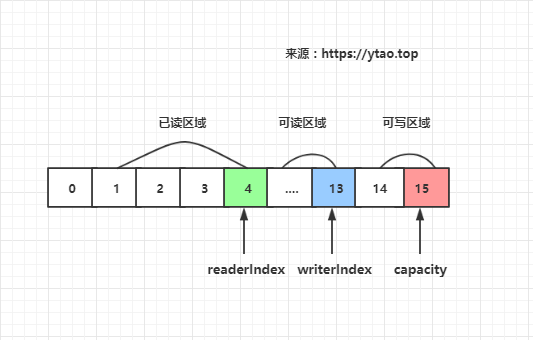
ByteBuf 有读写指针是分开的,分别是buf#readerIndex和buf#writerIndex,当前缓冲器大小buf#capacity。
这里缓冲区被两个指针索引和容量划分为三个区域:
- 0 -> readerIndex 为已读缓冲区域,已读区域可重用节约内存,readerIndex 值大于或等于 0
- readerIndex -> writerIndex 为可读缓冲区域,writerIndex 值大于或等于 readerIndex
- writerIndex -> capacity 为可写缓冲区域,capacity 值大于或等于 writerIndex
如下图所示:
分配缓冲区
ByteBuf 分配一个缓冲区,仅仅给定一个初始值就可以。默认是 256。初始值不像 ByteBuffer 一样是最大值,ByteBuf 的最大值是Integer.MAX_VALUE
ByteBuf buf = Unpooled.buffer(13);
System.out.println(String.format("init: ridx=%s widx=%s cap=%s", buf.readerIndex(), buf.writerIndex(), buf.capacity()));
打印结果:

写操作
ByteBuf 写操作和 ByteBuffer 类似,只是写指针是单独记录的,ByteBuf 的写操作支持多种类型,有以下多个API:
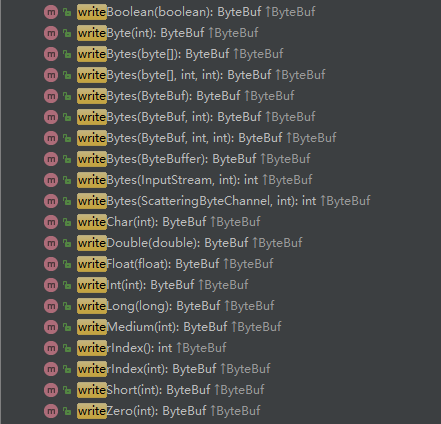
写入字节数组类型:
String content = "ytao公众号";
buf.writeBytes(content.getBytes());
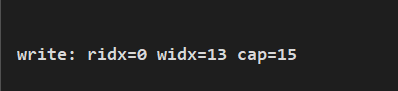
System.out.println(String.format("write: ridx=%s widx=%s cap=%s", buf.readerIndex(), buf.writerIndex(), buf.capacity()));
打印结果:
索引示意图:
读操作
一样的,ByteBuf 写操作和 ByteBuffer 类似,只是写指针是单独记录的,ByteBuf 的读操作支持多种类型,有以下多个API:
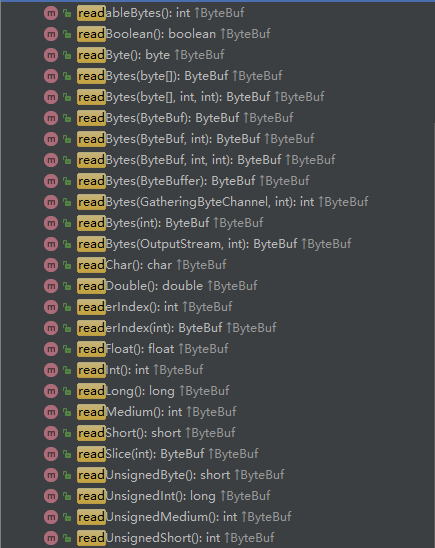
