Hadoop学习2—伪分布式环境搭建
一、准备虚拟环境
1. 虚拟环境网络设置
A、安装VMware软件并安装linux环境,本人安装的是CentOS
B、安装好虚拟机后,打开网络和共享中心 -> 更改适配器设置 -> 右键VMnet8 -> 属性。设置IPv4,设置如下:
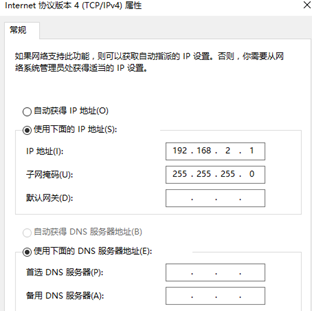
C、在创建好的虚拟机上点击网络设置,选择自定义并设置成“VMnet8(NAT)”如下图所示:

D、修改VMware软件网络设置,设置方式如下所示:

2. 修改主机名
命令:vi /etc/sysconfig/network
将内容修改为
NETWORKING=yes
HOSTNAME=hadoop1-#hostname为主机名,可根据情况修改
3. 修改IP地址
修改配置文件:
vi /etc/sysconfig/network-scripts/ifcfg-eth0
修改其中
IPADDR=192.168.2.110(具体IP地址根据情况修改)
4.防火墙
将防火墙关闭或者将需要对外的端口加到防火墙中,常用的防火墙命令:
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
设置完成后需要重启linux,命令:reboot
5.linux设置无密钥登录
之前对无密钥登录专门做过讲解,有兴趣的同学可以参考:Linux配置SSH免登陆
二、安装JDK
1.上传jdk软件包并解压
创建文件夹:mkdir /home/hadoop/app
解压:tar xf jdk-7u55-linux-i586.tar.gz -C /home/hadoop/app
2.将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585
export PATH=$PATH:$JAVA_HOME/bin
3.刷新环境变量配置
source /etc/profile
三、 安装hadoop2.4.1
1、上传安装包并解压
上传hadoop的安装包到服务器上去/home/hadoop/并解压,
解压命令:tar xf hadoop-2.4.1.tar.gz -C /home/hadoop/app/
2、配置hadoop配置文件,伪分布式需要修改5个配置文件
A、hadoop-env.sh,修改JAVA_HOME路径
vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1..0_65
B、core-site.xml
<!-- 指定HADOOP所使用的文件系统URI,NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.2.170:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.4./tmp</value>
</property>
C、hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>
D、mapred-site.xml
hadoop安装路径中配置文件叫mapred-site.xml.template,需要将其修改成mapred-site.xml。
修改文件名命令:
mv mapred-site.xml.template mapred-site.xml
将配置文件内容修改如下:
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
E、yarn-site.xml
<configuration>
<!-- 指定YARN的ResourceManager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.2.170</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3、将hadoop添加到环境变量
vim /etc/proflie
export JAVA_HOME=/usr/java/jdk1..0_65
export HADOOP_HOME=/itcast/hadoop-2.4.
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
修改完成之后刷新环境变量配置文件:source /etc/profile
4、初始化namenode
初始化命令:
hdfs namenode -format
5、启动hadoop
#先启动HDFS
start-dfs.sh
#再启动YARN
start-yarn.sh
6、验证是否启动成功
a、使用jps命令验证
5983 Jps
NameNode
ResourceManager
DataNode
NodeManager
SecondaryNameNode
b、登陆管理
HDFS管理界面:http://192.168.2.170:50070

MR管理界面:http://192.168.2.170:8088
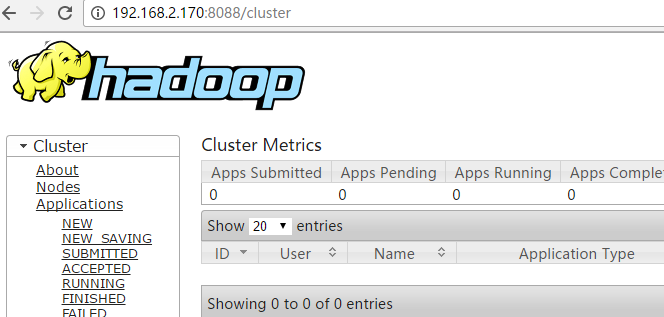
c、简单hadoop命令测试
[hadoop@hadoop1- hadoop]$ hadoop fs -mkdir /test
[hadoop@hadoop1- hadoop]$ hadoop fs -ls /
Found items
drwxr-xr-x - hadoop supergroup -- : /test
Hadoop学习2—伪分布式环境搭建的更多相关文章
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Hadoop 2.7 伪分布式环境搭建
1.安装环境 ①.一台Linux CentOS6.7 系统 hostname ipaddress subnet mask ...
- Hadoop学习笔记1:伪分布式环境搭建
在搭建Hadoop环境之前,请先阅读如下博文,把搭建Hadoop环境之前的准备工作做好,博文如下: 1.CentOS 6.7下安装JDK , 地址: http://blog.csdn.net/yule ...
- 【Hadoop】伪分布式环境搭建、验证
Hadoop伪分布式环境搭建: 自动部署脚本: #!/bin/bash set -eux export APP_PATH=/opt/applications export APP_NAME=Ares ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
- hive-2.2.0 伪分布式环境搭建
一,实验环境: 1, ubuntu server 16.04 2, jdk,1.8 3, hadoop 2.7.4 伪分布式环境或者集群模式 4, apache-hive-2.2.0-bin.tar. ...
随机推荐
- TNS-12545: Connect failed because target host or object does not exist
问题描述 $ lsnrctl startLSNRCTL for Linux: Version 12.1.0.2.0 - Production on 26-JUL-2017 09:53:42Copyri ...
- AcWing 8.二维费用的背包问题
#include<iostream> #include<algorithm> #include<cstring> using namespace std ; ; i ...
- 小匠第一周期打卡笔记-Task01
一.线性回归 知识点记录 线性回归输出是一个连续值,因此适用于回归问题.如预测房屋价格.气温.销售额等连续值的问题.是单层神经网络. 线性判别模型 判别模型 性质:建模预测变量和观测变量之间的关系,亦 ...
- 使用Samba实现文件共享:Windows和Linux之间
1.概述: 1987 年,微软公司和英特尔公司共同制定了 SMB(Server Messages Block,服务器消息 块)协议,旨在解决局域网内的文件或打印机等资源的共享问题,这也使得在多个主机之 ...
- 在手机浏览器中判断App是否已安装
从网上搜到之前手机中判断App是否安装可以通过onblur事件+定时器来实现. 但现在要做这个功能时,按网上的说法已经不能实现了.因为现在浏览器中打开App,window不会触发onblur事件. 在 ...
- EAC3 enhanced channel coupling
Enhanced channel coupling是一种spatial coding 技术,在传统的channel coupling的基础上添加了phase compensation, de-corr ...
- Eqaulize Prices
There are n products in the shop. The price of the ii-th product is aiai. The owner of the shop want ...
- idea中使用Data Source and Drivers时,如果使用自己自定义的jar包
- 【转载】Java容器的线程安全
转自:http://blog.csdn.net/huilangeliuxin/article/details/12615507 同步容器类 同步容器类包括Vector和Hashtable(二者是早期J ...
- navicat导入.csv表格
我本地的navicat不知道啥情况,导入不了表格,然后把表格转为.csv的,然后导入就好了 1.表格另存为.csv格式的 2.打开Navicat,选择要导入的表,然后右键->导入向导,选择.cs ...