urllib模块提供的urlretrieve()函数使用
urllib模块提供的urlretrieve()函数,urlretrieve()方法直接将远程的数据下载到本地
注意:若是网站有反爬虫的话这个函数会返回 403 Forbidden
参数url:传入的网址,网址必须得是个字符串
参数filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
参数reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
参数data:指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
下面例子将表情包下载到本地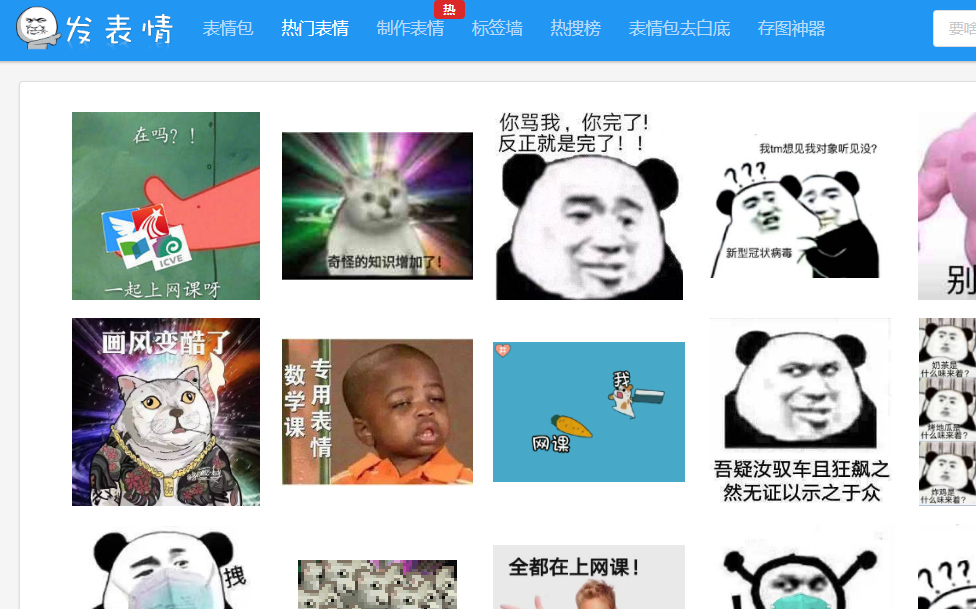
import requests
from lxml import etree
from urllib import request
import os
import re def page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}
res = requests.get(url,headers=headers)
text = res.text
html = etree.HTML(text)
imgs = html.xpath("//div[@class='tagbqppdiv']//img")
for img in imgs:
img_url = img.get('data-original')
alt =img.get('alt')
sufixx = os.path.splitext(img_url)[1]#切割文件后缀名
alt = re.sub(r'[\??\.。\!\!]',"",alt)
filename = alt + sufixx
request.urlretrieve(img_url,r"F:\pacong\hr class\xpath\images\\"+filename)
# print(etree.tostring(img))
# imgs = html.xpath("//div[@class='page-content text-center']//@href")#取出所有href里的链接
#print(text) def main():
for i in range(1,101):
url = 'https://www.fabiaoqing.com/biaoqing/lists/page/%d.html'%i
page(url)
break if __name__ == '__main__':
main()
运行结果:
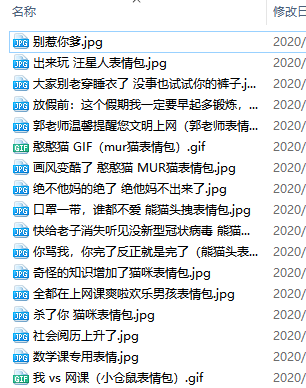
urllib模块提供的urlretrieve()函数使用的更多相关文章
- Python基础之 urllib模块urlopen()与urlretrieve()的使用方法详解。
Python urllib模块urlopen()与urlretrieve()的使用方法详解 1.urlopen()方法urllib.urlopen(url[, data[, proxies]]) ...