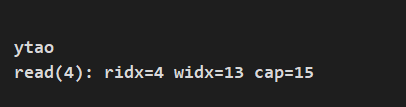
从当前 readerIndex 位置读取四个字节内容:
byte[] dst = new byte[4];
buf.readBytes(dst);
System.out.println(new String(dst));
System.out.println(String.format("read(4): ridx=%s widx=%s cap=%s", buf.readerIndex(), buf.writerIndex(), buf.capacity()));
打印结果:
索引示意图:
ByteBuf 动态扩容
通过上面的 ByteBuffer 分配缓冲区例子,向里面添加 [ytao公众号ytao公众号] 内容,使写入的内容大于 limit 的值。
ByteBuffer buffer = ByteBuffer.allocate(100);
buffer.limit(15);
String content = "ytao公众号ytao公众号";
buffer.put(content.getBytes());
运行结果异常:

内容字节大小超过了 limit 的值时,缓冲区溢出异常,所以我们每次写入数据前,得检查缓区大小是否有足够空间,这样对编码上来说,不是一个好的体验。
使用 ByteBuf 添加同样的内容,给定同样的初始容器大小。
ByteBuf buf = Unpooled.buffer(15);
String content = "ytao公众号ytao公众号";
buf.writeBytes(content.getBytes());
System.out.println(String.format("write: ridx=%s widx=%s cap=%s", buf.readerIndex(), buf.writerIndex(), buf.capacity()));
打印运行结果:
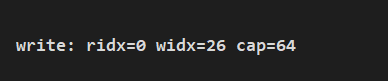
通过上面打印信息,可以看到 cap 从设置的 15 变为了 64,当我们容器大小不够时,就是进行扩容,接下来我们分析扩容过程中是如何做的。
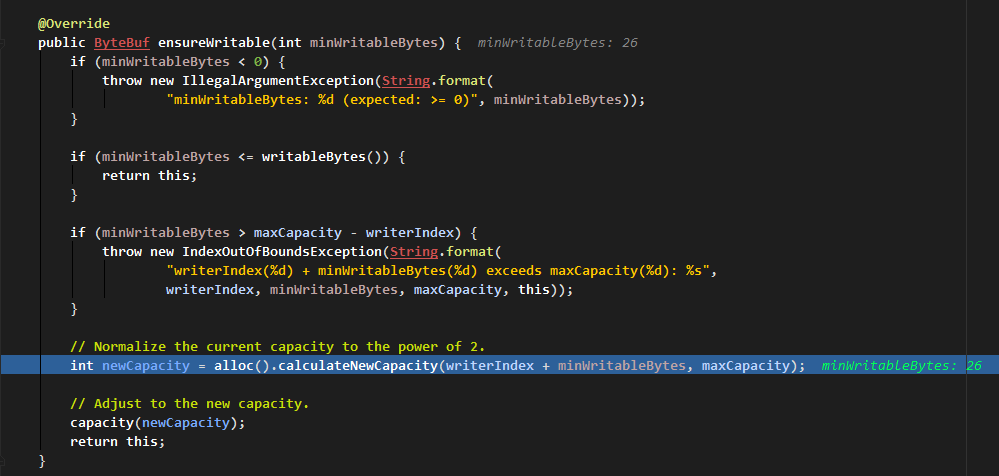
进入 writeBytes 里面:

校验写入内容长度:
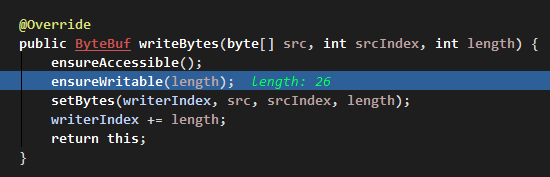
在可写区域检查里:
