高并发系统:消息队列MQ
注:前提是知道什么是消息队列。不懂的去搜索各种消息队列入门(activeMQ、rabbitMQ、rocketMQ、kafka)
1、为什么要使用MQ?(MQ的好处:解耦、异步、削峰)
(1)解耦:主要解决系统间的耦合度
场景是系统A会产生用户ID:userId,要把userId通过调用系统B\C\D的接口传给他们做业务处理。若添加新系统,也需要此userId,则要再加一个接口调用。耦合严重。
解耦的做法就是:在系统A与系统BCD之间,增加消息队列MQ,系统A产生userId后,将其放入MQ,系统BCD通过监听MQ,来消费userId。
以上,通过MQ,发布和订阅消息的pub/sub模型。
原耦合模型:用户请求--->A---->BCD; 现解耦模型:用户请求---->A--->MQ---->BCD;
(2)异步:主要解决请求的耗时
场景是用户发送请求到系统A,系统A执行完本地SQL(耗时100ms)后,还要调用BCD三个系统的接口,假设三次调用都耗时200ms。那么,总共一次请求耗时700ms。一旦调用接口变多,耗时会变得更长。
使用MQ解决耗时长的办法就是,在系统A与系统BCD之间分别增加MQ,系统A将数据消息写入MQ(耗时5ms),成功就返回并提示用户,剩余的BCD系统自己监听MQ并做相应业务操作。那么,这个请求耗时也就是100+5 = 105ms。
模型跟解耦一样。
(3)削峰:主要解决并发请求百万级时系统挂了
MYSQL处理能力有限,大概最高2000/秒
场景:某秒杀活动,同一时间大量用请求全怼过来了(100万请求),不用MQ的话系统就被打死了(数据库处理不过来了)
模型是: 用户同时的100万请求--->系统A----每秒5000个请求---> mysql
使用MQ:将用户请求先放入MQ,有多少放多少,系统A每次去拿2000个,并请求MySQL资源,系统不会被打死
模型是:用户100万请求--->全写入MQ---> 系统A每次去MQ消费2000条 --->mysql
2、MQ的缺点
(1)系统可用性降低:ABCD四个系统,忽然加一个MQ进来,维护变多,万一忽然挂了,影响下游多系统
(2)系统复杂性升高:怎么保证MQ里的消息没有被重复消费?消息丢失了怎么处理?消息传递的顺序性怎么保证?
(3)一致性问题:异步里面,A处理完直接返回成功了,但是最后一个系统D写入失败了,咋整
3、activeMQ、rabbitMQ、rocketMQ、kafka的区别
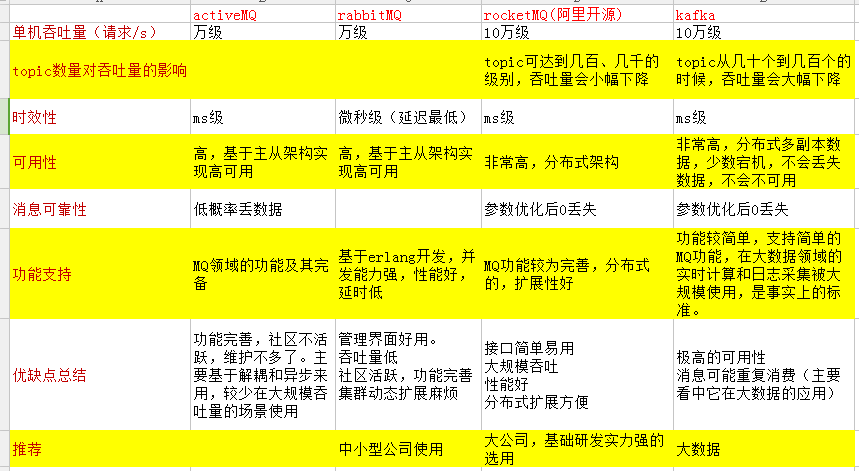
高并发系统:消息队列MQ的更多相关文章
- 大数据高并发系统架构实战方案(LVS负载均衡、Nginx、共享存储、海量数据、队列缓存)
课程简介: 随着互联网的发展,高并发.大数据量的网站要求越来越高.而这些高要求都是基础的技术和细节组合而成的.本课程就从实际案例出发给大家原景重现高并发架构常用技术点及详细演练. 通过该课程的学习,普 ...
- 为什么会需要消息队列(MQ)?
