urllib模块提供的urlretrieve()函数使用
urllib模块提供的urlretrieve()函数,urlretrieve()方法直接将远程的数据下载到本地
注意:若是网站有反爬虫的话这个函数会返回 403 Forbidden
参数url:传入的网址,网址必须得是个字符串
参数filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
参数reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
参数data:指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
下面例子将表情包下载到本地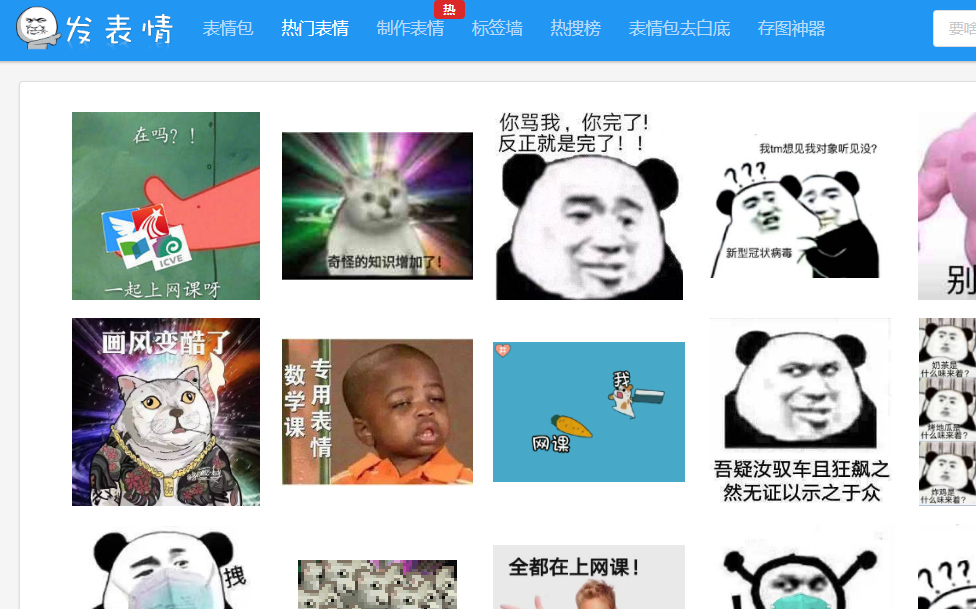
import requests
from lxml import etree
from urllib import request
import os
import re def page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}
res = requests.get(url,headers=headers)
text = res.text
html = etree.HTML(text)
imgs = html.xpath("//div[@class='tagbqppdiv']//img")
for img in imgs:
img_url = img.get('data-original')
alt =img.get('alt')
sufixx = os.path.splitext(img_url)[1]#切割文件后缀名
alt = re.sub(r'[\??\.。\!\!]',"",alt)
filename = alt + sufixx
request.urlretrieve(img_url,r"F:\pacong\hr class\xpath\images\\"+filename)
# print(etree.tostring(img))
# imgs = html.xpath("//div[@class='page-content text-center']//@href")#取出所有href里的链接
#print(text) def main():
for i in range(1,101):
url = 'https://www.fabiaoqing.com/biaoqing/lists/page/%d.html'%i
page(url)
break if __name__ == '__main__':
main()
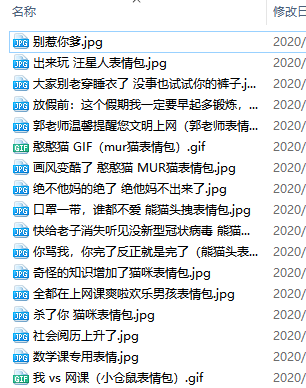
运行结果:
urllib模块提供的urlretrieve()函数使用的更多相关文章
- Python基础之 urllib模块urlopen()与urlretrieve()的使用方法详解。
Python urllib模块urlopen()与urlretrieve()的使用方法详解 1.urlopen()方法urllib.urlopen(url[, data[, proxies]]) ...