- 如果写入内容为空,抛出非法参数异常。
- 如果写入内容大小小于或等于可写区域大小,则返回当前缓冲区,当中的
writableBytes()函数为可写区域大小capacity - writerIndex - 如果写入内容大小大于最大可写区域大小,则抛出索引越界异常。
- 最后剩下条件的就是写入内容大小大于可写区域,小于最大区域大小,则分配一个新的缓冲区域。
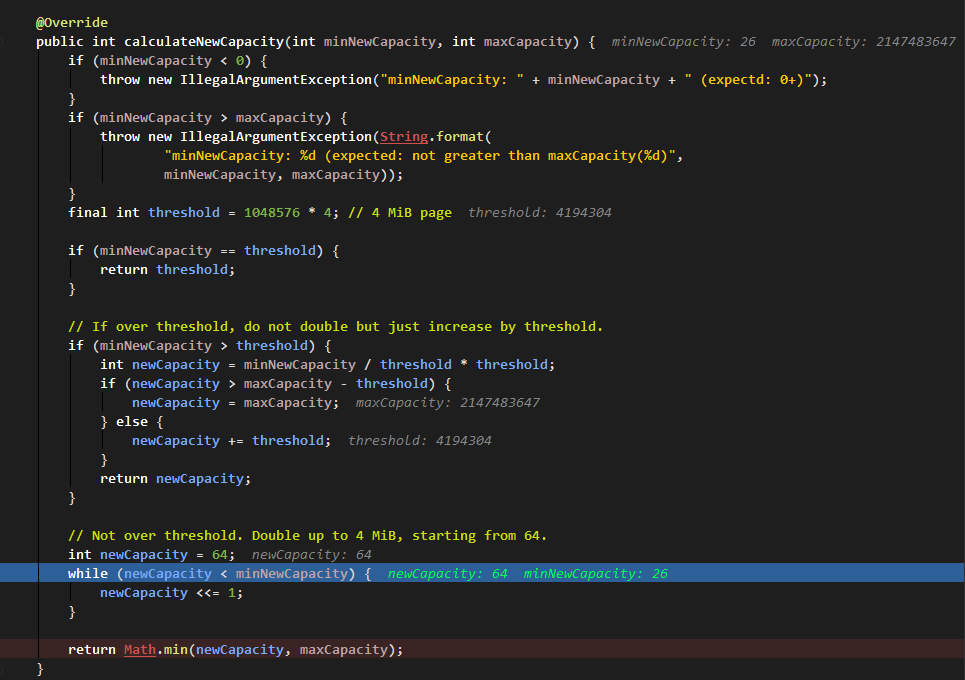
在容量不足,重新分配缓冲区的里面,以 4M 为阀门:
- 如果待写内容刚好为 4M, 那么就分配 4M 的缓冲区。
- 如果待写内容超过这个阀门且与阀门值之和不大于最大容量值,就分配(阀门值+内容大小值)的缓冲区;如果超过这个阀门且与阀门值之和大于最大容量值,则分配最大容量的缓冲区。
- 如果待写内容不超过阀门值且大于 64,那么待分配缓冲区大小就以 64 的大小进行倍增,直到相等或大于待写内容。
- 如果待写内容不超过阀门值且不大于 64,则返回待分配缓冲区大小为 64。
最后
Netty 实现的缓冲区,八个基本类型中,除了布尔类型,其他7种都有自己对应的 Buffer,但是实际使用过程中, ByteBuf 才是我们尝试用的,它可兼容任何类型。ByteBuf 在 Netty 体系中是最基础也是最重要的一员,要想更好掌握和使用 Netty,先理解并掌握 ByteBuf 是必需条件之一。
个人博客: https://ytao.top
关注公众号 【ytao】,更多原创好文

Netty之缓冲区ByteBuf解读(一)的更多相关文章
- Netty之缓冲区ByteBuf解读(二)
上篇介绍了 ByteBuf 的简单读写操作以及读写指针的基本介绍,本文继续对 ByteBuf 的基本操作进行解读. 读写指针回滚 这里的 demo 例子还是使用上节使用的. ByteBuf buf = ...
- Netty buffer缓冲区ByteBuf
Netty buffer缓冲区ByteBuf byte 作为网络传输的基本单位,因此数据在网络中进行传输时需要将数据转换成byte进行传输.netty提供了专门的缓冲区byte生成api ByteBu ...
- netty中的ByteBuf
网络数据的基本单位总是字节.Java NIO 提供了 ByteBuffer 作为它 的字节容器,但是这个类使用起来过于复杂,而且也有些繁琐. Netty 的 ByteBuffer 替代品是 ByteB ...