为什么会需要消息队列(MQ)? #################################################################################### ...
- 消息队列一:为什么需要消息队列(MQ)?
为什么会需要消息队列(MQ)? #################################################################################### ...
- 详解RPC远程调用和消息队列MQ的区别
PC(Remote Procedure Call)远程过程调用,主要解决远程通信间的问题,不需要了解底层网络的通信机制. RPC框架 知名度较高的有Thrift(FB的).dubbo(阿里的). RP ...
- 消息队列 MQ 入门理解
功能特性: 应用场景: 消息队列 MQ 可应用于如下几个场景: 分布式事务 在传统的事务处理中,多个系统之间的交互耦合到一个事务中,响应时间长,影响系统可用性.引入分布式事务消息,交易系统和消息队列之 ...
- 消息队列mq总结(重点看,比较了主流消息队列框架)
转自:http://blog.csdn.net/konglongaa/article/details/52208273 http://blog.csdn.net/oMaverick1/article/ ...
- 消息队列MQ简介
项目中要用到RabbitMQ,领导让我先了解一下.在之前的公司中,用到过消息队列MQ,阿里的那款RocketMQ,当时公司也做了简单的技术分享,自己也看了一些博客.自己在有道云笔记上,做了一些整理,但 ...
- 消息队列mq总结
一.消息队列概述消息队列中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构.目前使用较多的消息队列有ActiveMQ,RabbitM ...
- java面试记录三:hashmap、hashtable、concurrentHashmap、ArrayList、linkedList、linkedHashmap、Object类的12个成员方法、消息队列MQ的种类
口述题 1.HashMap的原理?(数组+单向链表.put.get.size方法) 非线程安全:(1)hash冲突:多线程某一时刻同时操作hashmap并执行put操作时,可能会产两个key的hash ...
随机推荐
- Go语言中的单例模式(翻译)
在过去的几年中,Go语言的发展是惊人的,并且吸引了很多由其他语言(Python.PHP.Ruby)转向Go语言的跨语言学习者. Go语言太容易实现并发了,以至于它在很多地方被不正确的使用了. Go语言 ...
- 使用Apache服务器实现Nginx反向代理
实验环境:centos7 注:因为本次实验在同一台服务器上,Apache与Nginx同为80端口,所以改Apache端口为60 1 配置Nginx服务器: 编辑Nginx配置文件,写入以下内容 loc ...
- 谈python3的封装
这章给大家介绍,如何封装一个简单的python库 首先创建一个以下型式的文件结构 rootFile/ setup.py example_package/ __init__.py example_mod ...
- for和while——python中的循环控制语句详解
循环语句在绝大多数的语言中,都是必不可少的一种控制语句,循环语句允许我们执行一个语句或语句组多次.在python中有for循环和while循环两种,讲到这里,就不得不提到我们的迭代器对象 迭代器 迭代 ...
- 2020-02-20Linux学习日记,第二天
在内容开始前请教一下博客园的大佬.编辑器中没有看到格式刷,要怎么不连续的选中内容给予想要的格式,有看到的麻烦私信解答一下,谢谢! ----------------------------------- ...
- C++ 日期 & 时间(转)
C++ 标准库没有提供所谓的日期类型.C++ 继承了 C 语言用于日期和时间操作的结构和函数. 为了使用日期和时间相关的函数和结构,需要在 C++ 程序中引用 头文件.有四个与时间相关的类型:cloc ...
- C++括号匹配检测(用栈)
输入一串括号,包括圆括号和方括号,()[],判断是否匹配,即([]())或[([][])]为匹配的正确的格式,[(])或([())为不匹配的格式. #include<iostream> # ...
- 排查 Kubernetes HPA 通过 Prometheus 获取不到 http_requests 指标的问题
部署好了 kube-prometheus 与 k8s-prometheus-adapter (详见之前的博文 k8s 安装 prometheus 过程记录),使用下面的配置文件部署 HPA(Horiz ...
- Cacti被监控机器 配置 snmp协议
SNMP(Simple Network Management Protocol,简单网络管理协议)的前身是简单网关监控协议(SGMP),用来对通信线路进行管理. snmpd.conf的 ...
- Laravel + Serverless Framework 快速创建 CMS 内容管理系统
今天,为大家带来一篇 Laravel + Serverless Framework 的综合实战,里面信息量有点多,大家仔细看哦- 首先,我来介绍下主要的本地环境吧: Git:不多说,只要会敲代码就应该 ...