- Python urllib模块urlopen()与urlretrieve()详解
1.urlopen()方法urllib.urlopen(url[, data[, proxies]]) :创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据.参数u ...
- Python urllib的urlretrieve()函数解析 (显示下载进度)
#!/usr/bin/python #encoding:utf-8 import urllib import os def Schedule(a,b,c): ''''' a:已经下载的数据块 b:数据 ...
- Python:urllib模块的urlretrieve方法
转于:https://blog.csdn.net/fengzhizi76506/article/details/59229846 博主:fengzhizi76506 1)功能: urllib模块提供的 ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- Python urllib urlretrieve函数解析
Python urllib urlretrieve函数解析 利用urllib.request.urlretrieve函数下载文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 Ur ...
- Python核心模块——urllib模块
现在Python基本入门了,现在开始要进军如何写爬虫了! 先把最基本的urllib模块弄懂吧. urllib模块中的方法 1.urllib.urlopen(url[,data[,proxies]]) ...
- python爬虫-urllib模块
urllib 模块是一个高级的 web 交流库,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如:HTTP.FTP.Gophe ...
- [转]Python核心模块——urllib模块
现在Python基本入门了,现在开始要进军如何写爬虫了! 先把最基本的urllib模块弄懂吧. urllib模块中的方法 1.urllib.urlopen(url[,data[,proxies]]) ...
随机推荐
- 康拓展开 & 逆康拓展开 知识总结(树状数组优化)
康拓展开 : 康拓展开,难道他是要飞翔吗?哈哈,当然不是了,康拓具体是哪位大叔,我也不清楚,重要的是 我们需要用到它后面的展开,提到展开,与数学相关的,肯定是一个式子或者一个数进行分解,即 展开. 到 ...
- 【Bullet引擎】刚体类 —— btRigidBody
btRigidBody类主要用于刚体数据的计算. 在模拟刚体动画过程中,可以使用btRigidBody类获取所保存的刚体对象,进而控制刚体对象的旋转和位移.进行刚体模拟计算需要经常用到此类. API: ...
- Python socket 基础(Server) - Foundations of Python Socket
Python socket 基础 Server - Foundations of Python Socket 通过 python socket 模块建立一个提供 TCP 链接服务的 server 可分 ...
- nethogs-linux程序网络使用情况
netthogs可以显示每个程序的网络传输情况安装nethogs工具yum install https://mirrors.tuna.tsinghua.edu.cn/epel/7/x86_64/Pac ...
- Rust学习--变量
0x0 每种编程语言都有变量的概念,我们可以把变量理解为最简单的存储方式,它是编码过程中是必不可少的. Rust的变量很有特色.变量不可变的特性让人想起了Erlang.以及后面的模式匹配,我觉得作者应 ...
- 同步锁——ReentrantLock
本博客系列是学习并发编程过程中的记录总结.由于文章比较多,写的时间也比较散,所以我整理了个目录贴(传送门),方便查阅. 并发编程系列博客传送门 Lock接口简介 在JUC包下面有一个java.util ...
- Windwos日志分析
Windows日志分析工具 查看系统日志方法: 在“开始”菜单上,依次指向“所有程序”.“管理工具”,然后单击“事件查看器” 按 "Window+R",输入 ”eventvwr.m ...
- idea生成构造方法的快捷键(看这篇就够了)
使用快捷键能加快编写代码的速度和质量 idea生成构造方法的快捷键是Alt+Insert,然后选中Constructor
- 苹果Mac电脑永久路由的添加 & Mac 校园网连接教程
学校校园网面向全校师生开放,无奈Windows用户基数大,学校只为Windows平台制作了内网连接工具,Mac平台资源较少,本人查阅相关资料后,总结整理出以下步骤,方便本校学生连接校园网.有永久路由添 ...
- Eclipse+ADT+Android SDK搭建安卓开发环境
第一步:打开[Android.rar]压缩包,如图所示[评论区回复我,压缩包地址] 第二步:配置环境变量 (1) 解压[android-sdk_r24.4.1-windows.zip]压缩包 (2) ...