- Netty学习篇⑥--ByteBuf源码分析
什么是ByteBuf? ByteBuf在Netty中充当着非常重要的角色:它是在数据传输中负责装载字节数据的一个容器;其内部结构和数组类似,初始化默认长度为256,默认最大长度为Integer.MAX ...
- 7.netty内存管理-ByteBuf
ByteBuf ByteBuf是什么 ByteBuf重要API read.write.set.skipBytes mark和reset duplicate.slice.copy retain.rele ...
- 网络编程Netty入门:ByteBuf分析
目录 Netty中的ByteBuf优势 NIO使用的ByteBuffer有哪些缺点 ByteBuf的优势和做了哪些增强 ByteBuf操作示例 ByteBuf操作 简单的Demo示例 堆内和堆外内存 ...
- Netty 框架学习 —— ByteBuf
概述 网络数据的基本单位总是字节,Java NIO 提供了 ByteBuffer 作为它的字节容器,但这个类的使用过于复杂.Netty 的 ByteBuf 具有卓越的功能性和灵活性,可以作为 Byte ...
- netty系列之:netty中的ByteBuf详解
目录 简介 ByteBuf详解 创建一个Buff 随机访问Buff 序列读写 搜索 其他衍生buffer方法 和现有JDK类型的转换 总结 简介 netty中用于进行信息承载和交流的类叫做ByteBu ...
- netty系列之:不用怀疑,netty中的ByteBuf就是比JAVA中的好用
目录 简介 ByteBuf和ByteBuffer的可扩展性 不同的使用方法 性能上的不同 总结 简介 netty作为一个优秀的的NIO框架,被广泛应用于各种服务器和框架中.同样是NIO,netty所依 ...
随机推荐
- 深度学习——GAN
整理自: https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1 思想 表达式 实际计算 ...
- MySQL查询语句积累
#查询名字中带李且名字是两个字的所有学生信息 SELECT * FROM user_test WHERE user_name LIKE '李_';
- 原 Linux:ping不通baidu.com
如果某台Linux服务器ping不通域名, 如下提示: [root@localhost ~]# ping www.baidu.com ping: unknown host www.baidu.com ...
- ASP.NET MVC4.0+EF+LINQ+bui+bootstrap+网站+角色权限管理系统(4)
接下来就是菜单管理了,菜单分为两部分,一部分是菜单管理,另一部分是左边的树形菜单 数据库添加菜单表Menus USE [MVCSystem] GO /****** Object: Table [dbo ...
- Linux 内核 usb_control_msg 接口
usb_control_msg 函数就像 usb_bulk_msg 函数, 除了它允许一个驱动发送和结束 USB 控制信息: int usb_control_msg(struct usb_device ...
- dotnet 数组自动转基类数组提示 Co-variant array conversion 是什么问题
在 C# 的语法,可以提供自动将某个类的数组自动转这个类的基类数组的方法,但是这样的转换在 Resharper 会提示 Co-variant array conversion 这是什么问题? 在 C# ...
- CodeForces 375D Tree and Queries
传送门:https://codeforces.com/problemset/problem/375/D 题意: 给你一颗有根树,树上每个节点都有其对应的颜色,有m次询问,每次问你以点v为父节点的子树内 ...
- 【k8s】kubeadm快速部署Kubernetes
1.Kubernetes 架构图 kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具. 这个工具能通过两条指令完成一个kubernetes集群的部署: # 创建一个 Mast ...
- Oracle Net Manager 的使用方法(监听的配置方法)
一,在服务端配置oracle端口 win+R 输入netca 弹出如下窗口后 选择监听程序配置,点击下一步 二.配置端口后使用Telnet工具调试端口是否联通 在命令行输入telnet 服务器ip ...
- umask 设置
背景: 有时候需要在linux上从其他人的目录里copy文件过来. 最近遇上的事情很麻烦,就是copy的时候发现很多文件copy不过来,copy一个文件夹时,当前文件把权限修改了,结果子目录的中的还没 ...