- Python urllib模块urlopen()与urlretrieve()详解
1.urlopen()方法urllib.urlopen(url[, data[, proxies]]) :创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据.参数u ...
- Python urllib的urlretrieve()函数解析 (显示下载进度)
#!/usr/bin/python #encoding:utf-8 import urllib import os def Schedule(a,b,c): ''''' a:已经下载的数据块 b:数据 ...
- Python:urllib模块的urlretrieve方法
转于:https://blog.csdn.net/fengzhizi76506/article/details/59229846 博主:fengzhizi76506 1)功能: urllib模块提供的 ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- Python urllib urlretrieve函数解析
Python urllib urlretrieve函数解析 利用urllib.request.urlretrieve函数下载文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 Ur ...
- Python核心模块——urllib模块
现在Python基本入门了,现在开始要进军如何写爬虫了! 先把最基本的urllib模块弄懂吧. urllib模块中的方法 1.urllib.urlopen(url[,data[,proxies]]) ...
- python爬虫-urllib模块
urllib 模块是一个高级的 web 交流库,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如:HTTP.FTP.Gophe ...
- [转]Python核心模块——urllib模块
现在Python基本入门了,现在开始要进军如何写爬虫了! 先把最基本的urllib模块弄懂吧. urllib模块中的方法 1.urllib.urlopen(url[,data[,proxies]]) ...
随机推荐
- Springboot全局事务处理
什么是全局事务 Spring Boot(Spring)事务是通过aop(aop相关术语:通知(Advice).连接点(Joinpoint).切入点(Pointcut).切面(Aspect).目标(Ta ...
- Python3(四) 分支、循环、条件与枚举
表达式 表达式(Expression)是运算符(operator)和操作数(operand)所构成的序列 >>> 1 + 1 2 >>> a = [1 ...
- Postman之命令测试
前言 今天我们来学习一下Postman的命令行测试 1.先安装node.js ,https://nodejs.org/en/#home-downloadhead 2.安装cnpm npm instal ...
- python2 + Django 中文传到模板页面变Unicode乱码问题
1.确保views页面首行设置了默认编码 # -*-coding:utf-8 -*- 2.确保html页面的编码为 utf-8 3.确保项目setting文件设置了 LANGUAGE_CODE = ...
- Java中的合并与重组(上)
通过优锐课核心java学习笔记中,我们可以看到,码了很多专业的相关知识, 分享给大家参考学习. 虽然在Git中合并和重组是相似的,但它们具有两种不同的功能. 要保持自己的历史记录整洁或完整,这是你应该 ...
- RT-Thread can - STM32F103ZET6
SDK版本v4.0.2 目前,RT-Thread Studio还不能够自定义添加can设备.下面介绍手动添加过程: 使用RT-Thread Studio创建一个简单工程 使用RT-Thread env ...
- VMware使用与安装
VMware安装 下载完Vmware -> 双击打开安装包 -> 选择下一步(如下图界面) 选择接受协议,点击下一步 选择经典进行安装.这个是默认安装,会把默认插件安装到相对应的路径 选择 ...
- sql server 基本操作
1输入如下命令,即可通过SQL Server命令行启动.停止或暂停的服务. SQL Server命令行如下: 启动SQL ServerNET START MSSQLSERVER 暂停SQL Serve ...
- Java实体对象为什么要实现Serializable接口?
前言 Java实体对象为什么一定要实现Serializable接口呢?在学JavaSE的时候有些实体对象不实现Serializable不是也没什么影响吗? 最近在学习mybatis的时候发现,老师写的 ...
- VLAN和子网之间的区别与联系
通常来说,子网和VLAN的相似之处在于它们都处理网络的一部分的分段或分区.但是,VLAN是数据链路层(OSI L2)的构造,而子网是网络层(OSI L3)的IP构造,它们解决网络上的不同问题.尽管在V ...